Category Archives: SQL Server Central
How to post a T-SQL question on a public forum
If you want to have faster turnaround on your forum questions, you will need to provide enough information to the forum users in order to answer your question.
In particular, talking about T-SQL questions, there are three things that your question must include:
- Table scripts
- Sample data
- Expected output
Table Script and Sample data
Please make sure that anyone trying to answer your question can quickly work on the same data set you’re working on, or, at least the problematic part of it. The data should be in the same place where you have it, which is inside your tables.
You will have to provide a script that creates your table and inserts data inside that table.
Converting your data to INSERT statements can be tedious: fortunately, some tools can do it for you.
How do you convert a SSMS results grid, a CSV file or an Excel spreadsheet to INSERT statements? In other words, how do you convert this…

into this?
USE [tempdb] GO CREATE TABLE [dbo].[Person]( [BusinessEntityID] [int] NOT NULL PRIMARY KEY CLUSTERED, [PersonType] [nchar](2) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL ) GO INSERT INTO Person VALUES (6106,'IN','Beth','Carlson'); INSERT INTO Person VALUES (17889,'IN','Dennis','Li'); INSERT INTO Person VALUES (17989,'IN','Brent','Li'); INSERT INTO Person VALUES (9424,'IN','Brad','Raji'); INSERT INTO Person VALUES (5842,'IN','Aimee','She'); INSERT INTO Person VALUES (2144,'GC','Carol','Philips'); INSERT INTO Person VALUES (2582,'IN','Gregory','Tang'); INSERT INTO Person VALUES (2012,'SC','Jian','Wang'); INSERT INTO Person VALUES (12624,'IN','Clayton','She'); INSERT INTO Person VALUES (12509,'IN','Madison','Russell'); GO
The easiest way to perform the transformation is to copy all the data and paste it over at ConvertCSV:
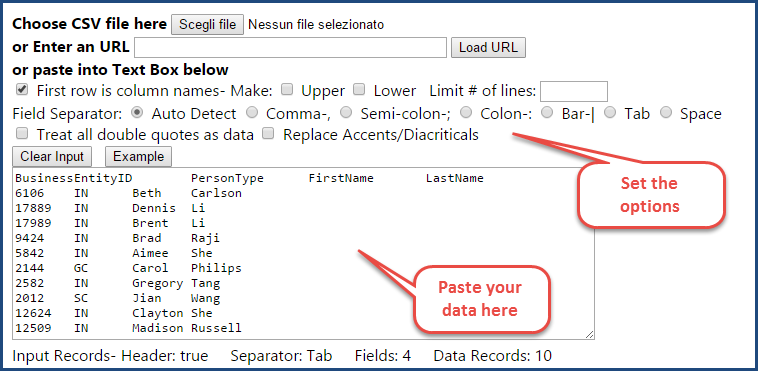


Another great tool for this task is SQLFiddle.
OPTIONAL: The insert statements will include the field names: if you want to make your code more concise, you can remove that part by selecting the column names with your mouse holding the ALT key and then delete the selection. Here’s a description of how the rectangular selection works in SSMS 2012 and 2014 (doesn’t work in SSMS 2008).
Expected output
The expected output should be something immediately readable and understandable. There’s another tool that can help you obtain it.
Go to https://ozh.github.io/ascii-tables/, paste your data in the “Input” textarea, press “Create Table” and grab your table from the “Output” textarea.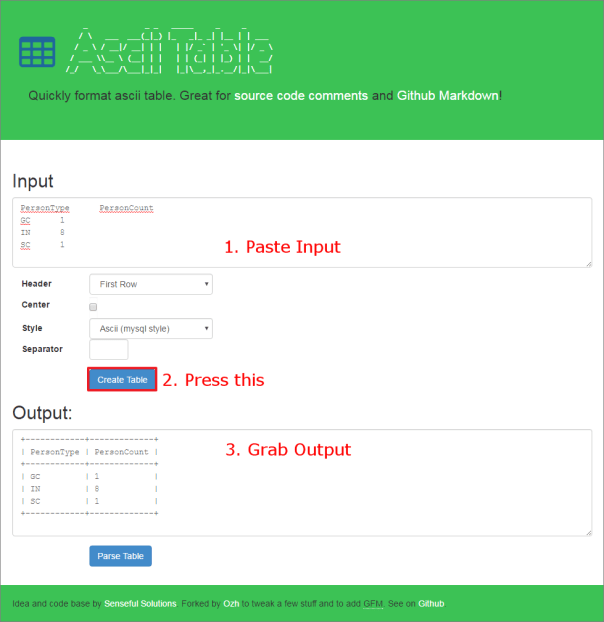 Here’s what your output should look like:
Here’s what your output should look like:
+------------+-------------+ | PersonType | PersonCount | +------------+-------------+ | GC | 1 | | IN | 8 | | SC | 1 | +------------+-------------+
Show what you have tried
Everybody will be more willing to help you if you show that you have put some effort into solving your problem. If you have a query, include it, even if it doesn’t do exactly what you’re after.
Please please please, format your query before posting! You can format your queries online for free at PoorSQL.com
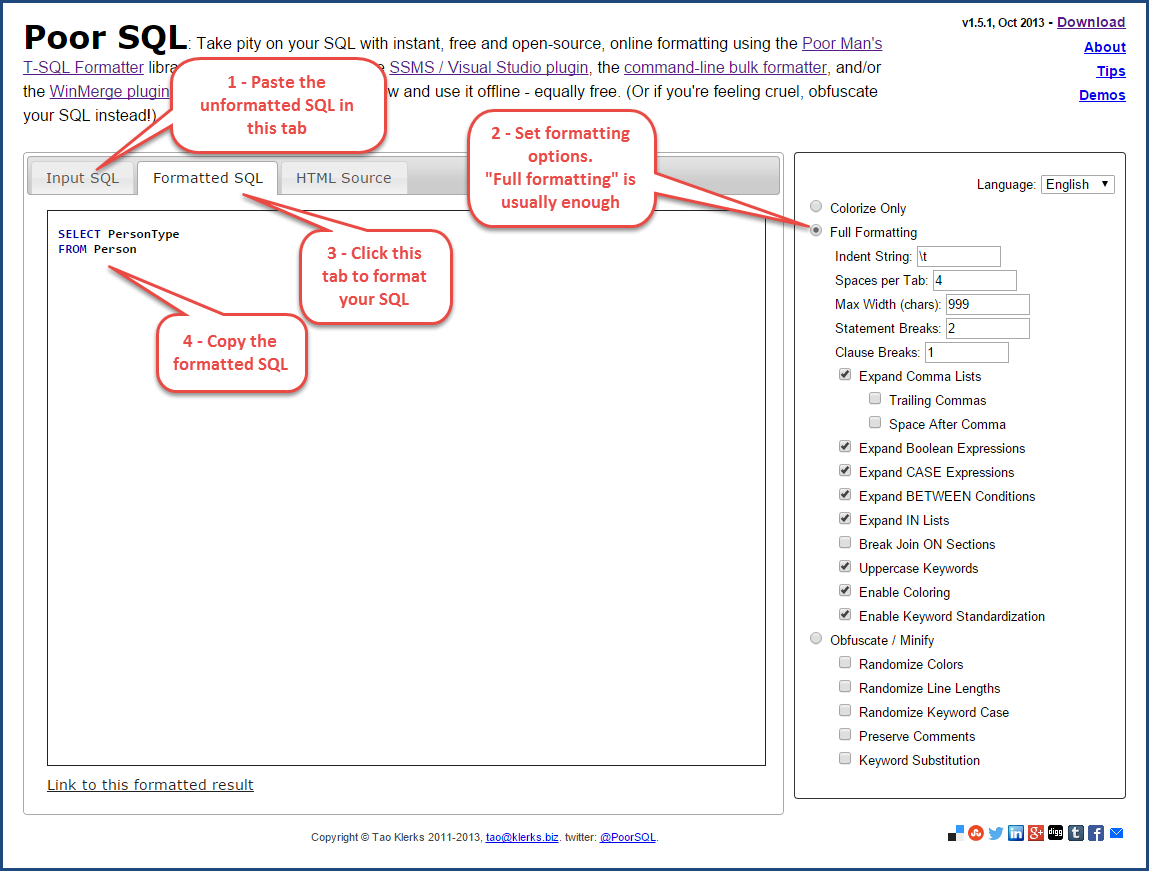
Simply paste your code then open the “Formatted SQL” tab to grab your code in a more readable way.
Putting it all together
Here is what your question should look like when everything is ok:
Hi all, I have a table called Person and I have to extract the number of rows for each person type.
This is the table script and some sample data:
USE [tempdb] GO CREATE TABLE [dbo].[Person]( [BusinessEntityID] [int] NOT NULL PRIMARY KEY CLUSTERED, [PersonType] [nchar](2) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL ) GO INSERT INTO Person VALUES (6106,'IN','Beth','Carlson'); INSERT INTO Person VALUES (17889,'IN','Dennis','Li'); INSERT INTO Person VALUES (17989,'IN','Brent','Li'); INSERT INTO Person VALUES (9424,'IN','Brad','Raji'); INSERT INTO Person VALUES (5842,'IN','Aimee','She'); INSERT INTO Person VALUES (2144,'GC','Carol','Philips'); INSERT INTO Person VALUES (2582,'IN','Gregory','Tang'); INSERT INTO Person VALUES (2012,'SC','Jian','Wang'); INSERT INTO Person VALUES (12624,'IN','Clayton','She'); INSERT INTO Person VALUES (12509,'IN','Madison','Russell');This is what I’m trying to obtain:
+------------+-------------+ | PersonType | PersonCount | +------------+-------------+ | GC | 1 | | IN | 8 | | SC | 1 | +------------+-------------+Here is what I have tried:
SELECT PersonType FROM PersonHow do I do that?
If you include this information in your posts, I promise you will get blazingly fast answers.
SQL Server and Custom Date Formats
Today SQL Server Central is featuring my article Dealing with custom date formats in T-SQL.

There’s a lot of code on that page and I thought that making it available for download would make it easier to play with.
You can download the code from this page or from the Code Repository.
- CustomDateFormat.cs
- formatDate_Islands_iTVF.sql
- formatDate_Recursive_iTVF.sql
- formatDate_scalarUDF.sql
- parseDate_Islands_iTVF.sql

I hope you enjoy reading the article as much as I enjoyed writing it.
Concatenating multiple columns across rows
Today I ran into an interesting question on the forums at SQLServerCentral and I decided to share the solution I provided, because it was fun to code and, hopefully, useful for some of you.
Many experienced T-SQL coders make use of FOR XML PATH(‘’) to build concatenated strings from multiple rows. It’s a nice technique and pretty simple to use.
For instance, if you want to create a list of databases in a single concatenated string, you can run this statement:
SELECT CAST((
SELECT name + ',' AS [text()]
FROM sys.databases
ORDER BY name
FOR XML PATH('')
) AS varchar(max))
The SELECT statement produces this result:
allDBs ------------------------------------------------------------------ BROKEN,LightHouse,master,model,msdb,tempdb,TEST,test80,TOOLS,WORK,
Great! But, what if you had to concatenate multiple columns at the same time? It’s an unusual requirement, but not an impossible one.
Let’s consider this example:
-- =================================
-- Create a sentences table
-- =================================
DECLARE @Sentences TABLE (
sentence_id int PRIMARY KEY CLUSTERED,
sentence_description varchar(50)
)
-- =================================
-- Sentences are broken into rows
-- =================================
DECLARE @Rows TABLE (
sentence_id int,
row_id int,
Latin varchar(500),
English varchar(500),
Italian varchar(500)
)
-- =================================
-- Create three sentences
-- =================================
INSERT INTO @Sentences VALUES(1,'First sentence.')
INSERT INTO @Sentences VALUES(2,'Second Sentence')
INSERT INTO @Sentences VALUES(3,'Third sentence')
-- =================================
-- Create sentences rows from
-- "De Finibus bonorum et malorum"
-- by Cicero, AKA "Lorem Ipsum"
-- =================================
INSERT INTO @Rows VALUES(1, 1,
'Neque porro quisquam est,',
'Nor again is there anyone who',
'Viceversa non vi è nessuno che ama,')
INSERT INTO @Rows VALUES(1, 2,
'qui dolorem ipsum quia dolor sit amet,',
'loves or pursues or desires to obtain pain',
'insegue, vuol raggiungere il dolore in sé')
INSERT INTO @Rows VALUES(1, 3,
'consectetur, adipisci velit, sed quia non numquam',
'of itself, because it is pain, but because occasionally',
'perché è dolore ma perché talvolta')
INSERT INTO @Rows VALUES(1, 3,
'eius modi tempora incidunt',
'circumstances occur in which',
'capitano circostanze tali per cui')
INSERT INTO @Rows VALUES(1, 3,
'ut labore et dolore magnam aliquam quaerat voluptatem.',
'toil and pain can procure him some great pleasure.',
'con il travaglio e il dolore si cerca qualche grande piacere.')
INSERT INTO @Rows VALUES(2, 1,
'Ut enim ad minima veniam,',
'To take a trivial example,',
'Per venire a casi di minima importanza,')
INSERT INTO @Rows VALUES(2, 2,
'quis nostrum exercitationem ullam corporis suscipit laboriosam,',
'which of us ever undertakes laborious physical exercise,',
'chi di noi intraprende un esercizio fisico faticoso')
INSERT INTO @Rows VALUES(2, 3,
'nisi ut aliquid ex ea commodi consequatur?',
'except to obtain some advantage from it?',
'se non per ottenere da esso qualche vantaggio?')
INSERT INTO @Rows VALUES(3, 1,
'Quis autem vel eum iure reprehenderit qui in ea voluptate',
'But who has any right to find fault with a man who chooses to enjoy a pleasure',
'O chi può biasimare colui che decide di provare un piacere')
INSERT INTO @Rows VALUES(3, 2,
'velit esse quam nihil molestiae consequatur,',
'that has no annoying consequences,',
'che non porta conseguenze negative,')
INSERT INTO @Rows VALUES(3, 3,
'vel illum qui dolorem eum fugiat quo voluptas nulla pariatur?',
'or one who avoids a pain that produces no resultant pleasure?',
'o che fugge quel dolore che non produce nessun piacere?')
The setup code creates two tables: Sentences and Rows. The first one is the master table, that contains the sentence_id and a description. The second one contains the actual sentences, broken into rows and organized with languages in columns.
For the purposes of this test, I inserted in the Rows table an excerpt of Cicero’s “De Finibus bonorum et malorum”, also known as “Lorem Ipsum”, the printing and typesetting industry’s standard dummy text since the 1500s.
Here’s how the input data looks like:

What we want to do is concatenate all the rows for each sentence, keeping the languages separated. It could be accomplished very easily concatenating each column separately in a subquery, but what if the input data comes from a rather expensive query? You don’t want to run the statement for each language, do you?
Let’s see how this can be done in a single scan:
SELECT sentence_id, sentence_description, Latin, English, Italian
FROM (
SELECT Sentences.sentence_id, sentence_description, language_name, string
FROM @Sentences AS Sentences
OUTER APPLY (
SELECT *
FROM (
-- =================================
-- Create a Languages inline query
-- =================================
SELECT 'Latin'
UNION ALL SELECT 'English'
UNION ALL SELECT 'Italian'
) Languages (language_name)
CROSS APPLY (
-- =================================
-- Concatenate all the rows for
-- the current sentence and language
-- from an UNPIVOTed version of the
-- original rows table
-- =================================
SELECT sentence_id, string = (
SELECT string + ' ' AS [data()]
FROM @Rows AS src
UNPIVOT ( string FOR language_name IN (Latin, English, Italian) ) AS u
WHERE sentence_id = Sentences.sentence_id
AND language_name = Languages.language_name
ORDER BY row_id
FOR XML PATH('')
)
) AS ca
) AS oa
) AS src
-- =================================
-- Re-transform rows to columns
-- =================================
PIVOT ( MIN(string) FOR language_name IN ([Latin],[English],[Italian])) AS p
If you don’t like PIVOT and UNPIVOT, you can always use CASE expressions to create a crosstab.
Here’s the final result:

With a little of PIVOT, UNPIVOT and FOR XML you can achieve really surprising results, you just need to unleash your creativity.
Exceptional DBA Awards 2011
Time has come for the annual Exceptional DBA Awards contest, sponsored by Red Gate and judged by four really exceptional DBAs:
- Steve Jones (blog|twitter)
- Rodney Landrum (blog|twitter)
- Brad McGehee (blog|twitter)
- Brent Ozar (blog|twitter)
The judges picked their finalists and it would really be hard to choose the winner if I didn’t happen to know one of them.
I won’t talk around it: please vote for Jeff Moden!
I don’t know the other three finalists and I am sure that they really are very good DBAs, probably exceptional DBAs, otherwise they would not have made it to the final showdown. But I have no doubt that Jeff is the one to vote.
There is something that goes beyond being exceptional. I can’t give it a name, but I will try to explain it.
Some years ago, I was working primarily as a developer at a big shoe company and I was one of those “Accidental” DBAs lurking on the SQL Server Central forums struggling to expand their knowledge. I already had a long experience in database development, but, at that time, I also needed to start learning how to take care of my databases. Whenever I had an issue, SQL Server Central had a thread with an answer for me.
One day, I stumbled upon a question and, surprisingly enough, I happened to know the answer. That day, when I hit the “reply” button, I had no idea of the great journey that was ahead of me.
SQL Server Central people are exceptional and the forums are totally addictive. Long story short, I became one of the “regulars”. I could not stay away from the forums and checking the e-mail notifications became part of my morning tasks.
Among the other regulars, there was one folk with a funny signature, a sort of manifesto of the anti-RBAR party. “RBAR”: a made-up word that probably very few people knew at the time, which now is just the right word to say it when you do it “Row By Agonizing Row”!
That guy with the funny signature was one of the most active members and it looked like he spent the whole night posting on the forums (and he probably did). His replies were always smart, spot-on and humorous.
He also had published some articles where he preached avoiding cursors like the plague and replacing them with the T-SQL Swiss army knife “par excellence”: the Tally table.
Needless to say, the folk’s name is Jeff Moden.
 His articles are always enlightening and thorough, shipped with the complete code and solid performance demonstration. Jeff’s writing style is unique and engaging: you would recognize one of his articles even if he published under a pseudonym (which he did, actually. Remember Phil McCracken?).
His articles are always enlightening and thorough, shipped with the complete code and solid performance demonstration. Jeff’s writing style is unique and engaging: you would recognize one of his articles even if he published under a pseudonym (which he did, actually. Remember Phil McCracken?).
I have never met Jeff in person, but I consider him a good friend. He also helped me write my first article for SSC: his hair must have turned white when he read the first draft and his beard must have grown an inch when he saw my poor English. Nonetheless, his kind words, encouragement and suggestions helped me accomplish that article and I consider him one of the main culprits if now I’m not just a thread-aholic, but I also turned into a blog-aholic.
Jeff deserves your vote, because he is an exceptional person and an exceptional DBA. People like him are more than exceptional: they’re one of a kind. I don’t know the other three finalists, but I want to believe they’re not as exceptional as Jeff, otherwise I would have to feel even more humbled compared to them.
Go vote for Jeff, and, even more important, read his articles. You will find them enjoyable and inspiring.
Table-level CHECK constraints
EDITED 2011-08-05: This post is NOT about the “correct” way to implement table-level check constraints. If that is what you’re looking for, see this post instead.
Today on SQL Server Central I stumbled upon an apparently simple question on CHECK constraints. The question can be found here.
The OP wanted to know how to implement a CHECK constraint based on data from another table. In particular, he wanted to prohibit modifications to records in a detail table based on a datetime column on the master table. A simple way to achieve it is to use a trigger, but he was concerned about performance and wanted to implement it with a CHECK constraint.
Let’s see how this can be done. First of all, we will need a couple of test tables, with some sample data:
USE tempdb;
GO
-- Create master table
CREATE TABLE masterTable (
id int identity(1,1) PRIMARY KEY,
dateColumn datetime
)
GO
-- Create referenced table
CREATE TABLE detailTable (
id int identity(1,1) PRIMARY KEY,
master_id int FOREIGN KEY REFERENCES masterTable(id),
valueColumn varchar(50)
)
GO
-- Insert sample data
INSERT INTO masterTable(dateColumn) VALUES(GETDATE())
INSERT INTO masterTable(dateColumn) VALUES(DATEADD(day,-1,GETDATE()))
INSERT INTO masterTable(dateColumn) VALUES(DATEADD(day,-2,GETDATE()))
SELECT * FROM masterTable
-- Insert sample data in referenced table
INSERT INTO detailTable(master_id, valueColumn) VALUES (1,'Value for id 1')
INSERT INTO detailTable(master_id, valueColumn) VALUES (2,'Value for id 2')
INSERT INTO detailTable(master_id, valueColumn) VALUES (3,'Value for id 3')
SELECT * FROM detailTable
Now we need to create the CHECK constraint. The only way to code it to validate data against a different table is to use a scalar UDF, which, to answer the original question, makes it a poor choice from a performance standpoint.
-- Create a scalar UDF: you will need this in the CHECK constraint
CREATE FUNCTION getMasterDate(@id int)
RETURNS datetime
AS
BEGIN
RETURN ISNULL((SELECT dateColumn FROM masterTable WHERE id = @id),'30110101')
END
GO
-- Add the constraint WITH NOCHECK: existing rows are not affected
ALTER TABLE detailTable WITH NOCHECK ADD CONSTRAINT chk_date
CHECK (DATEADD(day,-1,GETDATE()) > dbo.getMasterDate(master_id))
No surprises: the constraints gets added to the table and SQL Server does not complain about the existing rows that don’t pass the check, since we decided to use the NOCHECK switch.
Now, with the constraint in place, we should be unable to modify the data in a way that violates the constraint:
UPDATE detailTable SET valueColumn = 'New ' + valueColumn
Surprise! Some rows conflict with the CHECK constraint, but no complaints from SQL Server, because the constraint is attached to a single column (master_id), and we left that column untouched.
In fact, if we query sys.check_constraints, we can see that this is a column-scoped constraint:
SELECT parent_column_id, definition, is_not_trusted
FROM sys.check_constraints
WHERE parent_object_id = OBJECT_ID('detailTable')
Parent_column_id = 0 means table scoped constraint, parent_column_id > 0 means column-scoped constraint.
If we try to update the column “master_id”, the constraint prevents the modification:
-- If you try to update master_id it fails UPDATE detailTable SET master_id = master_id + 1 - 1
Msg 547, Level 16, State 0, Line 2 The UPDATE statement conflicted with the CHECK constraint "chk_date". The conflict occurred in database "tempdb", table "dbo.detailTable", column 'master_id'. The statement has been terminated.
What is really surprising is how SQL Server behaves if we decide to make the constraint table-scoped, adding another predicate to the CHECK:
-- Drop the constraint
ALTER TABLE detailTable DROP CONSTRAINT chk_date
GO
-- Create the constraint referencing multiple columns
ALTER TABLE detailTable WITH NOCHECK ADD CONSTRAINT chk_date
CHECK (
DATEADD(day,-1,GETDATE()) > dbo.getMasterDate(master_id)
AND
ISNULL(valueColumn,'') = ISNULL(valueColumn,SPACE(0))
)
GO
As we might expect, it doesn’t work any more:
UPDATE detailTable SET valueColumn = 'New ' + valueColumn
Msg 547, Level 16, State 0, Line 2 The UPDATE statement conflicted with the CHECK constraint "chk_date". The conflict occurred in database "tempdb", table "dbo.detailTable", column 'master_id'. The statement has been terminated.
But, wait: what is REALLY attaching the constraint to the column we are trying to modify? Does a thing such as a “table-scoped” constraint really exist?
We just need to add another column and see how it changes the behaviour of the CHECK constraint:
ALTER TABLE detailTable ADD anotherColumn int
Now, if we try to update the newly created column, since we have a “table-scoped” CHECK constraint, we should get an error:
UPDATE detailTable SET anotherColumn = 1
… but it’s not so!
(3 row(s) affected)
The constraint does not include any reference to “anotherColumn”, so it does not even get executed. If you don’t believe it is so, you can check with Profiler and capture any call to scalard UDFs: you wan’t see any in this case.
This means that what Microsoft calls a table level CHECK constraint is something that does not really exist and a better name for it would be “Multicolumn CHECK constraint”.
The main thing to keep in mind is that if we want the constraint to check the data regardless of the column getting modified we MUST include ALL the columns of the table in the constraint definition.
My stored procedure code template
Do you use code templates in SSMS? I am sure that at least once you happened to click “New stored procedure” in the object explorer context menu.
The default template for this action is a bit disappointing and the only valuable line is “SET NOCOUNT ON”. The rest of the code has to be heavily rewritten or deleted. Even if you use the handy keyboard shortcut for “Specify values for template parameters” (CTRL+SHIFT+M), you end up entering a lot of useless values. For instance, I find it very annoying having to enter stored procedure parameters definitions separately for name, type and default value.
Moreover, one of the questions I see asked over and over in the forums at SqlServerCentral is how to handle transactions and errors in a stored procedure, something that the default template does not.
Long story short, I’m not very happy with the built-in template, so I decided to code my own:
-- =============================================
-- Author: <Author,,Name>
-- Create date: <Create Date,,>
-- Description: <Description,,>
-- =============================================
CREATE PROCEDURE <ProcedureName, sysname, >
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT,
QUOTED_IDENTIFIER,
ANSI_NULLS,
ANSI_PADDING,
ANSI_WARNINGS,
ARITHABORT,
CONCAT_NULL_YIELDS_NULL ON;
SET NUMERIC_ROUNDABORT OFF;
DECLARE @localTran bit
IF @@TRANCOUNT = 0
BEGIN
SET @localTran = 1
BEGIN TRANSACTION LocalTran
END
BEGIN TRY
--Insert code here
IF @localTran = 1 AND XACT_STATE() = 1
COMMIT TRAN LocalTran
END TRY
BEGIN CATCH
DECLARE @ErrorMessage NVARCHAR(4000)
DECLARE @ErrorSeverity INT
DECLARE @ErrorState INT
SELECT @ErrorMessage = ERROR_MESSAGE(),
@ErrorSeverity = ERROR_SEVERITY(),
@ErrorState = ERROR_STATE()
IF @localTran = 1 AND XACT_STATE() <> 0
ROLLBACK TRAN
RAISERROR ( @ErrorMessage, @ErrorSeverity, @ErrorState)
END CATCH
END
This template can be saved in the default path and overwrite the kludgy “New Stored Procedure” built-in template.
Some things to keep in mind:
- I don’t use nested transactions (they’re totally pointless IMHO) and I check for an existing transaction instead.
- The stored procedure will commit/rollback the transaction only if it was started inside the procedure.
- I want every stored procedure to throw the errors it catches. If there’s another calling procedure, it will take care of the errors in the same way.
- This is your computer: you can safely replace <Author, ,Name> with your real name.
- It would really be nice if there was some kind of way to make SSMS fill <Create Date, ,> with the current date. Unfortunately there’s no way. If you are using CVS or some other kind of version control system, this is a nice place for an RCS string such as $Date$
- If you like templates parameters and you heard bad news regarding this feature in the next version of SQL Server (codename Denali), don’t worry: MS fixed it.
Setting up linked servers with an out-of-process OLEDB provider
A new article on SQLServerCentral today: Setting up linked servers with an out-of-process OLEDB provider.
I had to struggle to find the appropriate security settings to make a commercial OLEDB provider work with out-of-process load and I want to share the results of my research with you.
It took 50 hours of Microsoft paid support to partially solve the issue and a huge time spent on Google and MSDN to find a complete resolution. I hope this can help those that will have to face the same issue some day.
My First Article!
Today SQL Server Central published my first article:
Understanding T-SQL Expression Short-Circuiting
It ‘s a great joy and pride for me. I hope you enjoy it.
