Monthly Archives: April 2015
How to post a T-SQL question on a public forum
If you want to have faster turnaround on your forum questions, you will need to provide enough information to the forum users in order to answer your question.
In particular, talking about T-SQL questions, there are three things that your question must include:
- Table scripts
- Sample data
- Expected output
Table Script and Sample data
Please make sure that anyone trying to answer your question can quickly work on the same data set you’re working on, or, at least the problematic part of it. The data should be in the same place where you have it, which is inside your tables.
You will have to provide a script that creates your table and inserts data inside that table.
Converting your data to INSERT statements can be tedious: fortunately, some tools can do it for you.
How do you convert a SSMS results grid, a CSV file or an Excel spreadsheet to INSERT statements? In other words, how do you convert this…

into this?
USE [tempdb] GO CREATE TABLE [dbo].[Person]( [BusinessEntityID] [int] NOT NULL PRIMARY KEY CLUSTERED, [PersonType] [nchar](2) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL ) GO INSERT INTO Person VALUES (6106,'IN','Beth','Carlson'); INSERT INTO Person VALUES (17889,'IN','Dennis','Li'); INSERT INTO Person VALUES (17989,'IN','Brent','Li'); INSERT INTO Person VALUES (9424,'IN','Brad','Raji'); INSERT INTO Person VALUES (5842,'IN','Aimee','She'); INSERT INTO Person VALUES (2144,'GC','Carol','Philips'); INSERT INTO Person VALUES (2582,'IN','Gregory','Tang'); INSERT INTO Person VALUES (2012,'SC','Jian','Wang'); INSERT INTO Person VALUES (12624,'IN','Clayton','She'); INSERT INTO Person VALUES (12509,'IN','Madison','Russell'); GO
The easiest way to perform the transformation is to copy all the data and paste it over at ConvertCSV:
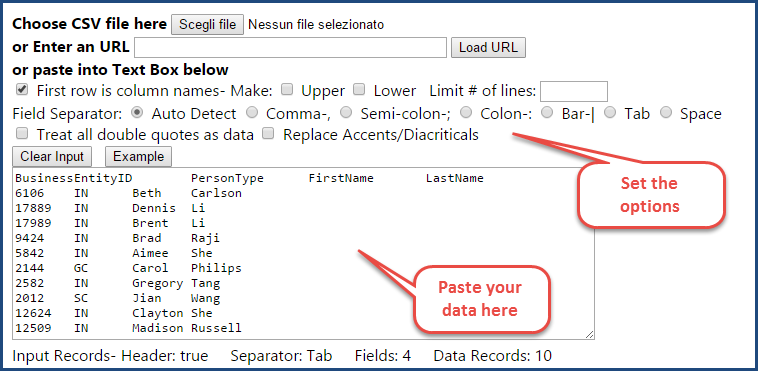


Another great tool for this task is SQLFiddle.
OPTIONAL: The insert statements will include the field names: if you want to make your code more concise, you can remove that part by selecting the column names with your mouse holding the ALT key and then delete the selection. Here’s a description of how the rectangular selection works in SSMS 2012 and 2014 (doesn’t work in SSMS 2008).
Expected output
The expected output should be something immediately readable and understandable. There’s another tool that can help you obtain it.
Go to https://ozh.github.io/ascii-tables/, paste your data in the “Input” textarea, press “Create Table” and grab your table from the “Output” textarea.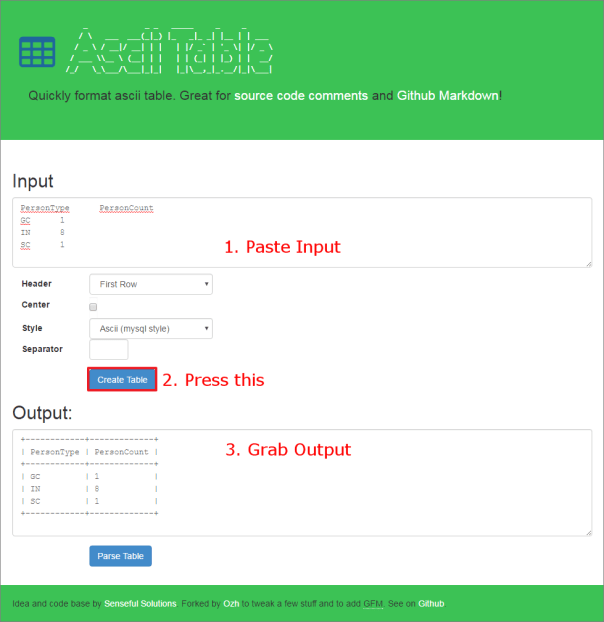 Here’s what your output should look like:
Here’s what your output should look like:
+------------+-------------+ | PersonType | PersonCount | +------------+-------------+ | GC | 1 | | IN | 8 | | SC | 1 | +------------+-------------+
Show what you have tried
Everybody will be more willing to help you if you show that you have put some effort into solving your problem. If you have a query, include it, even if it doesn’t do exactly what you’re after.
Please please please, format your query before posting! You can format your queries online for free at PoorSQL.com
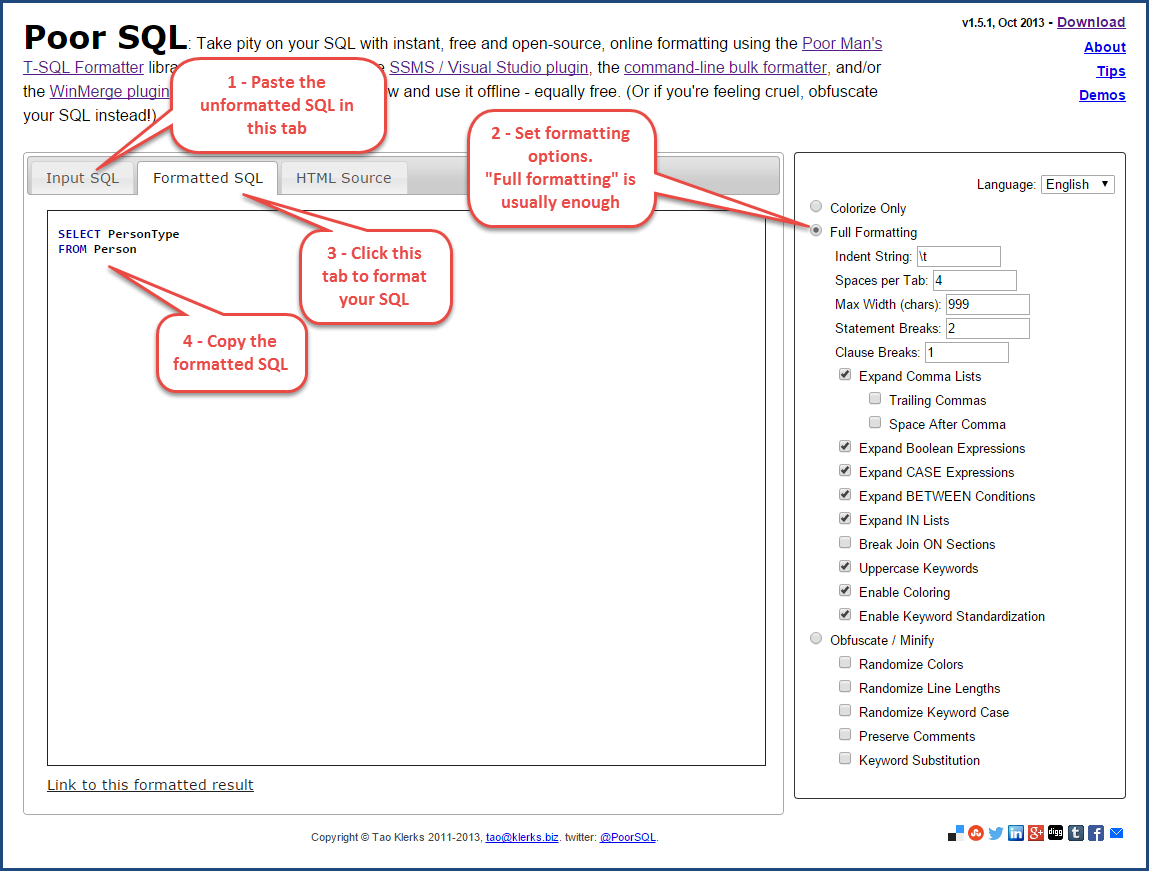
Simply paste your code then open the “Formatted SQL” tab to grab your code in a more readable way.
Putting it all together
Here is what your question should look like when everything is ok:
Hi all, I have a table called Person and I have to extract the number of rows for each person type.
This is the table script and some sample data:
USE [tempdb] GO CREATE TABLE [dbo].[Person]( [BusinessEntityID] [int] NOT NULL PRIMARY KEY CLUSTERED, [PersonType] [nchar](2) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL ) GO INSERT INTO Person VALUES (6106,'IN','Beth','Carlson'); INSERT INTO Person VALUES (17889,'IN','Dennis','Li'); INSERT INTO Person VALUES (17989,'IN','Brent','Li'); INSERT INTO Person VALUES (9424,'IN','Brad','Raji'); INSERT INTO Person VALUES (5842,'IN','Aimee','She'); INSERT INTO Person VALUES (2144,'GC','Carol','Philips'); INSERT INTO Person VALUES (2582,'IN','Gregory','Tang'); INSERT INTO Person VALUES (2012,'SC','Jian','Wang'); INSERT INTO Person VALUES (12624,'IN','Clayton','She'); INSERT INTO Person VALUES (12509,'IN','Madison','Russell');This is what I’m trying to obtain:
+------------+-------------+ | PersonType | PersonCount | +------------+-------------+ | GC | 1 | | IN | 8 | | SC | 1 | +------------+-------------+Here is what I have tried:
SELECT PersonType FROM PersonHow do I do that?
If you include this information in your posts, I promise you will get blazingly fast answers.
Tracking Table Usage and Identifying Unused Objects
One of the things I hate the most about “old” databases is the fact that unused tables are kept forever, because nobody knows whether they’re used or not. Sometimes it’s really hard to tell. Some databases are accessed by a huge number of applications, reports, ETL tools and God knows what else. In these cases, deciding whether you should drop a table or not is a tough call.
Search your codebase
The easiest way to know if a table is used, is to search the codebase for occurences of the table name. However, finding the table name in the code does not mean it is used: there are code branches that in turn are not used. Modern languages and development tools can help you identify unused methods and objects, but it’s not always feasible or 100% reliable (binary dependencies, scripts, dynamic code are, off top of my head, some exceptions).
On the other hand, not finding the table name in the code does not mean you can delete it with no issues. The table could be used by dynamic code and the name retrieved from a configuration file or a table in the database.
In other cases, the source code is not available at all.
Index usage: clues, not evidence
Another way to approach the problem is by measuring the effects of the code execution against the database, in other words, by looking at the information stored by SQL Server whenever a table is accessed.
The DMV sys.dm_db_index_usage_stats records information on all seeks, scans, lookups and updates against indexes and is a very good place to start the investigation. If something is writing to the table or reading from it, you will see the numbers go up and the dates moving forward.
Great, so we’re done and this post is over? Not exactly: there are some more facts to take into account.
First of all, the DMV gets cleared every time SQL Server is restarted, so the accuracy of the data returned is heavily dependant on how long the instance has been running. Moreover, some actions (rebuilding the index, to name one) reset the index usage stats and if you want to rely on sensible stats, your only option is to persist the data in some place regularly.
To achieve this goal, I coded this simple stored procedure that reads the stats from the DMV and stores it in a table, updating the read and write counts for each subsequent execution.
-- You have a TOOLS database, right?
-- If not, create one, you will thank me later
USE TOOLS;
GO
-- A place for everything, everything in its place
IF SCHEMA_ID('meta') IS NULL
EXEC('CREATE SCHEMA meta;')
GO
-- This table will hold index usage summarized at table level
CREATE TABLE meta.index_usage(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
)
-- This table will hold the last snapshot taken
-- It will be used to capture the snapshot and
-- merge it with the destination table
CREATE TABLE meta.index_usage_last_snapshot(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
)
GO
-- This procedure captures index usage stats
-- and merges the stats with the ones already captured
CREATE PROCEDURE meta.record_index_usage
AS
BEGIN
SET NOCOUNT ON;
IF OBJECT_ID('tempdb..#stats') IS NOT NULL
DROP TABLE #stats;
-- We will use the index stats multiple times, so parking
-- them in a temp table is convenient
CREATE TABLE #stats(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
);
-- Reads index usage stats and aggregates stats at table level
-- Aggregated data is saved in the temporary table
WITH index_stats AS (
SELECT DB_NAME(database_id) AS db_name,
OBJECT_SCHEMA_NAME(object_id,database_id) AS schema_name,
OBJECT_NAME(object_id, database_id) AS object_name,
user_seeks + user_scans + user_lookups AS read_count,
user_updates AS write_count,
last_read = (
SELECT MAX(value)
FROM (
VALUES(last_user_seek),(last_user_scan),(last_user_lookup)
) AS v(value)
),
last_write = last_user_update
FROM sys.dm_db_index_usage_stats
WHERE DB_NAME(database_id) NOT IN ('master','model','tempdb','msdb')
)
INSERT INTO #stats
SELECT db_name,
schema_name,
object_name,
SUM(read_count) AS read_count,
MAX(last_read) AS last_read,
SUM(write_count) AS write_count,
MAX(last_write) AS last_write
FROM index_stats
GROUP BY db_name,
schema_name,
object_name;
DECLARE @last_date_in_snapshot datetime;
DECLARE @sqlserver_start_date datetime;
-- reads maximum read/write date from the data already saved in the last snapshot table
SELECT @last_date_in_snapshot = MAX(CASE WHEN last_read > last_write THEN last_read ELSE last_write END)
FROM meta.index_usage_last_snapshot;
-- reads SQL Server start time
SELECT @sqlserver_start_date = sqlserver_start_time FROM sys.dm_os_sys_info;
-- handle restarted server: last snapshot is before server start time
IF (@last_date_in_snapshot) < (@sqlserver_start_date)
TRUNCATE TABLE meta.index_usage_last_snapshot;
-- handle snapshot table empty
IF NOT EXISTS(SELECT * FROM meta.index_usage_last_snapshot)
INSERT INTO meta.index_usage_last_snapshot
SELECT * FROM #stats;
-- merges data in the target table with the new collected data
WITH offset_stats AS (
SELECT newstats.db_name,
newstats.schema_name,
newstats.object_name,
-- if new < old, the stats have been reset
newstats.read_count -
CASE
WHEN newstats.read_count < ISNULL(oldstats.read_count,0) THEN 0
ELSE ISNULL(oldstats.read_count,0)
END
AS read_count,
newstats.last_read,
-- if new < old, the stats have been reset
newstats.write_count -
CASE
WHEN newstats.write_count < ISNULL(oldstats.write_count,0) THEN 0
ELSE ISNULL(oldstats.write_count,0)
END
AS write_count,
newstats.last_write
FROM #stats AS newstats
LEFT JOIN meta.index_usage_last_snapshot AS oldstats
ON newstats.db_name = oldstats.db_name
AND newstats.schema_name = oldstats.schema_name
AND newstats.object_name = oldstats.object_name
)
MERGE INTO meta.index_usage AS dest
USING offset_stats AS src
ON src.db_name = dest.db_name
AND src.schema_name = dest.schema_name
AND src.object_name = dest.object_name
WHEN MATCHED THEN
UPDATE SET read_count += src.read_count,
last_read = src.last_read,
write_count += src.write_count,
last_write = src.last_write
WHEN NOT MATCHED BY TARGET THEN
INSERT VALUES (
src.db_name,
src.schema_name,
src.object_name,
src.read_count,
src.last_read,
src.write_count,
src.last_write
);
-- empty the last snapshot
TRUNCATE TABLE meta.index_usage_last_snapshot;
-- replace it with the new collected data
INSERT INTO meta.index_usage_last_snapshot
SELECT * FROM #stats;
END
GO
You can schedule the execution of the stored procedure every hour or so and you will see data flow in the meta.index_usage_last_snapshot table. Last read/write date will be updated and the read/write counts will be incremented by comparing saved counts with the captured ones: if I had 1000 reads in the previous snapshot and I capture 1200 reads, the total reads column must be incremented by 200.
So, if I don’t find my table in this list after monitoring for some days, is it safe to assume that it can be deleted? Probably yes. More on that later.
What these stats don’t tell you is what to do when you do find the table in the list. It would be reasonable to think that the table is used, but there are several reasons why it may have ended up being read or written and not all of them will be ascribable to an application.
For instance, if a table is merge replicated, the replication agents will access it and read counts will go up. What the index usage stats tell us is that something is using a table but it says nothing about the nature of that something. If you want to find out more, you need to set up some kind of monitoring that records additional information about where reads and writes come from.
Extended Events to the rescue
For this purpose, an audit is probably too verbose, because it will record an entry for each access to each table being audited. The audit file will grow very quickly if not limited to a few objects to investigate. Moreover, audits have to be set up for each table and kept running for a reasonable time before drawing conclusions.
Audits are based on Extended Events: is there another way to do the same thing Audits do using extended events directly? Of course there is, but it’s trickier than you would expect.
First of all, the Extended Events used by the audit feature are not available directly. You’ve been hearing several times that audits use Extended Events but nobody ever told you which events they are using: the reason is that those events are not usable in a custom Extended Events session (the SecAudit package is marked as “private”). As a consequence, if you want to audit table access, you will have to use some other kind of event.
In order to find out which Extended Events provide information at the object level, we can query the sys.dm_xe_object_columns DMV:
SELECT object_name, description FROM sys.dm_xe_object_columns WHERE name = 'object_id'
As you will see, the only event that could help in this case is the lock_acquired event. Whenever a table is accessed, a lock will be taken and capturing those locks is a quick and easy way to discover activity on the tables.
Here is the definition of a session to capture locking information:
CREATE EVENT SESSION [audit_table_usage] ON SERVER
ADD EVENT sqlserver.lock_acquired (
SET collect_database_name = (0)
,collect_resource_description = (1)
ACTION(sqlserver.client_app_name, sqlserver.is_system, sqlserver.server_principal_name)
WHERE (
[package0].[equal_boolean]([sqlserver].[is_system], (0)) -- user SPID
AND [package0].[equal_uint64]([resource_type], (5)) -- OBJECT
AND [package0].[not_equal_uint64]([database_id], (32767)) -- resourcedb
AND [package0].[greater_than_uint64]([database_id], (4)) -- user database
AND [package0].[greater_than_equal_int64]([object_id], (245575913)) -- user object
AND (
[mode] = (1) -- SCH-S
OR [mode] = (6) -- IS
OR [mode] = (8) -- IX
OR [mode] = (3) -- S
OR [mode] = (5) -- X
)
)
)
WITH (
MAX_MEMORY = 20480 KB
,EVENT_RETENTION_MODE = ALLOW_MULTIPLE_EVENT_LOSS
,MAX_DISPATCH_LATENCY = 30 SECONDS
,MAX_EVENT_SIZE = 0 KB
,MEMORY_PARTITION_MODE = NONE
,TRACK_CAUSALITY = OFF
,STARTUP_STATE = OFF
);
GO
If you start this session and monitor the data captured with the “Watch live data” window, you will soon notice that a huge number of events gets captured, which means that the output will also be huge and analyzing it can become a daunting task. Saving this data to a file target is not the way to go here: is there another way?
The main point here is that there is no need for the individual events, but the interesting information is the aggregated data from those events. Ideally, you would need to group by object_id and get the maximum read or write date. If possible, counting reads and writes by object_id would be great. At a first look, it seems like a good fit for the histogram target, however you will soon discover that the histogram target can “group” on a single column, which is not what you want. Object_ids are not unique and you can have the same object_id in different databases. Moreover, the histogram target can only count events and is not suitable for other types of aggregation, such as MAX.
Streaming the events with Powershell
Fortunately, when something is not available natively, you can code your own implementation. In this case, you can use the Extended Events streaming API to attach to the session and evaluate the events as soon as they show up in the stream.
In this example, I will show you how to capture the client application name along with the database and object id and group events on these 3 fields. If you are interested in additional fields (such as host name or login name), you will need to group by those fields as well.
In the same way, if you want to aggregate additional fields, you will have to implement your own logic. In this example, I am computing the MAX aggregate for the read and write events, without computing the COUNT. The reason is that it’s not easy to predict whether the count will be accurate or not, because different kind of locks will be taken in different situations (under snapshot isolation no shared locks are taken, so you have to rely on SCH-S locks; when no dirty pages are present SQL Server takes IS locks and not S locks…).
Before going to the Powershell code, you will need two tables to store the information:
USE TOOLS;
GO
CREATE TABLE meta.table_usage_xe(
db_name sysname,
schema_name sysname,
object_name sysname,
client_app_name nvarchar(128),
last_read datetime,
last_write datetime,
PRIMARY KEY(db_name, schema_name, object_name, client_app_name)
);
CREATE TABLE meta.table_usage_xe_last_snapshot(
database_id int,
object_id int,
client_app_name nvarchar(128),
last_read datetime,
last_write datetime,
PRIMARY KEY(database_id, object_id, client_app_name)
);
Now that you have a nice place to store the aggregated information, you can start this script to capture the events and persist them.
sl $Env:Temp
#For SQL Server 2014:
Add-Type -Path 'C:\Program Files\Microsoft SQL Server\120\Shared\Microsoft.SqlServer.XE.Core.dll'
Add-Type -Path 'C:\Program Files\Microsoft SQL Server\120\Shared\Microsoft.SqlServer.XEvent.Linq.dll'
#For SQL Server 2012:
#Add-Type -Path 'C:\Program Files\Microsoft SQL Server\110\Shared\Microsoft.SqlServer.XEvent.Linq.dll'
$connectionString = 'Data Source = YourServerNameGoesHere; Initial Catalog = master; Integrated Security = SSPI'
$SessionName = "audit_table_usage"
# loads all object ids for table objects and their database id
# table object_ids will be saved in order to rule out whether
# the locked object is a table or something else.
$commandText = "
DECLARE @results TABLE (
object_id int,
database_id int
);
DECLARE @sql nvarchar(max);
SET @sql = '
SELECT object_id, db_id()
FROM sys.tables t
WHERE is_ms_shipped = 0
';
DECLARE @statement nvarchar(max);
SET @statement = (
SELECT 'EXEC ' + QUOTENAME(name) + '.sys.sp_executesql @sql; '
FROM sys.databases d
WHERE name NOT IN ('master','model','msdb','tempdb')
FOR XML PATH(''), TYPE
).value('.','nvarchar(max)');
INSERT @results
EXEC sp_executesql @statement, N'@sql nvarchar(max)', @sql;
SELECT *
FROM @results
"
$objCache = @{}
$conn = New-Object -TypeName System.Data.SqlClient.SqlConnection -ArgumentList $connectionString
$cmd = New-Object -TypeName System.Data.SqlClient.SqlCommand
$cmd.CommandText = $commandText
$cmd.Connection = $conn
$conn.Open()
$conn.ChangeDatabase("master")
$rdr = $cmd.ExecuteReader()
# load table object_ids and store them in a hashtable
while ($rdr.Read()) {
$objId = $rdr.GetInt32(0)
$dbId = $rdr.GetInt32(1)
if(-not $objCache.ContainsKey($objId)){
$objCache.add($objId,@($dbId))
}
else {
$arr = $objCache.Get_Item($objId)
$arr += $dbId
$objCache.set_Item($objId, $arr)
}
}
$conn.Close()
# create a DataTable to hold lock information in memory
$queue = New-Object -TypeName System.Data.DataTable
$queue.TableName = $SessionName
[Void]$queue.Columns.Add("database_id",[Int32])
[Void]$queue.Columns.Add("object_id",[Int32])
[Void]$queue.Columns.Add("client_app_name",[String])
[Void]$queue.Columns.Add("last_read",[DateTime])
[Void]$queue.Columns.Add("last_write",[DateTime])
# create a DataView to perform searches in the DataTable
$dview = New-Object -TypeName System.Data.DataView
$dview.Table = $queue
$dview.Sort = "database_id, client_app_name, object_id"
$last_dump = [DateTime]::Now
# connect to the Extended Events session
[Microsoft.SqlServer.XEvent.Linq.QueryableXEventData] $events = New-Object -TypeName Microsoft.SqlServer.XEvent.Linq.QueryableXEventData `
-ArgumentList @($connectionString, $SessionName, [Microsoft.SqlServer.XEvent.Linq.EventStreamSourceOptions]::EventStream, [Microsoft.SqlServer.XEvent.Linq.EventStreamCacheOptions]::DoNotCache)
$events | % {
$currentEvent = $_
$database_id = $currentEvent.Fields["database_id"].Value
$client_app_name = $currentEvent.Actions["client_app_name"].Value
if($client_app_name -eq $null) { $client_app_name = [string]::Empty }
$object_id = $currentEvent.Fields["object_id"].Value
$mode = $currentEvent.Fields["mode"].Value
# search the object id in the object cache
# if found (and database id matches) ==> table
# otherwise ==> some other kind of object (not interesting)
if($objCache.ContainsKey($object_id) -and $objCache.Get_Item($object_id) -contains $database_id)
{
# search the DataTable by database_id, client app name and object_id
$found_rows = $dview.FindRows(@($database_id, $client_app_name, $object_id))
# if not found, add a row
if($found_rows.Count -eq 0){
$current_row = $queue.Rows.Add()
$current_row["database_id"] = $database_id
$current_row["client_app_name"] = $client_app_name
$current_row["object_id"] = $object_id
}
else {
$current_row = $found_rows[0]
}
if(($mode.Value -eq "IX") -or ($mode.Value -eq "X")) {
# Exclusive or Intent-Exclusive lock: count this as a write
$current_row["last_write"] = [DateTime]::Now
}
else {
# Shared or Intent-Shared lock: count this as a read
# SCH-S locks counted here as well (snapshot isolation ==> no shared locks)
$current_row["last_read"] = [DateTime]::Now
}
}
$ts = New-TimeSpan -Start $last_dump -End (get-date)
# Dump to database every 5 minutes
if($ts.TotalMinutes -gt 5) {
$last_dump = [DateTime]::Now
# BCP data to the staging table TOOLS.meta.table_usage_xe_last_snapshot
$bcp = New-Object -TypeName System.Data.SqlClient.SqlBulkCopy -ArgumentList @($connectionString)
$bcp.DestinationTableName = "TOOLS.meta.table_usage_xe_last_snapshot"
$bcp.Batchsize = 1000
$bcp.BulkCopyTimeout = 0
$bcp.WriteToServer($queue)
# Merge data with the destination table TOOLS.meta.table_usage_xe
$statement = "
BEGIN TRANSACTION
BEGIN TRY
MERGE INTO meta.table_usage_xe AS dest
USING (
SELECT db_name(database_id) AS db_name,
object_schema_name(object_id, database_id) AS schema_name,
object_name(object_id, database_id) AS object_name,
client_app_name,
last_read,
last_write
FROM meta.table_usage_xe_last_snapshot
) AS src
ON src.db_name = dest.db_name
AND src.schema_name = dest.schema_name
AND src.object_name = dest.object_name
AND src.client_app_name = dest.client_app_name
WHEN MATCHED THEN
UPDATE SET last_read = src.last_read,
last_write = src.last_write
WHEN NOT MATCHED THEN
INSERT (db_name, schema_name, object_name, client_app_name, last_read, last_write)
VALUES (db_name, schema_name, object_name, client_app_name, last_read, last_write);
TRUNCATE TABLE meta.table_usage_xe_last_snapshot;
COMMIT;
END TRY
BEGIN CATCH
ROLLBACK;
THROW;
END CATCH
"
$conn = New-Object -TypeName System.Data.SqlClient.SqlConnection -ArgumentList $connectionString
$cmd = New-Object -TypeName System.Data.SqlClient.SqlCommand
$cmd.CommandText = $statement
$cmd.Connection = $conn
$conn.Open()
$conn.ChangeDatabase("TOOLS")
[Void]$cmd.ExecuteNonQuery()
$conn.Close()
$queue.Rows.Clear()
}
}
WARNING: Be careful running this script against a production server: I tried it with a reasonaly busy server and the CPU/memory load of powershell.exe is non-negligible. On the other hand, the load imposed by the session per se is very low: make sure you run this script from a different machine and not on the database server.
What to do with unused objects
After monitoring for a reasonable amount of time, you will start to notice that some objects are never used and you will probably want to delete them. Don’t!
In my experience, as soon as you delete an object, something that uses it (and you didn’t capture) pops up and fails. In those cases, you want to restore the objects very quickly. I usually move everything to a “trash” schema and have it sitting there for some time (six months/one year) and eventually empty the trash. If somebody asks for a restore, it’s just as simple as an ALTER SCHEMA … TRANSFER statement.
Bottom line
Cleaning up clutter from a database is not simple: hopefully the techniques in this post will help you in the task. Everything would be much simpler if the Extended Events histogram target was more flexible, but please keep in mind that it’s not about the tools: these techniques can help you identify unused objects when no other information is available, but nothing is a good substitute for a correct use of the database. When new tables are added to a database, keep track of the request and take notes about who uses the tables for which purpose: everything will be much easier in the long run.
