Category Archives: PowerShell
Collecting Diagnostic data from multiple SQL Server instances with dbatools
Keeping their SQL Server instances under control is a crucial part of the job of a DBA. SQL Server offers a wide variety of DMVs to query in order to check the health of the instance and establish a performance baseline.
My favourite DMV queries are the ones crafted and maintained by Glenn Berry: the SQL Server Diagnostic Queries. These queries already pack the right amount of information and can be used to take a snapshot of the instance’s health and performance.
Piping the results of these queries to a set of tables at regular intervals can be a good way to keep an eye on the instance. Automation in SQL Server rhymes with dbatools, so today I will show you how to automate the execution of the diagnostic queries and the storage of the results to a centralized database that you can use as a repository for your whole SQL Server estate.
The script
The script I’m using for this can be found on GitHub and you can download it, modify it and adapt it to your needs.
I won’t include it here, there is really no need for that, as you can find it on Github already. So, go, grab it from this address, save it and open it in your favourite code editor.
Done? Excellent! Let’s go through it together.
The script, explained
What I really love about PowerShell is how simple it is to filter, extend and manipulate tabular data using the pipeline, in a way that resonates a lot with the experience of T-SQL developers.
The main part of the script is the one that invokes all the diagnostic queries included in the list $queries. This is done by invoking the cmdlet Invoke-DbaDiagnosticQuery, that takes care of using a version of the diagnostic query that matches the version of the target server and selecting the data. As usual with dbatools, the -SqlInstance parameter accepts a list of servers, so you can pass in the list of all the SQL Servers in your infrastructure.
Invoke-DbaDiagnosticQuery -SqlInstance $SourceServer -QueryName $queries
Sometimes the queries do not generate any data, so it is important to filter out the empty result sets.
Where-Object { $_.Result -ne $null }
In order to store the data collected at multiple servers and multiple points in time, you need to attach some additional columns to the result sets before writing them to the destination tables. This is a very simple task in PowerShell and it can be accomplished by using the Select-Object cmdlet.
Select-Object accepts a list of columns taken from the input object and can also add calculated columns using hashtables with label/expression pairs. The syntax is not the friendliest possible (in fact, I have to look it up every time I need it), but it gets the job done.
In this case, you need to add a column for the server name, one for the database name (only for database scoped queries) and one for the snapshot id. I decided to use a timestamp in the yyyyMMdd as the snapshot id. This is what the code to define the properties looks like:
$TableName = $_.Name
$DatabaseName = $_.Database
$ServerName = $_.SqlInstance
$snapshotProp = @{
Label = "snapshot_id"
Expression = {$SnapshotId}
}
$serverProp = @{
Label = "Server Name"
Expression = {$ServerName}
}
$databaseProp = @{
Label = "Database Name"
Expression = {$DatabaseName}
}
Now that the hashtables that define the additional properties are ready, you need to decide whether the input dataset requires the new properties or not: if a property with the same name is already present you need to skip adding the new property.
Unfortunately, this has to be done in two different ways, because the dataset produced by the diagnostic queries could be returned as a collection of System.Data.Datarow objects or as a collection of PsCustomObject.
if(-not (($_.Result.PSObject.Properties | Select-Object -Expand Name) -contains "Server Name")) {
if(($_.Result | Get-Member -MemberType NoteProperty -Name "Server Name" | Measure-Object).Count -eq 0) {
$expr += ' $serverProp, '
}
}
Now comes the interesting part of the
script: the data has to get written to a destination table in a database.
Dbatools has a cmdlet for that called Write-DbaDataTable.
Among the abilities of this nifty cmdlet, you can auto create the destination tables based on the data found in the input object, thus making your life much easier. In order to pass all the parameters to this cmdlet, I will use a splat, which improves readability quite a bit.
$expr += '*'
$param = @{
SqlInstance = $DestinationServer
Database = $DestinationDatabase
Schema = $DestinationSchema
AutoCreateTable = $true
Table = $TableName
InputObject = Invoke-Expression $expr
}
Write-DbaDataTable @param
As you can see, you need to pass a
destination server name, a database name, a schema name and a table name. As I
already mentioned, Write-DbaDataTable will take care of creating the target
table.
One thing to note is how the data is passed
to the cmdlet: the InputObject is the result of an expression, based on the
dynamic select list generated inside the ForeEach-Object cmdlet. This is very
similar to building a dynamic query in T-SQL.
Conclusion
This script can be downloaded from GitHub and you can schedule it on a centralized management server in order to collect diagnostic data across your entire SQL Server estate.
Dbatools is the ultimate toolset for the dba: if you’re still using the GUI or overly complicated T-SQL scripts to administer and maintain your SQL Server estate, you’re missing out.
Dbatools is also a great opportunity for me to learn new tricks in Powershell, which is another great productivity tool that can’t be overlooked by DBAs. What are you waiting for? Go to dbatools.io now and start your journey: you won’t regret it.
Generating a Jupyter Notebook for Glenn Berry’s Diagnostic Queries with PowerShell
The March release of Azure Data Studio now supports Jupyter Notebooks with SQL kernels. This is a very interesting feature that opens new possibilities, especially for presentations and for troubleshooting scenarios.
For presentations, it is fairly obvious what the use case is: you can prepare notebooks to show in your presentations, with code and results combined in a convenient way. It helps when you have to establish a workflow in your demos that the attendees can repeat at home when they download the demos for your presentation.
For troubleshooting scenarios, the interesting feature is the ability to include results inside a Notebook file, so that you can create an empty Notebook, send it to your client and make them run the queries and send it back to you with the results populated. For this particular usage scenario, the first thing that came to my mind is running the diagnostic queries by Glenn Berry in a Notebook.
Obviously, I don’t want to create such a Notebook manually by adding all the code cells one by one. Fortunately, PowerShell is my friend and can do the heavy lifting for me.
Unsurprisingly, dbatools comes to the rescue: André Kamman added a cmdlet that downloads, parses and executes Glenn Berry’s diagnostic queries and added the cmdlet to dbatools. The part that can help me is not a public function available to the user, but I can still go to GitHub and download the internal function Invoke-DbaDiagnosticQueryScriptParser for my needs.
The function returns a list of queries that I can use to generate the Jupyter Notebook:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # | |
| # Purpose: take the diagnostic queries from Glenn Berry | |
| # and generate a Jupyter Notebook to run in Azure Data Studio | |
| # | |
| # Example usage: | |
| # create-diagnostic-notebook.ps1 -diagnosticScriptPath "C:\Program Files\WindowsPowerShell\Modules\dbatools\0.9.777\bin\diagnosticquery\SQLServerDiagnosticQueries_2019_201901.sql" -notebookOutputPath "diagnostic-notebook.ipynb" | |
| # | |
| [CmdletBinding()] | |
| Param( | |
| [parameter(Mandatory)] | |
| [System.IO.FileInfo]$diagnosticScriptPath, | |
| [System.IO.FileInfo]$notebookOutputPath | |
| ) | |
| # | |
| # Function taken from dbatools https://github.com/sqlcollaborative/dbatools/blob/development/internal/functions/Invoke-DbaDiagnosticQueryScriptParser.ps1 | |
| # Parses the diagnostic script and breaks it into individual queries, | |
| # with text and description | |
| # | |
| function Invoke-DbaDiagnosticQueryScriptParser { | |
| [CmdletBinding(DefaultParameterSetName = "Default")] | |
| Param( | |
| [parameter(Mandatory)] | |
| [ValidateScript( {Test-Path $_})] | |
| [System.IO.FileInfo]$filename, | |
| [Switch]$ExcludeQueryTextColumn, | |
| [Switch]$ExcludePlanColumn, | |
| [Switch]$NoColumnParsing | |
| ) | |
| $out = "Parsing file {0}" -f $filename | |
| write-verbose -Message $out | |
| $ParsedScript = @() | |
| [string]$scriptpart = "" | |
| $fullscript = Get-Content -Path $filename | |
| $start = $false | |
| $querynr = 0 | |
| $DBSpecific = $false | |
| if ($ExcludeQueryTextColumn) {$QueryTextColumn = ""} else {$QueryTextColumn = ", t.[text] AS [Complete Query Text]"} | |
| if ($ExcludePlanColumn) {$PlanTextColumn = ""} else {$PlanTextColumn = ", qp.query_plan AS [Query Plan]"} | |
| foreach ($line in $fullscript) { | |
| if ($start -eq $false) { | |
| if (($line -match "You have the correct major version of SQL Server for this diagnostic information script") -or ($line.StartsWith("– Server level queries ***"))) { | |
| $start = $true | |
| } | |
| continue | |
| } | |
| if ($line.StartsWith("– Database specific queries ***") -or ($line.StartsWith("– Switch to user database **"))) { | |
| $DBSpecific = $true | |
| } | |
| if (!$NoColumnParsing) { | |
| if (($line -match "– uncomment out these columns if not copying results to Excel") -or ($line -match "– comment out this column if copying results to Excel")) { | |
| $line = $QueryTextColumn + $PlanTextColumn | |
| } | |
| } | |
| if ($line -match "-{2,}\s{1,}(.*) \(Query (\d*)\) \((\D*)\)") { | |
| $prev_querydescription = $Matches[1] | |
| $prev_querynr = $Matches[2] | |
| $prev_queryname = $Matches[3] | |
| if ($querynr -gt 0) { | |
| $properties = @{QueryNr = $querynr; QueryName = $queryname; DBSpecific = $DBSpecific; Description = $queryDescription; Text = $scriptpart} | |
| $newscript = New-Object -TypeName PSObject -Property $properties | |
| $ParsedScript += $newscript | |
| $scriptpart = "" | |
| } | |
| $querydescription = $prev_querydescription | |
| $querynr = $prev_querynr | |
| $queryname = $prev_queryname | |
| } else { | |
| if (!$line.startswith("–") -and ($line.trim() -ne "") -and ($null -ne $line) -and ($line -ne "\n")) { | |
| $scriptpart += $line + "`n" | |
| } | |
| } | |
| } | |
| $properties = @{QueryNr = $querynr; QueryName = $queryname; DBSpecific = $DBSpecific; Description = $queryDescription; Text = $scriptpart} | |
| $newscript = New-Object -TypeName PSObject -Property $properties | |
| $ParsedScript += $newscript | |
| $ParsedScript | |
| } | |
| $cells = @() | |
| Invoke-DbaDiagnosticQueryScriptParser $diagnosticScriptPath | | |
| Where-Object { -not $_.DBSpecific } | | |
| ForEach-Object { | |
| $cells += [pscustomobject]@{cell_type = "markdown"; source = "## $($_.QueryName)`n`n$($_.Description)" } | |
| $cells += [pscustomobject]@{cell_type = "code"; source = $_.Text } | |
| } | |
| $preamble = @" | |
| { | |
| "metadata": { | |
| "kernelspec": { | |
| "name": "SQL", | |
| "display_name": "SQL", | |
| "language": "sql" | |
| }, | |
| "language_info": { | |
| "name": "sql", | |
| "version": "" | |
| } | |
| }, | |
| "nbformat_minor": 2, | |
| "nbformat": 4, | |
| "cells": | |
| "@ | |
| $preamble | Out-File $notebookOutputPath | |
| $cells | ConvertTo-Json | Out-File -FilePath $notebookOutputPath -Append | |
| "}}" | Out-File -FilePath $notebookOutputPath -Append |
In order to use the script, you need to provide the path to the file that contains the diagnostic queries and the path where the new Jupyter Notebook should be generated. Dbatools includes the latest version of the diagnostic scripts already, so you just need to choose which flavor you want to use. You will find all available scripts in the module directory of dbatools:
$dbatoolsPath = Split-Path -parent (Get-Module -ListAvailable dbatools).path $dbatoolsPath Get-ChildItem "$dbatoolsPath\bin\diagnosticquery" | Select-Object Name
The script above produces this output:
C:\Program Files\WindowsPowerShell\Modules\dbatools\0.9.777 Name ---- SQLServerDiagnosticQueries_2005_201901.sql SQLServerDiagnosticQueries_2008R2_201901.sql SQLServerDiagnosticQueries_2008_201901.sql SQLServerDiagnosticQueries_2012_201901.sql SQLServerDiagnosticQueries_2014_201901.sql SQLServerDiagnosticQueries_2016SP2_201901.sql SQLServerDiagnosticQueries_2016_201901.sql SQLServerDiagnosticQueries_2017_201901.sql SQLServerDiagnosticQueries_2019_201901.sql SQLServerDiagnosticQueries_AzureSQLDatabase_201901.sql
Once you decide which file to use, you can pass it to the script:
create-diagnostic-notebook.ps1 `
-diagnosticScriptPath "C:\Program Files\WindowsPowerShell\Modules\dbatools\0.9.777\bin\diagnosticquery\SQLServerDiagnosticQueries_2019_201901.sql" `
-notebookOutputPath "diagnostic-notebook.ipynb"
What you obtain is a Jupyter Notebook that you can open in Azure Data Studio:
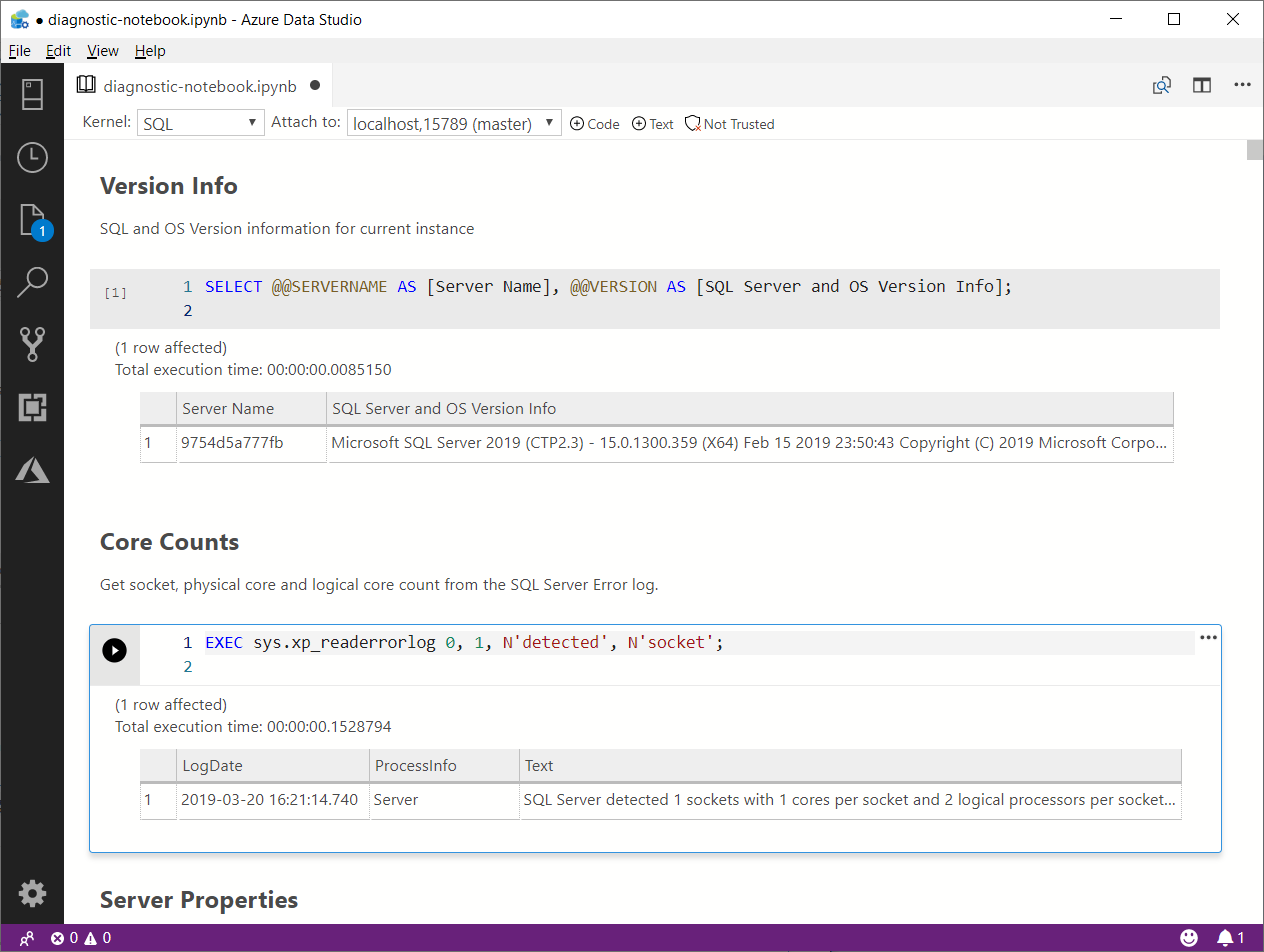
This is nice way to incorporate the code and results in a single file, that you can review offline later. This also allows you to send the empty notebook to a remote client, ask to run one or more queries and send back the notebook including the results for you to review.
Happy Notebooking!
Recovering the PsGallery Repository behind a Corporate Proxy
While getting a new workstation is usually nice, reinstalling all your softwares and settings is definitely not the most pleasant thing that comes to my mind. One of the factors that can contribute the most to making the process even less pleasant is working around the corporate proxy.
Many applications live on the assumption that nobody uses proxy servers, thus making online repositories inaccessible for new installations and for automatic updates.
Unfortunately, PsGallery is no exception.
If you run Get-PSRepository on a vanilla installation of Windows 10 behind a corporate proxy, you will get a warning message:
WARNING: Unable to find module repositories.
After unleashing my Google-Fu, I learned that I had to run the following command to recover the missing PsRepository:
Register-PSRepository -Default -Verbose
The command works without complaining, with just a warning suggesting that something might have gone wrong:
VERBOSE: Performing the operation "Register Module Repository." on target "Module Repository 'PSGallery' () in provider 'PowerShellGet'.".
Again, running Get-PSRepository returns an empty result set and the usual warning:
WARNING: Unable to find module repositories.
The problem here is that the cmdlet Register-PsRepository assumes that you can connect directly to the internet, without using a proxy, so it tries to do so, fails to connect and does not throw a meaningful error messsage. Thank you, Register-PsRepository, much appreciated!
In order to fix it, you need to configure your default proxy settings in your powershell profile. Start powershell and run the following:
notepad $PROFILE
This will start notepad and open your powershell profile. If the file doesn’t exist, Notepad will prompt you to create it.
Add these lines to the profile script:
[system.net.webrequest]::defaultwebproxy = new-object system.net.webproxy('http://YourProxyHostNameGoesHere:ProxyPortGoesHere')
[system.net.webrequest]::defaultwebproxy.credentials = [System.Net.CredentialCache]::DefaultNetworkCredentials
[system.net.webrequest]::defaultwebproxy.BypassProxyOnLocal = $true
Save, close and restart powershell (or execute the profile script with iex $PROFILE).
Now, you can register the default PsRepository with this command:
Register-PSRepository -Default
If you query the registered repositories, you will now see the default PsRepository:
Get-PSRepository Name InstallationPolicy SourceLocation ---- ------------------ -------------- PSGallery Untrusted https://www.powershellgallery.com/api/v2/
Horray!
Tracking Table Usage and Identifying Unused Objects
One of the things I hate the most about “old” databases is the fact that unused tables are kept forever, because nobody knows whether they’re used or not. Sometimes it’s really hard to tell. Some databases are accessed by a huge number of applications, reports, ETL tools and God knows what else. In these cases, deciding whether you should drop a table or not is a tough call.
Search your codebase
The easiest way to know if a table is used, is to search the codebase for occurences of the table name. However, finding the table name in the code does not mean it is used: there are code branches that in turn are not used. Modern languages and development tools can help you identify unused methods and objects, but it’s not always feasible or 100% reliable (binary dependencies, scripts, dynamic code are, off top of my head, some exceptions).
On the other hand, not finding the table name in the code does not mean you can delete it with no issues. The table could be used by dynamic code and the name retrieved from a configuration file or a table in the database.
In other cases, the source code is not available at all.
Index usage: clues, not evidence
Another way to approach the problem is by measuring the effects of the code execution against the database, in other words, by looking at the information stored by SQL Server whenever a table is accessed.
The DMV sys.dm_db_index_usage_stats records information on all seeks, scans, lookups and updates against indexes and is a very good place to start the investigation. If something is writing to the table or reading from it, you will see the numbers go up and the dates moving forward.
Great, so we’re done and this post is over? Not exactly: there are some more facts to take into account.
First of all, the DMV gets cleared every time SQL Server is restarted, so the accuracy of the data returned is heavily dependant on how long the instance has been running. Moreover, some actions (rebuilding the index, to name one) reset the index usage stats and if you want to rely on sensible stats, your only option is to persist the data in some place regularly.
To achieve this goal, I coded this simple stored procedure that reads the stats from the DMV and stores it in a table, updating the read and write counts for each subsequent execution.
-- You have a TOOLS database, right?
-- If not, create one, you will thank me later
USE TOOLS;
GO
-- A place for everything, everything in its place
IF SCHEMA_ID('meta') IS NULL
EXEC('CREATE SCHEMA meta;')
GO
-- This table will hold index usage summarized at table level
CREATE TABLE meta.index_usage(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
)
-- This table will hold the last snapshot taken
-- It will be used to capture the snapshot and
-- merge it with the destination table
CREATE TABLE meta.index_usage_last_snapshot(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
)
GO
-- This procedure captures index usage stats
-- and merges the stats with the ones already captured
CREATE PROCEDURE meta.record_index_usage
AS
BEGIN
SET NOCOUNT ON;
IF OBJECT_ID('tempdb..#stats') IS NOT NULL
DROP TABLE #stats;
-- We will use the index stats multiple times, so parking
-- them in a temp table is convenient
CREATE TABLE #stats(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
);
-- Reads index usage stats and aggregates stats at table level
-- Aggregated data is saved in the temporary table
WITH index_stats AS (
SELECT DB_NAME(database_id) AS db_name,
OBJECT_SCHEMA_NAME(object_id,database_id) AS schema_name,
OBJECT_NAME(object_id, database_id) AS object_name,
user_seeks + user_scans + user_lookups AS read_count,
user_updates AS write_count,
last_read = (
SELECT MAX(value)
FROM (
VALUES(last_user_seek),(last_user_scan),(last_user_lookup)
) AS v(value)
),
last_write = last_user_update
FROM sys.dm_db_index_usage_stats
WHERE DB_NAME(database_id) NOT IN ('master','model','tempdb','msdb')
)
INSERT INTO #stats
SELECT db_name,
schema_name,
object_name,
SUM(read_count) AS read_count,
MAX(last_read) AS last_read,
SUM(write_count) AS write_count,
MAX(last_write) AS last_write
FROM index_stats
GROUP BY db_name,
schema_name,
object_name;
DECLARE @last_date_in_snapshot datetime;
DECLARE @sqlserver_start_date datetime;
-- reads maximum read/write date from the data already saved in the last snapshot table
SELECT @last_date_in_snapshot = MAX(CASE WHEN last_read > last_write THEN last_read ELSE last_write END)
FROM meta.index_usage_last_snapshot;
-- reads SQL Server start time
SELECT @sqlserver_start_date = sqlserver_start_time FROM sys.dm_os_sys_info;
-- handle restarted server: last snapshot is before server start time
IF (@last_date_in_snapshot) < (@sqlserver_start_date)
TRUNCATE TABLE meta.index_usage_last_snapshot;
-- handle snapshot table empty
IF NOT EXISTS(SELECT * FROM meta.index_usage_last_snapshot)
INSERT INTO meta.index_usage_last_snapshot
SELECT * FROM #stats;
-- merges data in the target table with the new collected data
WITH offset_stats AS (
SELECT newstats.db_name,
newstats.schema_name,
newstats.object_name,
-- if new < old, the stats have been reset
newstats.read_count -
CASE
WHEN newstats.read_count < ISNULL(oldstats.read_count,0) THEN 0
ELSE ISNULL(oldstats.read_count,0)
END
AS read_count,
newstats.last_read,
-- if new < old, the stats have been reset
newstats.write_count -
CASE
WHEN newstats.write_count < ISNULL(oldstats.write_count,0) THEN 0
ELSE ISNULL(oldstats.write_count,0)
END
AS write_count,
newstats.last_write
FROM #stats AS newstats
LEFT JOIN meta.index_usage_last_snapshot AS oldstats
ON newstats.db_name = oldstats.db_name
AND newstats.schema_name = oldstats.schema_name
AND newstats.object_name = oldstats.object_name
)
MERGE INTO meta.index_usage AS dest
USING offset_stats AS src
ON src.db_name = dest.db_name
AND src.schema_name = dest.schema_name
AND src.object_name = dest.object_name
WHEN MATCHED THEN
UPDATE SET read_count += src.read_count,
last_read = src.last_read,
write_count += src.write_count,
last_write = src.last_write
WHEN NOT MATCHED BY TARGET THEN
INSERT VALUES (
src.db_name,
src.schema_name,
src.object_name,
src.read_count,
src.last_read,
src.write_count,
src.last_write
);
-- empty the last snapshot
TRUNCATE TABLE meta.index_usage_last_snapshot;
-- replace it with the new collected data
INSERT INTO meta.index_usage_last_snapshot
SELECT * FROM #stats;
END
GO
You can schedule the execution of the stored procedure every hour or so and you will see data flow in the meta.index_usage_last_snapshot table. Last read/write date will be updated and the read/write counts will be incremented by comparing saved counts with the captured ones: if I had 1000 reads in the previous snapshot and I capture 1200 reads, the total reads column must be incremented by 200.
So, if I don’t find my table in this list after monitoring for some days, is it safe to assume that it can be deleted? Probably yes. More on that later.
What these stats don’t tell you is what to do when you do find the table in the list. It would be reasonable to think that the table is used, but there are several reasons why it may have ended up being read or written and not all of them will be ascribable to an application.
For instance, if a table is merge replicated, the replication agents will access it and read counts will go up. What the index usage stats tell us is that something is using a table but it says nothing about the nature of that something. If you want to find out more, you need to set up some kind of monitoring that records additional information about where reads and writes come from.
Extended Events to the rescue
For this purpose, an audit is probably too verbose, because it will record an entry for each access to each table being audited. The audit file will grow very quickly if not limited to a few objects to investigate. Moreover, audits have to be set up for each table and kept running for a reasonable time before drawing conclusions.
Audits are based on Extended Events: is there another way to do the same thing Audits do using extended events directly? Of course there is, but it’s trickier than you would expect.
First of all, the Extended Events used by the audit feature are not available directly. You’ve been hearing several times that audits use Extended Events but nobody ever told you which events they are using: the reason is that those events are not usable in a custom Extended Events session (the SecAudit package is marked as “private”). As a consequence, if you want to audit table access, you will have to use some other kind of event.
In order to find out which Extended Events provide information at the object level, we can query the sys.dm_xe_object_columns DMV:
SELECT object_name, description FROM sys.dm_xe_object_columns WHERE name = 'object_id'
As you will see, the only event that could help in this case is the lock_acquired event. Whenever a table is accessed, a lock will be taken and capturing those locks is a quick and easy way to discover activity on the tables.
Here is the definition of a session to capture locking information:
CREATE EVENT SESSION [audit_table_usage] ON SERVER
ADD EVENT sqlserver.lock_acquired (
SET collect_database_name = (0)
,collect_resource_description = (1)
ACTION(sqlserver.client_app_name, sqlserver.is_system, sqlserver.server_principal_name)
WHERE (
[package0].[equal_boolean]([sqlserver].[is_system], (0)) -- user SPID
AND [package0].[equal_uint64]([resource_type], (5)) -- OBJECT
AND [package0].[not_equal_uint64]([database_id], (32767)) -- resourcedb
AND [package0].[greater_than_uint64]([database_id], (4)) -- user database
AND [package0].[greater_than_equal_int64]([object_id], (245575913)) -- user object
AND (
[mode] = (1) -- SCH-S
OR [mode] = (6) -- IS
OR [mode] = (8) -- IX
OR [mode] = (3) -- S
OR [mode] = (5) -- X
)
)
)
WITH (
MAX_MEMORY = 20480 KB
,EVENT_RETENTION_MODE = ALLOW_MULTIPLE_EVENT_LOSS
,MAX_DISPATCH_LATENCY = 30 SECONDS
,MAX_EVENT_SIZE = 0 KB
,MEMORY_PARTITION_MODE = NONE
,TRACK_CAUSALITY = OFF
,STARTUP_STATE = OFF
);
GO
If you start this session and monitor the data captured with the “Watch live data” window, you will soon notice that a huge number of events gets captured, which means that the output will also be huge and analyzing it can become a daunting task. Saving this data to a file target is not the way to go here: is there another way?
The main point here is that there is no need for the individual events, but the interesting information is the aggregated data from those events. Ideally, you would need to group by object_id and get the maximum read or write date. If possible, counting reads and writes by object_id would be great. At a first look, it seems like a good fit for the histogram target, however you will soon discover that the histogram target can “group” on a single column, which is not what you want. Object_ids are not unique and you can have the same object_id in different databases. Moreover, the histogram target can only count events and is not suitable for other types of aggregation, such as MAX.
Streaming the events with Powershell
Fortunately, when something is not available natively, you can code your own implementation. In this case, you can use the Extended Events streaming API to attach to the session and evaluate the events as soon as they show up in the stream.
In this example, I will show you how to capture the client application name along with the database and object id and group events on these 3 fields. If you are interested in additional fields (such as host name or login name), you will need to group by those fields as well.
In the same way, if you want to aggregate additional fields, you will have to implement your own logic. In this example, I am computing the MAX aggregate for the read and write events, without computing the COUNT. The reason is that it’s not easy to predict whether the count will be accurate or not, because different kind of locks will be taken in different situations (under snapshot isolation no shared locks are taken, so you have to rely on SCH-S locks; when no dirty pages are present SQL Server takes IS locks and not S locks…).
Before going to the Powershell code, you will need two tables to store the information:
USE TOOLS;
GO
CREATE TABLE meta.table_usage_xe(
db_name sysname,
schema_name sysname,
object_name sysname,
client_app_name nvarchar(128),
last_read datetime,
last_write datetime,
PRIMARY KEY(db_name, schema_name, object_name, client_app_name)
);
CREATE TABLE meta.table_usage_xe_last_snapshot(
database_id int,
object_id int,
client_app_name nvarchar(128),
last_read datetime,
last_write datetime,
PRIMARY KEY(database_id, object_id, client_app_name)
);
Now that you have a nice place to store the aggregated information, you can start this script to capture the events and persist them.
sl $Env:Temp
#For SQL Server 2014:
Add-Type -Path 'C:\Program Files\Microsoft SQL Server\120\Shared\Microsoft.SqlServer.XE.Core.dll'
Add-Type -Path 'C:\Program Files\Microsoft SQL Server\120\Shared\Microsoft.SqlServer.XEvent.Linq.dll'
#For SQL Server 2012:
#Add-Type -Path 'C:\Program Files\Microsoft SQL Server\110\Shared\Microsoft.SqlServer.XEvent.Linq.dll'
$connectionString = 'Data Source = YourServerNameGoesHere; Initial Catalog = master; Integrated Security = SSPI'
$SessionName = "audit_table_usage"
# loads all object ids for table objects and their database id
# table object_ids will be saved in order to rule out whether
# the locked object is a table or something else.
$commandText = "
DECLARE @results TABLE (
object_id int,
database_id int
);
DECLARE @sql nvarchar(max);
SET @sql = '
SELECT object_id, db_id()
FROM sys.tables t
WHERE is_ms_shipped = 0
';
DECLARE @statement nvarchar(max);
SET @statement = (
SELECT 'EXEC ' + QUOTENAME(name) + '.sys.sp_executesql @sql; '
FROM sys.databases d
WHERE name NOT IN ('master','model','msdb','tempdb')
FOR XML PATH(''), TYPE
).value('.','nvarchar(max)');
INSERT @results
EXEC sp_executesql @statement, N'@sql nvarchar(max)', @sql;
SELECT *
FROM @results
"
$objCache = @{}
$conn = New-Object -TypeName System.Data.SqlClient.SqlConnection -ArgumentList $connectionString
$cmd = New-Object -TypeName System.Data.SqlClient.SqlCommand
$cmd.CommandText = $commandText
$cmd.Connection = $conn
$conn.Open()
$conn.ChangeDatabase("master")
$rdr = $cmd.ExecuteReader()
# load table object_ids and store them in a hashtable
while ($rdr.Read()) {
$objId = $rdr.GetInt32(0)
$dbId = $rdr.GetInt32(1)
if(-not $objCache.ContainsKey($objId)){
$objCache.add($objId,@($dbId))
}
else {
$arr = $objCache.Get_Item($objId)
$arr += $dbId
$objCache.set_Item($objId, $arr)
}
}
$conn.Close()
# create a DataTable to hold lock information in memory
$queue = New-Object -TypeName System.Data.DataTable
$queue.TableName = $SessionName
[Void]$queue.Columns.Add("database_id",[Int32])
[Void]$queue.Columns.Add("object_id",[Int32])
[Void]$queue.Columns.Add("client_app_name",[String])
[Void]$queue.Columns.Add("last_read",[DateTime])
[Void]$queue.Columns.Add("last_write",[DateTime])
# create a DataView to perform searches in the DataTable
$dview = New-Object -TypeName System.Data.DataView
$dview.Table = $queue
$dview.Sort = "database_id, client_app_name, object_id"
$last_dump = [DateTime]::Now
# connect to the Extended Events session
[Microsoft.SqlServer.XEvent.Linq.QueryableXEventData] $events = New-Object -TypeName Microsoft.SqlServer.XEvent.Linq.QueryableXEventData `
-ArgumentList @($connectionString, $SessionName, [Microsoft.SqlServer.XEvent.Linq.EventStreamSourceOptions]::EventStream, [Microsoft.SqlServer.XEvent.Linq.EventStreamCacheOptions]::DoNotCache)
$events | % {
$currentEvent = $_
$database_id = $currentEvent.Fields["database_id"].Value
$client_app_name = $currentEvent.Actions["client_app_name"].Value
if($client_app_name -eq $null) { $client_app_name = [string]::Empty }
$object_id = $currentEvent.Fields["object_id"].Value
$mode = $currentEvent.Fields["mode"].Value
# search the object id in the object cache
# if found (and database id matches) ==> table
# otherwise ==> some other kind of object (not interesting)
if($objCache.ContainsKey($object_id) -and $objCache.Get_Item($object_id) -contains $database_id)
{
# search the DataTable by database_id, client app name and object_id
$found_rows = $dview.FindRows(@($database_id, $client_app_name, $object_id))
# if not found, add a row
if($found_rows.Count -eq 0){
$current_row = $queue.Rows.Add()
$current_row["database_id"] = $database_id
$current_row["client_app_name"] = $client_app_name
$current_row["object_id"] = $object_id
}
else {
$current_row = $found_rows[0]
}
if(($mode.Value -eq "IX") -or ($mode.Value -eq "X")) {
# Exclusive or Intent-Exclusive lock: count this as a write
$current_row["last_write"] = [DateTime]::Now
}
else {
# Shared or Intent-Shared lock: count this as a read
# SCH-S locks counted here as well (snapshot isolation ==> no shared locks)
$current_row["last_read"] = [DateTime]::Now
}
}
$ts = New-TimeSpan -Start $last_dump -End (get-date)
# Dump to database every 5 minutes
if($ts.TotalMinutes -gt 5) {
$last_dump = [DateTime]::Now
# BCP data to the staging table TOOLS.meta.table_usage_xe_last_snapshot
$bcp = New-Object -TypeName System.Data.SqlClient.SqlBulkCopy -ArgumentList @($connectionString)
$bcp.DestinationTableName = "TOOLS.meta.table_usage_xe_last_snapshot"
$bcp.Batchsize = 1000
$bcp.BulkCopyTimeout = 0
$bcp.WriteToServer($queue)
# Merge data with the destination table TOOLS.meta.table_usage_xe
$statement = "
BEGIN TRANSACTION
BEGIN TRY
MERGE INTO meta.table_usage_xe AS dest
USING (
SELECT db_name(database_id) AS db_name,
object_schema_name(object_id, database_id) AS schema_name,
object_name(object_id, database_id) AS object_name,
client_app_name,
last_read,
last_write
FROM meta.table_usage_xe_last_snapshot
) AS src
ON src.db_name = dest.db_name
AND src.schema_name = dest.schema_name
AND src.object_name = dest.object_name
AND src.client_app_name = dest.client_app_name
WHEN MATCHED THEN
UPDATE SET last_read = src.last_read,
last_write = src.last_write
WHEN NOT MATCHED THEN
INSERT (db_name, schema_name, object_name, client_app_name, last_read, last_write)
VALUES (db_name, schema_name, object_name, client_app_name, last_read, last_write);
TRUNCATE TABLE meta.table_usage_xe_last_snapshot;
COMMIT;
END TRY
BEGIN CATCH
ROLLBACK;
THROW;
END CATCH
"
$conn = New-Object -TypeName System.Data.SqlClient.SqlConnection -ArgumentList $connectionString
$cmd = New-Object -TypeName System.Data.SqlClient.SqlCommand
$cmd.CommandText = $statement
$cmd.Connection = $conn
$conn.Open()
$conn.ChangeDatabase("TOOLS")
[Void]$cmd.ExecuteNonQuery()
$conn.Close()
$queue.Rows.Clear()
}
}
WARNING: Be careful running this script against a production server: I tried it with a reasonaly busy server and the CPU/memory load of powershell.exe is non-negligible. On the other hand, the load imposed by the session per se is very low: make sure you run this script from a different machine and not on the database server.
What to do with unused objects
After monitoring for a reasonable amount of time, you will start to notice that some objects are never used and you will probably want to delete them. Don’t!
In my experience, as soon as you delete an object, something that uses it (and you didn’t capture) pops up and fails. In those cases, you want to restore the objects very quickly. I usually move everything to a “trash” schema and have it sitting there for some time (six months/one year) and eventually empty the trash. If somebody asks for a restore, it’s just as simple as an ALTER SCHEMA … TRANSFER statement.
Bottom line
Cleaning up clutter from a database is not simple: hopefully the techniques in this post will help you in the task. Everything would be much simpler if the Extended Events histogram target was more flexible, but please keep in mind that it’s not about the tools: these techniques can help you identify unused objects when no other information is available, but nothing is a good substitute for a correct use of the database. When new tables are added to a database, keep track of the request and take notes about who uses the tables for which purpose: everything will be much easier in the long run.
SQL Server Agent in Express Edition
As you probably know, SQL Server Express doesn’t ship with SQL Server Agent.
This is a known limitation and many people offered alternative solutions to schedule jobs, including windows scheduler, free and commercial third-party applications.
My favourite SQL Server Agent replacement to date is Denny Cherry‘s Standalone SQL Agent, for two reasons:
- It uses msdb tables to read job information.
This means that jobs, schedules and the like can be scripted using the same script you would use in the other editions. - It’s open source and it was started by a person I highly respect.
However, while I still find it a great piece of software, there are a couple of downsides to take into account:
- It’s still a beta version and the project hasn’t been very active lately.
- There’s no GUI tool to edit jobs or monitor job progress.
- It fails to install when UAC is turned on
- It’s not 100% compatible with SQL Server 2012
- It doesn’t restart automatically when the SQL Server instance starts
- It requires sysadmin privileges
The UAC problem during installation is easy to solve: open an elevated command prompt and run the installer msi. Easy peasy.
As far as SQL Server 2012 is concerned, the service fails to start when connected to a 2012 instance. In the ERRORLOG file (the one you find in the Standalone SQL Agent directory, not SQL Server’s) you’ll quickly find the reason of the failure: it can’t create the stored procedure sp_help_job_SSA. I don’t know why this happens: I copied the definition of the stored procedure from a 2008 instance and it worked fine.
If you don’t have a SQL Server 2008 instance available, you can extract the definition of the stored procedure from the source code at CodePlex.
Issue 5) is a bit more tricky to tackle. When the service loses the connection to the target SQL Server instance, it won’t restart automatically and it will remain idle until you cycle the service manually. In the ERRORLOG file you’ll find a message that resembles to this:
Error connecting to SQL Instance. No connection attempt will be made until Sevice is restarted.
You can overcome this limitation using a startup stored procedure that restarts the service:
USE master
GO
EXEC sp_configure 'advanced',1
RECONFIGURE WITH OVERRIDE
EXEC sp_configure 'xp_cmdshell',1
RECONFIGURE WITH OVERRIDE
GO
USE master
GO
CREATE PROCEDURE startStandaloneSQLAgent
AS
BEGIN
SET NOCOUNT ON;
EXEC xp_cmdshell 'net stop "Standalone SQL Agent"'
EXEC xp_cmdshell 'net start "Standalone SQL Agent"'
END
GO
EXEC sp_procoption @ProcName = 'startStandaloneSQLAgent'
, @OptionName = 'startup'
, @OptionValue = 'on';
GO
However, you’ll probably notice that the SQL Server service account does not have sufficient rights to restart the service.
The following PowerShell script grants the SQL Server service account all the rights it needs. In order to run it, you need to download the code available at Rohn Edwards’ blog.
# Change to the display name of your SQL Server Express service
$service = Get-WmiObject win32_service |
where-object { $_.DisplayName -eq "SQL Server (SQLEXPRESS2008R2)" }
$serviceLogonAccount = $service.StartName
$ServiceAcl = Get-ServiceAcl "Standalone SQL Agent"
$ServiceAcl.Access
# Add an ACE allowing the service user Start and Stop service rights:
$ServiceAcl.AddAccessRule((New-AccessControlEntry -ServiceRights "Start,Stop" -Principal $serviceLogonAccount))
# Apply the modified ACL object to the service:
$ServiceAcl | Set-ServiceAcl
# Confirm the ACE was saved:
Get-ServiceAcl "Standalone SQL Agent" | select -ExpandProperty Access
After running this script from an elevated Powershell instance, you can test whether the startup stored procedure has enough privileges by invoking it manually.
If everything works as expected, you can restart the SQL Server Express instance and the Standalone SQL Agent service will restart as well.
In conclusion, Standalone SQL Agent is a good replacement for SQL Server Agent in Express edition and, while it suffers from some limitations, I still believe it’s the best option available.
Open SSMS Query Results in Excel with a Single Click
The problem
One of the tasks that I often have to complete is manipulate some data in Excel, starting from the query results in SSMS.
Excel is a very convenient tool for one-off reports, quick data manipulation, simple charts.
Unfortunately, SSMS doesn’t ship with a tool to export grid results to Excel quickly.
Excel offers some ways to import data from SQL queries, but none of those offers the rich query tools available in SSMS. A representative example is Microsoft Query: how am I supposed to edit a query in a text editor like this?

Enough said.
Actually, there are many ways to export data from SQL Server to Excel, including SSIS packages and the Import/Export wizard. Again, all those methods require writing your queries in a separate tool, often with very limited editing capabilities.
PowerQuery offers great support for data exploration, but it is a totally different beast and I don’t see it as an alternative to running SQL queries directly.
The solution
How can I edit my queries taking advantage of the query editing features of SSMS, review the results and then format the data directly in Excel?
The answer is SSMS cannot do that, but, fortunately, the good guys at Solutions Crew brought you a great tool that can do that and much more.
SSMSBoost is a free add-in that empowers SSMS with many useful features, among which exporting to Excel is just one. I highly suggest that you check out the feature list, because it’s really impressive.
Once SSMSBoost is installed, every time you right click a results grid, a context menu appears that lets you export the grid data to several formats.
No surprises, one of those formats is indeed Excel.

The feature works great, even with relatively big result sets. However, it requires 5 clicks to create the Spreadsheet file and one more click to open it in Excel:
So, where is the single click I promised in the title of this post?
The good news is that SSMSBoost can be automated combining commands in macros to accomplish complex tasks.
Here’s how to create a one-click “open in Excel” command:
First, open the SSMSBoost settings window clicking the “Extras” button.
In the “Shortcuts & Macros” tab you can edit and add macros to the toolbar or the context menu and even assign a keyboard shortcut.

Clicking the “definitions” field opens the macro editor
Select “Add” and choose the following command: “SSMSBoost.Connect.GridDataCopyTemplateAllGridsDisk3”. This command corresponds to the “Script all grids as Excel to disk” command in SSMSBoost.
Now save everything with OK and close. You will notice a new button in your toolbar:
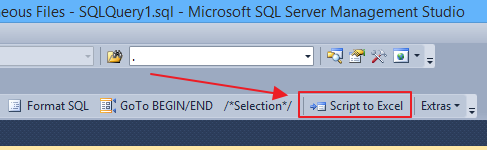
That button allows to export all grids to Excel in a single click.
You’re almost there: now you just need something to open the Excel file automatically, without the need for additional clicks.
To accomplish this task, you can use a Powershell script, bound to a custom External Tool.
Open the External Tools editor (Tools, External Tools), click “Add” and type these parameters:
Title: Open last XML in Excel
Command: C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe
Arguments: -File %USERPROFILE%\openLastExcel.ps1 -ExecutionPolicy Bypass
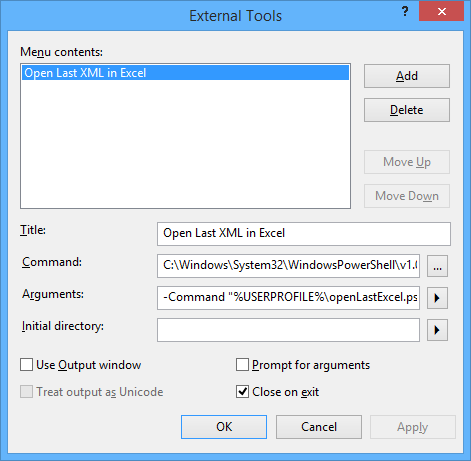
Click OK to close the External Tools editor.
This command lets you open the last XML file created in the SSMSBoost output directory, using a small Powershell script that you have to create in your %USERPROFILE% directory.
The script looks like this:
## =============================================
## Author: Gianluca Sartori - @spaghettidba
## Create date: 2014-01-15
## Description: Open the last XML file in the SSMSBoost
## output dicrectory with Excel
## =============================================
sl $env:UserProfile
# This is the SSMSBoost 2012 settings file
# If you have the 2008 version, change this path
# Sorry, I could not find a registry key to automate it.
$settingsFile = "$env:UserProfile\AppData\Local\Solutions Crew\Ssms2012\SSMSBoostSettings.xml"
# Open the settings file to look up the export directory
$xmldata=[xml](get-content $settingsFile)
$xlsTemplate = $xmldata.SSMSBoostSettings.GridDataCopyTemplates.ChildNodes |
Where-Object { $_.Name -eq "Excel (MS XML Spreadsheet)" }
$SSMSBoostPath = [System.IO.Path]::GetDirectoryName($xlsTemplate.SavePath)
$SSMSBoostPath = [System.Environment]::ExpandEnvironmentVariables($SSMSBoostPath)
# we filter out files created before (now -1 second)
$startTime = (get-date).addSeconds(-1);
$targetFile = $null;
while($targetFile -eq $null){
$targetFile = Get-ChildItem -Path $SSMSBoostPath |
Where-Object { $_.extension -eq '.xml' -and $_.lastWriteTime -gt $startTime } |
Sort-Object -Property LastWriteTime |
Select-Object -Last 1;
# file not found? Wait SSMSBoost to finish exporting
if($targetFile -eq $null) {
Start-Sleep -Milliseconds 100
}
};
$fileToOpen = $targetFile.FullName
# enclose the output file path in quotes if needed
if($fileToOpen -like "* *"){
$fileToOpen = "`"" + $fileToOpen + "`""
}
# open the file in Excel
# ShellExecute is much safer than messing with COM objects...
$sh = new-object -com 'Shell.Application'
$sh.ShellExecute('excel', "/r " + $fileToOpen, '', 'open', 1)
Now you just have to go back to the SSMSBoost settings window and edit the macro you created above.
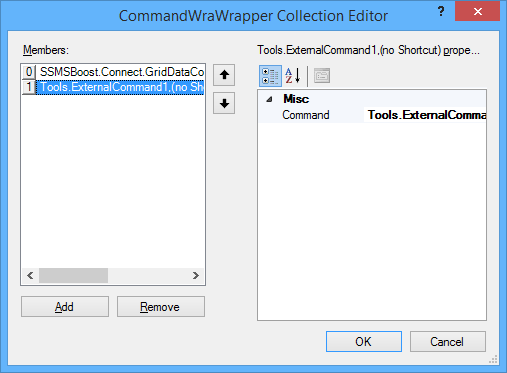
In the definitions field click … to edit the macro and add a second step. The Command to select is “Tools.ExternalCommand1”.
Save and close everything and now your nice toolbar button will be able to open the export file in Excel automagically. Yay!
Troubleshooting
If nothing happens, you might need to change your Powershell Execution Policy. Remember that SSMS is a 32-bit application and you have to set the Execution Policy for the x86 version of Powershell.
Starting Powershell x86 is not easy in Windows 8/8.1, The documentation says to look up “Windows Powershell (x86)” in the start menu, but I could not find it.
The easiest way I have found is through another External Tool in SSMS. Start SSMS as an Administrator (otherwise the UAC will prevent you from changing the Execution Policy) and configure an external tool to run Powershell. Once you’re in, type “Set-ExecutionPolicy Remotesigned” and hit return. The external tool in your macro will now run without issues.
Bottom line
Nothing compares to SSMS when it comes down to writing queries, but Excel is the best place to format and manipulate data.
Now you have a method to take advantage of the best of both worlds. And it only takes one single click.
Enjoy.
Copy user databases to a different server with PowerShell
Sometimes you have to copy all user databases from a source server to a destination server.
Copying from development to test could be one reason, but I’m sure there are others.
Since the question came up on the forums at SQLServerCentral, I decided to modify a script I published some months ago to accomplish this task.
Here is the code:
## =============================================
## Author: Gianluca Sartori - @spaghettidba
## Create date: 2013-10-07
## Description: Copy user databases to a destination
## server
## =============================================
cls
sl "c:\"
$ErrorActionPreference = "Stop"
# Input your parameters here
$source = "SourceServer\Instance"
$sourceServerUNC = "SourceServer"
$destination = "DestServer\Instance"
# Shared folder on the destination server
# For instance "\\DestServer\D$"
$sharedFolder = "\\DestServer\sharedfolder"
# Path to the shared folder on the destination server
# For instance "D:"
$remoteSharedFolder = "PathOfSharedFolderOnDestServer"
$ts = Get-Date -Format yyyyMMdd
#
# Read default backup path of the source from the registry
#
$SQL_BackupDirectory = @"
EXEC master.dbo.xp_instance_regread
N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer',
N'BackupDirectory'
"@
$info = Invoke-sqlcmd -Query $SQL_BackupDirectory -ServerInstance $source
$BackupDirectory = $info.Data
#
# Read master database files location
#
$SQL_Defaultpaths = "
SELECT *
FROM (
SELECT type_desc,
SUBSTRING(physical_name,1,LEN(physical_name) - CHARINDEX('\', REVERSE(physical_name)) + 1) AS physical_name
FROM master.sys.database_files
) AS src
PIVOT( MIN(physical_name) FOR type_desc IN ([ROWS],[LOG])) AS pvt
"
$info = Invoke-sqlcmd -Query $SQL_Defaultpaths -ServerInstance $destination
$DefaultData = $info.ROWS
$DefaultLog = $info.LOG
#
# Process all user databases
#
$SQL_FullRecoveryDatabases = @"
SELECT name
FROM master.sys.databases
WHERE name NOT IN ('master', 'model', 'tempdb', 'msdb', 'distribution')
"@
$info = Invoke-sqlcmd -Query $SQL_FullRecoveryDatabases -ServerInstance $source
$info | ForEach-Object {
try {
$DatabaseName = $_.Name
Write-Output "Processing database $DatabaseName"
$BackupFile = $DatabaseName + "_" + $ts + ".bak"
$BackupPath = $BackupDirectory + "\" + $BackupFile
$RemoteBackupPath = $remoteSharedFolder + "\" + $BackupFile
$SQL_BackupDatabase = "BACKUP DATABASE $DatabaseName TO DISK='$BackupPath' WITH INIT, COPY_ONLY, COMPRESSION;"
#
# Backup database to local path
#
Invoke-Sqlcmd -Query $SQL_BackupDatabase -ServerInstance $source -QueryTimeout 65535
Write-Output "Database backed up to $BackupPath"
$BackupPath = $BackupPath
$BackupFile = [System.IO.Path]::GetFileName($BackupPath)
$SQL_RestoreDatabase = "
RESTORE DATABASE $DatabaseName
FROM DISK='$RemoteBackupPath'
WITH RECOVERY, REPLACE,
"
$SQL_RestoreFilelistOnly = "
RESTORE FILELISTONLY
FROM DISK='$RemoteBackupPath';
"
#
# Move the backup to the destination
#
$remotesourcefile = $BackupPath.Substring(1, 2)
$remotesourcefile = $BackupPath.Replace($remotesourcefile, $remotesourcefile.replace(":","$"))
$remotesourcefile = "\\" + $sourceServerUNC + "\" + $remotesourcefile
Write-Output "Moving $remotesourcefile to $sharedFolder"
Move-Item $remotesourcefile $sharedFolder -Force
#
# Restore the backup on the destination
#
$i = 0
Invoke-Sqlcmd -Query $SQL_RestoreFilelistOnly -ServerInstance $destination -QueryTimeout 65535 | ForEach-Object {
$currentRow = $_
$physicalName = [System.IO.Path]::GetFileName($CurrentRow.PhysicalName)
if($CurrentRow.Type -eq "D") {
$newName = $DefaultData + $physicalName
}
else {
$newName = $DefaultLog + $physicalName
}
if($i -gt 0) {$SQL_RestoreDatabase += ","}
$SQL_RestoreDatabase += " MOVE '$($CurrentRow.LogicalName)' TO '$NewName'"
$i += 1
}
Write-Output "invoking restore command: $SQL_RestoreDatabase"
Invoke-Sqlcmd -Query $SQL_RestoreDatabase -ServerInstance $destination -QueryTimeout 65535
Write-Output "Restored database from $RemoteBackupPath"
#
# Delete the backup file
#
Write-Output "Deleting $($sharedFolder + "\" + $BackupFile) "
Remove-Item $($sharedFolder + "\" + $BackupFile) -ErrorAction SilentlyContinue
}
catch {
Write-Error $_
}
}
It’s a quick’n’dirty script, I’m sure there might be something to fix here and there. Just drop a comment if you find something.
Check SQL Server logins with weak password
SQL Server logins can implement the same password policies found in Active Directory to make sure that strong passwords are being used.
Unfortunately, especially for servers upgraded from previous versions, the password policies are often disabled and some logins have very weak passwords.
In particular, some logins could have the password set as equal to the login name, which would by one of the first things I would try to hack a server.
Are you sure none of your logins has such a poor password?
PowerShell to the rescue!
try {
if((Get-PSSnapin -Name SQlServerCmdletSnapin100 -ErrorAction SilentlyContinue) -eq $null){
Add-PSSnapin SQlServerCmdletSnapin100
}
}
catch {
Write-Error "This script requires the SQLServerCmdletSnapIn100 snapin"
exit
}
cls
# Query server names from your Central Management Server
$qry = "
SELECT server_name
FROM msdb.dbo.sysmanagement_shared_registered_servers
"
$servers = Invoke-Sqlcmd -Query $qry -ServerInstance "YourCMSServerGoesHere"
# Extract SQL Server logins
# Why syslogins and not sys.server_principals?
# Believe it or not, I still support a couple of SQL Server 2000
$qry_logins = "
SELECT loginname, sysadmin
FROM syslogins
WHERE isntname = 0
AND loginname NOT LIKE '##%##'
"
$dangerous_logins = @()
$servers | % {
$currentServer = $_.server_name
$logins = Invoke-Sqlcmd -Query $qry_logins -ServerInstance $currentServer
$logins | % {
$currentLogin = $_.loginname
$isSysAdmin = $_.sysadmin
try {
# Attempt logging in with login = password
$one = Invoke-Sqlcmd -Query "SELECT 1" -ServerInstance $currentServer -Username $currentLogin -Password $currentLogin -ErrorAction Stop
# OMG! Login successful
# Add the login to $dangerous_logins
$info = @{}
$info.LoginName = $currentLogin
$info.Sysadmin = $isSysAdmin
$info.ServerName = $currentServer
$loginInfo = New-Object -TypeName PsObject -Property $info
$dangerous_logins += $loginInfo
}
catch {
# If the login attempt fails, don't add the login to $dangerous_logins
}
}
}
#display dangerous logins
$dangerous_logins
Extracting DACPACs from all databases with Powershell
If you are adopting Sql Server Data Tools as your election tool to maintain database projects under source control and achieve an ALM solution, at some stage you will probably want to import all your databases in SSDT.
Yes, it can be done by hand, one at a time, using either the “import live database” or “schema compare” features, but what I have found to be more convenient is the “import dacpac” feature.
Basically, you can extract a dacpac from a live database and then import it in SSDT, entering some options in the import dialog.
The main reason why I prefer this method is the reduced amount of manual steps involved. Moreover, the dacpac extraction process can be fully automated using sqlpackage.exe.
Recently I had to import a lot of databases in SSDT and found that sqlpackage can be used in a PowerShell script to automate the process even further:
#
# Extract DACPACs from all databases
#
# Author: Gianluca Sartori - @spaghettidba
# Date: 2013/02/13
# Purpose:
# Loop through all user databases and extract
# a DACPAC file in the working directory
#
#
Param(
[Parameter(Position=0,Mandatory=$true)]
[string]$ServerName
)
cls
try {
if((Get-PSSnapin -Name SQlServerCmdletSnapin100 -ErrorAction SilentlyContinue) -eq $null){
Add-PSSnapin SQlServerCmdletSnapin100
}
}
catch {
Write-Error "This script requires the SQLServerCmdletSnapIn100 snapin"
exit
}
#
# Gather working directory (script path)
#
$script_path = Split-Path -Parent $MyInvocation.MyCommand.Definition
$sql = "
SELECT name
FROM sys.databases
WHERE name NOT IN ('master', 'model', 'msdb', 'tempdb','distribution')
"
$data = Invoke-sqlcmd -Query $sql -ServerInstance $ServerName -Database master
$data | ForEach-Object {
$DatabaseName = $_.name
#
# Run sqlpackage
#
&"C:\Program Files (x86)\Microsoft SQL Server\110\DAC\bin\sqlpackage.exe" `
/Action:extract `
/SourceServerName:$ServerName `
/SourceDatabaseName:$DatabaseName `
/TargetFile:$script_path\DACPACs\$DatabaseName.dacpac `
/p:ExtractReferencedServerScopedElements=False `
/p:IgnorePermissions=False
}
It’s a very simple script indeed, but it saved me a lot of time and I wanted to share it with you.
Unfortunately, there is no way to automate the import process in SSDT, but looks like Microsoft is actually looking into making this feature availabe in a future version.
Manual Log Shipping with PowerShell
Recently I had to implement log shipping as a HA strategy for a set of databases which were originally running under the simple recovery model.
Actually, the databases were subscribers for a merge publication, which leaves database mirroring out of the possible HA options. Clustering was not an option either, due to lack of shared storage at the subscribers.
After turning all databases to full recovery model and setting up log shipping, I started to wonder if there was a better way to implement it. Log shipping provides lots of flexibility, which I didn’t need: I just had to ship the transaction log from the primary to a single secondary and have transaction logs restored immediately. Preserving transaction log backups was not needed, because the secondary database was considered a sufficient backup in this case.
Another thing that I observed was the insane amount of memory consumed by SQLLogShip.exe (over 300 MB), which ended up even failing due to OutOfMemoryException at times.
After reading Edwin Sarmiento‘s fine chapter on SQL Server MVP Deep Dives “The poor man’s SQL Server log shipping”, some ideas started to flow.
First of all I needed a table to hold the configuration for my manual log shipping:
-- =============================================
-- Author: Gianluca Sartori - @spaghettidba
-- Create date: 2013-02-07
-- Description: Creates a table to hold manual
-- log shipping configuration
-- =============================================
CREATE TABLE msdb.dbo.ManualLogShippingConfig (
secondary sysname PRIMARY KEY CLUSTERED, -- Name of the secondary SQL Server instance
sharedBackupFolder varchar(255), -- UNC path to the backup path on the secondary
remoteBackupFolder varchar(255) -- Path to the backup folder on the secondary
-- It's the same path as sharedBackupFolder,
-- as seen from the secondary server
)
GO
INSERT INTO msdb.dbo.ManualLogShippingConfig (
secondary,
sharedBackupFolder,
remoteBackupFolder
)
VALUES (
'SomeServer',
'\\SomeShare',
'Local path of SomeShare on secondary'
)
GO
And then I just needed a PowerShell script to do the heavy lifting.
I think the code is commented and readable enough to show what happens behind the scenes.
## =============================================
## Author: Gianluca Sartori - @spaghettidba
## Create date: 2013-02-07
## Description: Ships the log to a secondary server
## =============================================
sl c:\
$ErrorActionPreference = "Stop"
$primary = "$(ESCAPE_DQUOTE(SRVR))"
#
# Read Configuration from the table in msdb
#
$SQL_Config = @"
SELECT * FROM msdb.dbo.ManualLogShippingConfig
"@
$info = Invoke-sqlcmd -Query $SQL_Config -ServerInstance $primary
$secondary = $info.secondary
$sharedFolder = $info.sharedBackupFolder
$remoteSharedFolder = $info.remoteBackupFolder
$ts = Get-Date -Format yyyyMMddHHmmss
#
# Read default backup path of the primary from the registry
#
$SQL_BackupDirectory = @"
EXEC master.dbo.xp_instance_regread
N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer',
N'BackupDirectory'
"@
$info = Invoke-sqlcmd -Query $SQL_BackupDirectory -ServerInstance $primary
$BackupDirectory = $info.Data
#
# Ship the log of all databases in FULL recovery model
# You can change this to ship a single database's log
#
$SQL_FullRecoveryDatabases = @"
SELECT name
FROM master.sys.databases
WHERE recovery_model_desc = 'FULL'
AND name NOT IN ('master', 'model', 'msdb', 'tempdb')
"@
$info = Invoke-sqlcmd -Query $SQL_FullRecoveryDatabases -ServerInstance $primary
$info | ForEach-Object {
$DatabaseName = $_.Name
Write-Output "Processing database $DatabaseName"
$BackupFile = $DatabaseName + "_" + $ts + ".trn"
$BackupPath = Join-Path $BackupDirectory $BackupFile
$RemoteBackupPath = Join-Path $remoteSharedFolder $BackupFile
$SQL_BackupDatabase = "BACKUP LOG $DatabaseName TO DISK='$BackupPath' WITH INIT;"
$SQL_NonCopiedBackups = "
SELECT physical_device_name
FROM msdb.dbo.backupset AS BS
INNER JOIN msdb.dbo.backupmediaset AS BMS
ON BS.media_set_id = BMS.media_set_id
INNER JOIN msdb.dbo.backupmediafamily AS BMF
ON BMS.media_set_id = BMF.media_set_id
WHERE BS.database_name = '$DatabaseName'
AND BS.type = 'L'
AND expiration_date IS NULL
ORDER BY BS.backup_start_date
"
#
# Backup log to local path
#
Invoke-Sqlcmd -Query $SQL_BackupDatabase -ServerInstance $primary -QueryTimeout 65535
Write-Output "LOG backed up to $BackupPath"
#
# Query noncopied backups...
#
$nonCopiedBackups = Invoke-Sqlcmd -Query $SQL_NonCopiedBackups -ServerInstance $primary
$nonCopiedBackups | ForEach-Object {
$BackupPath = $_.physical_device_name
$BackupFile = Split-Path $BackupPath -Leaf
$RemoteBackupPath = Join-Path $remoteSharedFolder $BackupFile
$SQL_RestoreDatabase = "
RESTORE LOG $DatabaseName
FROM DISK='$RemoteBackupPath'
WITH NORECOVERY;
"
$SQL_ExpireBackupSet = "
UPDATE BS
SET expiration_date = GETDATE()
FROM msdb.dbo.backupset AS BS
INNER JOIN msdb.dbo.backupmediaset AS BMS
ON BS.media_set_id = BMS.media_set_id
INNER JOIN msdb.dbo.backupmediafamily AS BMF
ON BMS.media_set_id = BMF.media_set_id
WHERE BS.database_name = '$DatabaseName'
AND BS.type = 'L'
AND physical_device_name = '$BackupPath'
"
#
# Move the transaction log backup to the secondary
#
if (Test-Path $BackupPath) {
Write-Output "Moving $BackupPath to $sharedFolder"
Move-Item -Path ("Microsoft.PowerShell.Core\FileSystem::" + $BackupPath) -Destination ("Microsoft.PowerShell.Core\FileSystem::" + $sharedFolder) -Force
}
#
# Restore the backup on the secondary
#
Invoke-Sqlcmd -Query $SQL_RestoreDatabase -ServerInstance $secondary -QueryTimeout 65535
Write-Output "Restored LOG from $RemoteBackupPath"
#
# Delete the backup file
#
Write-Output "Deleting $RemoteBackupPath"
Remove-Item $RemoteBackupPath -ErrorAction SilentlyContinue
#
# Mark the backup as expired
#
Write-Output "Expiring backup set $BackupPath"
Invoke-Sqlcmd -Query $SQL_ExpireBackupSet -ServerInstance $primary
}
}
The script can be used in a SQLAgent PowerShell job step and it’s all you need to start shipping your transaction logs.
Obviously, you need to take a full backup on the primary server and restore it to the secondary WITH NORECOVERY.
Once you’re ready, you can schedule the job to ship the transaction logs.
