Monthly Archives: January 2015
Installing multiple default instances on a single server
As you probably know, SQL Server allows only one default instance per server. The reason is not actually something special to SQL Server, but it has to do with the way TCP/IP endpoints work.
In fact, a SQL Server default instance is nothing special compared to a named instance: it has a specific instance id (MSSQLSERVER) and listens on a well-known TCP port (1433), but it has no other intrinsic property or feature that makes it different from any other instance.
Let’s look closely to these properties: the instance id is specific to a SQL Server instance and it has to be unique. In this regard, MSSQLSERVER makes no exception. Similarly, a TCP endpoint must be unique and there can be only one socket listening on a specific endpoint.
Nevertheless, I will show you a way to have multiple “default” instances installed on the same server, even if it might look impossible at a first look.
Install two instances of SQL Server
First of all, you need to have two (or more) instances installed on your server. In this example I will use the server “FANGIO” and I will install two named instances: INST01 and INST02.
Here’s what my Configuration Manager looks like once the two instances are ready:

In this case I used two named instances, but it would have worked even if I used a default instance and a named instance. Remember? Default instances are nothing special.
Provision IP addresses
Each SQL Server instance must listen on a different TCP endpoint, but this does not mean that each instance has to listen on a different port: a TCP endpoint is made of an IP address and a port. This means that two instances can listen on the same port, as long as the IP addresses are different.
In this case, you just need to add a new IP address to the server, one for each SQL Server instance that you want to listen on port 1433.

Configure network protocols
Now that you have multiple IP addresses, you just have to tell SQL Server to listen on that specific address, port 1433.
Open the Configuration Manager and enable TCP/IP:

Now open the properties applet and disable “Listen All”:

In the IP Addresses tab, configure the IP address and the port:

In this case I enabled the address 10.0.1.101 for INST01 and I disabled all the remaining addresses. For INST02 I enabled 10.0.1.102.
Configure DNS
Now the server has two IP addresses and they both resolve to its network name (FANGIO). In order to let clients connect to the appropriate SQL Server instance, you need to create two separate “A” records in DNS to resolve to each IP address.
In this case I don’t have a DNS server (it’s my home lab) so I will use the hosts file:

Final Setup
Now the example setup looks like this:
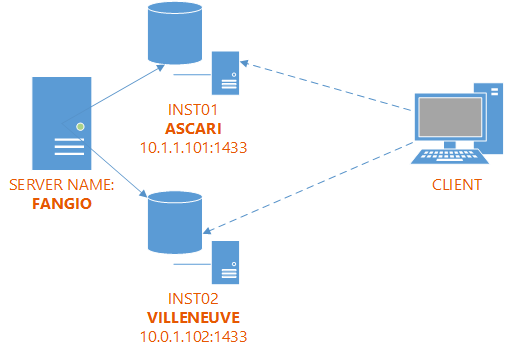
When a client connects to the default instance on ASCARI, it is connecting to FANGIO\INST01 instead. Similarly, the default instance on VILLENEUVE corresponds to FANGIO\INST02.

Why would I want to do this?
If you had only default instances in your servers, moving databases around for maintenances, upgrades or consolidations would be just a matter of adding a CNAME to your DNS.
With named instances, the only way to redirect connections to a different server is by using a SQLClient alias. Unfortunately, aliases are client-side settings and have to be deployed to each and every client in order to work. Group policies can deploy aliases to multiple machines at once, but policies are not evaluated immediately, while a DNS entry can propagate very quickly.
Another reason to use this setup is the ability to bypass the SQLBrowser: when a named instance is specified, the client has to contact the SQLBrowser service on port 1434 with a small UDP datagram and receive back the list of instances, along with the port they’re listening on. When the default instance is specified, there is no need to contact the SQLBrowser, because we already know the port it is listening on (it’s 1433, unless it has been changed).
Sometimes the firewall settings for SQLBrowser are tricky to set up, especially with clusters. Another thing I recently discovered is that SQLBrower allows attackers to create huge DDOS attacks using a 440x amplification factor.
Security concerns
Some setup guides recommend that you change the port SQL Server listens on to something different from 1433, which is a well-known port, more likely to be discovered by attackers. I think that an attacker skilled enough to penetrate your server needs much more resistance than just “hiding” your instance to a non-default port. A quick port scan would immediately reveal any SQL Server instance listening on any port, so this is really a moot point in my opinion.
Bottom line
SQL Server allows only one default instance to be installed on a machine, but with a few simple steps every instance can be made a “default” instance. The main advantage of such a setup is the ability to redirect client connections to a database instance with a simple change in the DNS configuration.
The big disconnect with Connect
![]() A couple of years ago I blogged about a bug on the Data Collector that I couldn’t resolve but with an ugly workaround. At the end of that post, I stated that I wouldn’t have bothered filing the bug on Connect, due to prior discouraging results. Well, despite what I wrote there, I took the time to open a bug on Connect (the item can be found here), which was promptly closed as “won’t fix”.
A couple of years ago I blogged about a bug on the Data Collector that I couldn’t resolve but with an ugly workaround. At the end of that post, I stated that I wouldn’t have bothered filing the bug on Connect, due to prior discouraging results. Well, despite what I wrote there, I took the time to open a bug on Connect (the item can be found here), which was promptly closed as “won’t fix”.
Nothing new under the sun: “won’t fix” is the most likely answer on Connect, no matter how well you document your issue and how easy is the bug to reproduce. I really am sorry to say that, but it’s a widespread feeling that Connect has become totally pointless, if it ever had a point. The common feeling about Connect is that bugs are usually closed as “won’t fix” or “by design” without any further communication, while suggestions are completely disregarded.
How did we get here? Why is Microsoft spending money on a service that generates frustration on users? Where does this idiosyncrasy come from?
If I had to give Microsoft advice on how to improve Connect, I would focus on one simple point:
Improve feedback
One of the things I see over and over on Connect is the lack of communication between users and support engineers. Once the item is closed, it’s closed (with few notable exceptions). You can ask for more information, add details to the item, do anything you can think of, but the engineers will stop responding. Period.
This means that there is no way to steer the engineer’s understanding of the bug: if (s)he read it wrong, (s)he won’t read it again.
I can understand that anybody with a Microsoft account can create bugs on Connect without having to pay for the time spent on the problem by the engineers: this can easily lead to a very low signal/noise rate, which is not sustainable. In other words, the support engineers seem to be flooded by an overwhelming amount of inaccurate submissions, which makes mining for noteworthy bugs an equally overwhelming task.
However, I think that the current workflow for closing bugs is too abrupt and a more reasonable workflow would at least require responding to the first comment received after the item is marked for closure.
How is CSS different?
In this particular case, I decided to conduct a small experiment and I opened the same exact bug with CSS. Needless to say that the outcome was totally different.
The bug was recognized as a bug, but this is not the main point: the biggest difference was the amount and the quality of communication with the support engineer. When you file a bug with CSS, a support engineer is assigned to your case and you can communicate with him/her directly by email. If the engineer needs more information on the case, (s)he will probably call you on the phone and ask for clarification. In our case, we also have a TAM (Technical Account Manager) that gets CC’ed to all emails between us and CSS.
Where does the difference lay? Just one: money.
If you want to contact the CSS, you have to pay for support. If the bug turns out to be a documented behavior instead, you pay for the time spent by the engineers working on it. This is totally absent from Connect, where everyone can file bugs without having to pay attention to what they do: there will be nothing to pay at the end of the day.
Is Connect really pointless?
One thing I discovered with my experiment may surprise you: CSS reads Connect items and if there is one matching your case, they will take it into account. This is really good news in my opinion and sheds a totally new light over Connect.
Another thing I discovered is that there is much more information behind a Connect item than it’s visible to users. When the engineers process items, they produce comments that are attached to the different workflow steps involved in the triage. Unfortunately, this is invisible to the end users, that are left with the minimal information that the engineers decide to share.
However, the important lesson learned from this experiment is that Connect may be frustrating for end users, but it is far from pointless: the information gathered while triaging bugs contributes to the quality of the paid support and, ultimately, to the quality of SQL Server itself. What still is unsatisfactory is the feedback to Connect users, that are getting more and more discouraged to file new items.
An appeal to Microsoft
Dear Microsoft, please, please, please improve the feedback on Connect: more feedback means less frustration for users that submit legitimate and reasonable bugs. Less frustration means more sensible feedback from your users, which in turn helps your CSS and improves the quality of SQL Server. Not everybody can open cases with CSS: this doesn’t mean that they are not contributing positevely to your product (and you know it), so please reward them with a better communication.
I’m an MVP: now what?
 Today when I checked my mailbox I found an amazing surprise: I joined the ranks of the Most Valuable Professionals for SQL Server!
Today when I checked my mailbox I found an amazing surprise: I joined the ranks of the Most Valuable Professionals for SQL Server!
I am honoured to join a community of people that I highly respect and have always been my inspiration. The MVPs I had the pleasure to meet are a model to strive for: exceptional technical experts and great community leaders that devote their own time to spread their knowledge. I have never considered myself nearly as good as those exceptional people and receiving this award means that now I have to live up to the overwhelming expectations that it sets.
So, now what?
This award maybe means that I’m on the right track. I will continue to help the community with my contribution, hoping that somebody find it useful in the journey with SQL Server. I will continue to spread whatever I know about SQL Server and all the technologies around it with my blog posts, my articles and my forum answers. I will continue to speak at conferences, SQL Saturdays and technology events around me.
The award opens new possibilities and new ways to contribute and I won’t miss the opportunity to do more!
I am really grateful to those who made it happen, in particular the exceptional people at sqlservercentral.com, where my journey with the SQL Server community began many years ago.
A huge thank you goes also to the Italian #sqlfamily that introduced me to speaking at SQL Server events.
And now, let’s rock this 2015!
