SQL Server Infernals – Circle 5: Inconsistent Baptists

There’s a place in the SQL Server hell where you can find poor souls wandering the paths of their circle, shouting nonsense table names or system-generated constraint names, trying to baptize everything they find on their way in a different manner. They might seem innocuous at a first glance, but beware those damned souls, as they can raise confusion and endanger performance.
What they say in Heaven
Guided by the Intelligent Designer’s hands, database architects in Heaven always name their tables, columns and all database objects following the rules in the ISO 11179 standard. However, standards aside, the most important thing they do is adhere to a single naming convention, so that every angelic DBA and developer can sing in the same language.
It has to be said that even in Heaven some angels prefer specific naming conventions and some other angels might prefer different ones (say plural or singular table names), but as soon as they start to design a database, every disagreement magically disappears and they all sing in harmony.
Damnation by namification
Some naming conventions are better than others, but many times it all comes down to personal preference. It’s a highly debatable subject and I will refrain from posting here what my preference is. If you want to learn more about naming conventions, take advice from one of the masters.
That said, some naming conventions are really bad and adopting them is a one way ticket to the SQL Server hell:
- Hungarian Notation: my friends in Hungary will forgive me if I say that their notation doesn’t play well with database objects. In fact, the Hungarian Notation was conceived in order to overcome the lack of proper data types in the BCPL language, putting a metadata prefix in each variable name. For instance, a variable holding a string would carry the “str” prefix, while a variable holding a long integer would carry the “l” prefix.
SQL Server (and all modern relational databases) have proper data type support and all sorts of metadata discovery features, so there is no point in naming a table “tbl_customer” or a view “vwSales”. Moreover, if the DBA decides to break a table in two and expose its previous structure as a view (in order to prevent breaking existing code), having the “tbl” prefix in the view name completely defeats the purpose of identifying the object type by its prefix.
Next time you’re tempted to use the Hungarian Notation ask yourself: “is my name John or DBA_John?”
Hungary is a nice str_country.
- Using insanely short object names: Some legacy databases (yes, you, DB2/400) used to have a hard maximum of 10 characters for object names. It wasn’t uncommon to see table names such as “VN30SKF0OF” or “PRB10SPE4F”: good luck figuring out what those tables represented!
Fortunately, those days are gone and today there is no single reason to use alphabet soup names for your objects. The object name is a contract between the object and its contents and it should be immediately clear what the contents are by just glancing at the name.
- Using insanely long object names: On the other hand, table names such as “ThisIsTheViewThatContainsOrdersWhichAreYetToBeShipped” adds nothing to clarity of the schema. “UnshippedOrders” will do just as well.
- Mixing Languages: if you’re fortunate enough to be a native English speaker, you have no idea what this means. In countries such as Italy or Spain, this is a real issue. Many people may end up designing different parts the database schema and each designer may be inclined to use English (the lingua franca of Information Technology) or his/her first language. Needless to say that the result is a mess.
- Using the “sp_” prefix for stored procedures: it’s a special case of Hungarian Notation, with severe performance implications. In his blog, Aaron Bertrand discussed the notorious negative impact of the “sp_” prefix, offering a performance comparison with charts and crunchy numbers.
TL;DR version: SQL Server looks up objects with the sp_ prefix in the master database first, then in the user database. While it may look like a negligible performance issue, it can explode at scale.
- Using reserved keywords or illegal characters: While it’s still possible to include almost anything inside square brackets, the use of spaces, quotes or any other illegal character is a totally unneeded masochistic habit. Reserved keywords may also add a thrilling touch of insane confusion to your T-SQL code:
SELECT * FROM [TRUNCATE] [TABLE]
Enough said.
- Using system-generated names for constraints, indexes and so on: When you don’t name your constraints and indexes explicitly, SQL Server is kind enough as to do it for you, using a semi-random system-generated name. That’s great! Uh, wait a moment: this means that two databases deployed to two different instances will contains the same index with a different name, making all your deployment scripts nearly useless. Do yourself a favor and take the time to name all your objects explicitly.
- No naming convention or multiple, inconsistent naming conventions: The worst of all mistakes is having multiple naming conventions, or no naming convention at all (which is equal to “as many naming conventions as objects in the database”). Naming conventions is a sort of religious subject and there are multiple valid reasons to adopt one or another: the only thing you should absolutely avoid is turning your database into a sort of Babel tower, where multiple different languages are spoken and nobody understands what the others say.
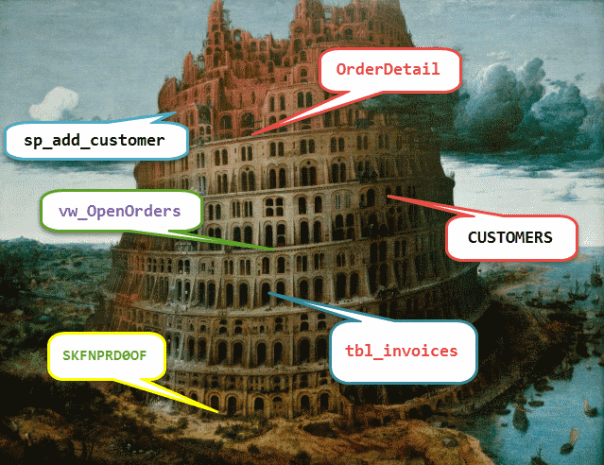

This is the last circle of SQL Server hell dedicated to Database Design sins: in the next episode of SQL Server Infernals we will venture into the first circle dedicated to development. Stay tuned!
Posted on July 17, 2015, in SQL Server, SQL Server Infernals and tagged Database Design, Naming Conventions, SQL Server, SQL Server Infernals, Worst Practices. Bookmark the permalink. 8 Comments.

Looks like repentance is in order. Excellent post!
very fun! Always a timely subject
Interesting that you chose “tibbling” as the first sin. I admit I used to go back and forth about this; but have you ever considered the lift in terms of increasing the quality of hits when crawling code? Or in other words, how tibbling reduces spurious hits. I’m convinced that for this reason alone tibbling is the way to go, though I never see anyone bring this point up.
We have many ways to identify the object type from the metadata that adding more metadata in the object name itself is a waste of time and a source of confusion. In SSMS you can install the SSMSBoost add-in to simply hit F2 and have the object definition scripted in a new query editor window, or right click an object and select “Locate object in Object Explorer”. No, really: we don’t need metadata in the object name.
As a Hungarian, I totally agree with you that Hungarian notation is not for database development 🙂
Ha! I had no doubt about it, Janos! BTW, can you confirm that Hungary is a beautiful str_Country? 🙂
hahaha, it is :))))
Thannks for the post