Category Archives: T-SQL
How To Enlarge Your Columns With No Downtime
Let’s face it: column enlargement is a very sensitive topic. I get thousands of emails every month on this particular topic, although most of them end up in my spam folder. Go figure…
The inconvenient truth is that enlarging a fixed size column is a long and painful operation, that will make you wish there was a magic lotion or pill to use on your column to enlarge it on the spot.

Unfortunately, there is no such magic pill, but turns out you can use some SQL Server features to make the column enlargement less painful for your users.
First, let’s create a table with one smallint column, that we will try to enlarge later.
-- Go to a safe place
USE tempdb;
GO
IF OBJECT_ID('EnlargeTest') IS NOT NULL
DROP TABLE EnlargeTest;
-- Create test table
CREATE TABLE EnlargeTest (
SomeColumn smallint
);
-- Insert 1 million rows
INSERT INTO EnlargeTest (SomeColumn)
SELECT TOP(1000000) 1
FROM master.dbo.spt_values AS A
CROSS JOIN master.dbo.spt_values AS B;
If you try to enlarge this column with a straight “ALTER TABLE” command, you will have to wait for SQLServer to go through all the rows and write the new data type. Smallint is a data type that is stored in 2 bytes, while int requires 4 bytes, so SQL Server will have to enlarge each and every row to accommodate 2 extra bytes.
This operation requires some time and also causes a lot of page splits, especially if the pages are completely full.
SET STATISTICS IO, TIME ON; -- Enlarge column ALTER TABLE EnlargeTest ALTER COLUMN SomeColumn int; SET STATISTICS IO, TIME OFF; /* (1000000 rows affected) SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. Table 'EnlargeTest'. Scan count 9, logical reads 3001171, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 8, logical reads 2064041, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 13094 ms, elapsed time = 11012 ms. */
The worst part of this approach is that, while the ALTER TABLE statement is running, nobody can access the table.
To overcome this inconvenience, there is a magic column enlargement pill that your table can take, and it’s called Row Compression.
Row compression pills. They used to be expensive, SQL Server 2016 SP1 made them cheap.
Let’s try and revert to the original column size and take the Row Compression pill:
-- Let's revert to smallint ALTER TABLE EnlargeTest ALTER COLUMN SomeColumn smallint; -- Add row compression ALTER TABLE EnlargeTest REBUILD WITH (DATA_COMPRESSION = ROW);
With Row Compression, your fixed size columns can use only the space needed by the smallest data type where the actual data fits. This means that for an int column that contains only smallint data, the actual space usage inside the row is 1 or 2 bytes, not 4.
This is exactly what you need here:
SET STATISTICS IO, TIME ON; -- Let's try to enlarge the column again ALTER TABLE EnlargeTest ALTER COLUMN SomeColumn int; SET STATISTICS IO, TIME OFF; /* SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. */
Excellent! This time the command completes instantly and the ALTER COLUMN statement is a metadata only change.
The good news is that Row Compression is available in all editions of SQL Server since version 2016 SP1 and compression can be applied by rebuilding indexes ONLINE, with no downtime (yes, you will need Enteprise Edition for this).
The (relatively) bad news is that I tested this method on several versions of SQL Server and it only works on 2016 and above. Previous versions are not smart enough to take the compression options into account when enlarging the columns and they first enlarge and then reduce the columns when executing the ALTER COLUMN command. Another downside to this method is that row compression will refuse to work if the total size of your columns exceeds 8060 bytes, as the documentation states.
Bottom line is: painless column enlargement is possible, if you take the Row Compression pills. Just don’t overdo it: you don’t want to enlarge your columns too much, do you?
Counting the number of rows in a table
Don’t be fooled by the title of this post: while counting the number of rows in a table is a trivial task for you, it is not trivial at all for SQL Server.
Every time you run your COUNT(*) query, SQL Server has to scan an index or a heap to calculate that seemingly innocuous number and send it to your application. This means a lot of unnecessary reads and unnecessary blocking.
Jes Schultz Borland blogged about it some time ago and also Aaron Bertrand has a blog post on this subject. I will refrain from repeating here what they both said: go read their blogs to understand why COUNT(*) is a not a good tool for this task.
The alternative to COUNT(*) is reading the count from the table metadata, querying sys.partitions, something along these lines:
SELECT SUM(p.rows)
FROM sys.partitions p
WHERE p.object_id = OBJECT_ID('MyTable')
AND p.index_id IN (0,1); -- heap or clustered index
Many variations of this query include JOINs to sys.tables, sys.schemas or sys.indexes, which are not strictly necessary in my opinion. However, the shortest version of the count is still quite verbose and error prone.
Fortunately, there’s a shorter version of this query that relies on the system function OBJECTPROPERTYEX:
SELECT OBJECTPROPERTYEX(OBJECT_ID('MyTable'),'cardinality')
Where does it read data from? STATISTICS IO doesn’t return anything for this query, so I had to set up an Extended Events session to capture lock_acquired events and find out the system tables read by this function:

Basically, it’s just sysallocunits and sysrowsets.
It’s nice, short and easy to remember. Enjoy.
How to post a T-SQL question on a public forum
If you want to have faster turnaround on your forum questions, you will need to provide enough information to the forum users in order to answer your question.
In particular, talking about T-SQL questions, there are three things that your question must include:
- Table scripts
- Sample data
- Expected output
Table Script and Sample data
Please make sure that anyone trying to answer your question can quickly work on the same data set you’re working on, or, at least the problematic part of it. The data should be in the same place where you have it, which is inside your tables.
You will have to provide a script that creates your table and inserts data inside that table.
Converting your data to INSERT statements can be tedious: fortunately, some tools can do it for you.
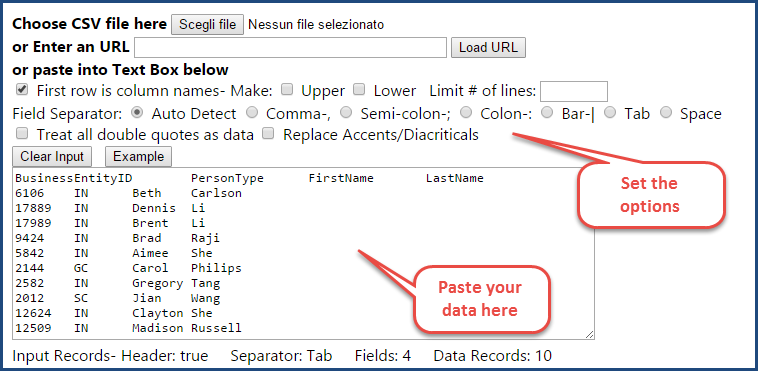
How do you convert a SSMS results grid, a CSV file or an Excel spreadsheet to INSERT statements? In other words, how do you convert this…

into this?
USE [tempdb] GO CREATE TABLE [dbo].[Person]( [BusinessEntityID] [int] NOT NULL PRIMARY KEY CLUSTERED, [PersonType] [nchar](2) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL ) GO INSERT INTO Person VALUES (6106,'IN','Beth','Carlson'); INSERT INTO Person VALUES (17889,'IN','Dennis','Li'); INSERT INTO Person VALUES (17989,'IN','Brent','Li'); INSERT INTO Person VALUES (9424,'IN','Brad','Raji'); INSERT INTO Person VALUES (5842,'IN','Aimee','She'); INSERT INTO Person VALUES (2144,'GC','Carol','Philips'); INSERT INTO Person VALUES (2582,'IN','Gregory','Tang'); INSERT INTO Person VALUES (2012,'SC','Jian','Wang'); INSERT INTO Person VALUES (12624,'IN','Clayton','She'); INSERT INTO Person VALUES (12509,'IN','Madison','Russell'); GO
The easiest way to perform the transformation is to copy all the data and paste it over at ConvertCSV:


Another great tool for this task is SQLFiddle.
OPTIONAL: The insert statements will include the field names: if you want to make your code more concise, you can remove that part by selecting the column names with your mouse holding the ALT key and then delete the selection. Here’s a description of how the rectangular selection works in SSMS 2012 and 2014 (doesn’t work in SSMS 2008).
Expected output
The expected output should be something immediately readable and understandable. There’s another tool that can help you obtain it.
Go to https://ozh.github.io/ascii-tables/, paste your data in the “Input” textarea, press “Create Table” and grab your table from the “Output” textarea.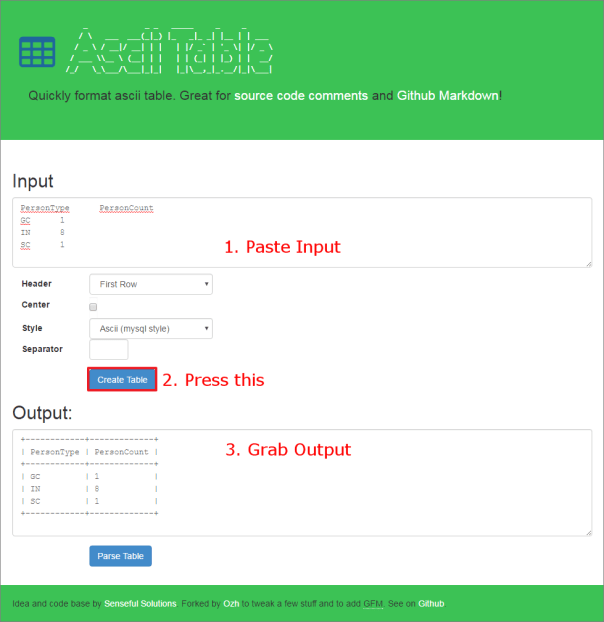 Here’s what your output should look like:
Here’s what your output should look like:
+------------+-------------+ | PersonType | PersonCount | +------------+-------------+ | GC | 1 | | IN | 8 | | SC | 1 | +------------+-------------+
Show what you have tried
Everybody will be more willing to help you if you show that you have put some effort into solving your problem. If you have a query, include it, even if it doesn’t do exactly what you’re after.
Please please please, format your query before posting! You can format your queries online for free at PoorSQL.com
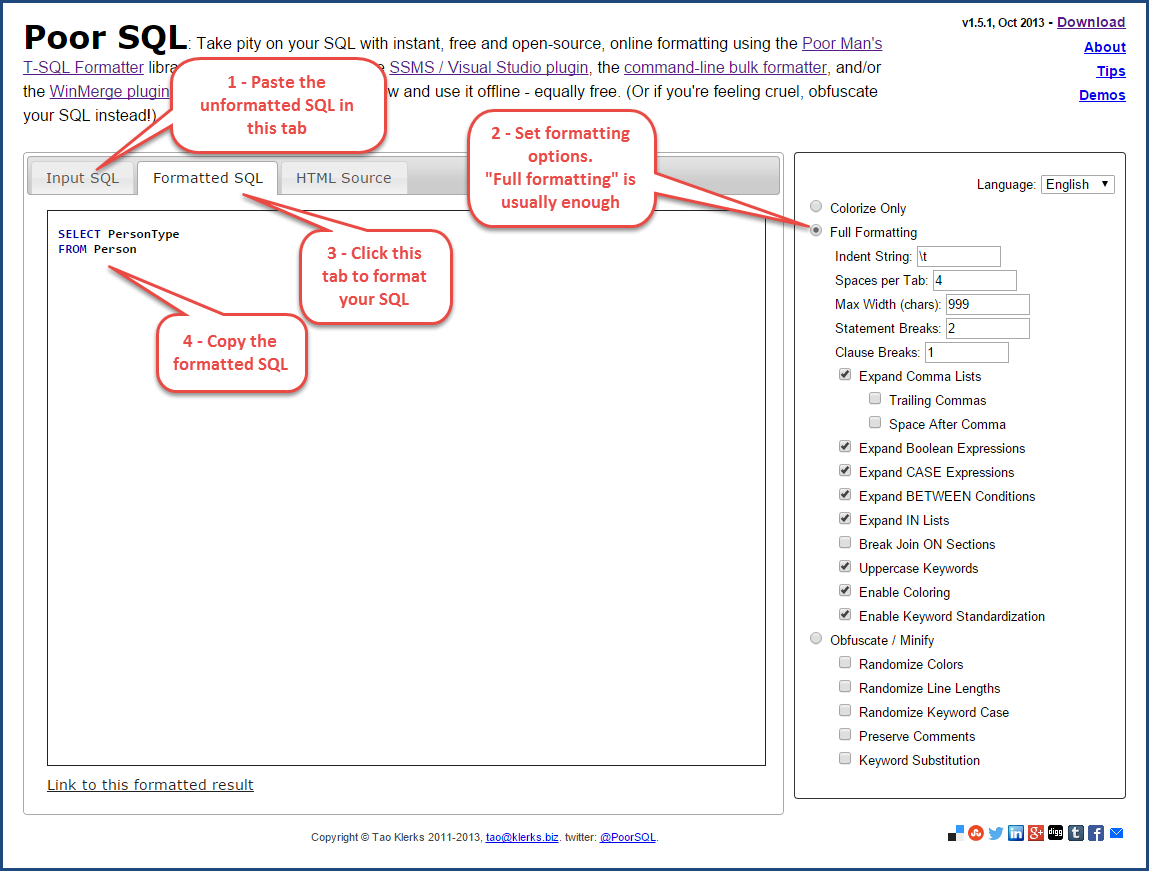
Simply paste your code then open the “Formatted SQL” tab to grab your code in a more readable way.
Putting it all together
Here is what your question should look like when everything is ok:
Hi all, I have a table called Person and I have to extract the number of rows for each person type.
This is the table script and some sample data:
USE [tempdb] GO CREATE TABLE [dbo].[Person]( [BusinessEntityID] [int] NOT NULL PRIMARY KEY CLUSTERED, [PersonType] [nchar](2) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL ) GO INSERT INTO Person VALUES (6106,'IN','Beth','Carlson'); INSERT INTO Person VALUES (17889,'IN','Dennis','Li'); INSERT INTO Person VALUES (17989,'IN','Brent','Li'); INSERT INTO Person VALUES (9424,'IN','Brad','Raji'); INSERT INTO Person VALUES (5842,'IN','Aimee','She'); INSERT INTO Person VALUES (2144,'GC','Carol','Philips'); INSERT INTO Person VALUES (2582,'IN','Gregory','Tang'); INSERT INTO Person VALUES (2012,'SC','Jian','Wang'); INSERT INTO Person VALUES (12624,'IN','Clayton','She'); INSERT INTO Person VALUES (12509,'IN','Madison','Russell');This is what I’m trying to obtain:
+------------+-------------+ | PersonType | PersonCount | +------------+-------------+ | GC | 1 | | IN | 8 | | SC | 1 | +------------+-------------+Here is what I have tried:
SELECT PersonType FROM PersonHow do I do that?
If you include this information in your posts, I promise you will get blazingly fast answers.
Installing SQL Server 2014 Language Reference Help from disk
Some weeks ago I had to wipe my machine and reinstall everything from scratch, SQL Server included.
For some reason that I still don’t understand, SQL Server Management Studio installed fine, but I couldn’t install Books Online from the online help repository. Unfortunately, installing from offline is not an option with SQL Server 2014, because the installation media doesn’t include the Language Reference documentation.
The issue is well known: Aaron Bertrand blogged about it back in april when SQL Server 2014 came out and he updated his post in august when the documentation was finally completely published. He also blogged about it at SQLSentry.
However, I couldn’t get that method to work: the Help Library Manager kept firing errors as soon as I clicked the “Install from Online” link. The error message was “An exception has occurred. See the event log for details.”
Needless to say that the event log had no interesting information to add.
If you are experiencing the same issue, here is a method to install the language reference from disk without downloading the help content from the Help Library Manager:
1 . Open a web browser and point it to the following url: http://services.mtps.microsoft.com/ServiceAPI/products/dd433097/dn632688/books/dn754848/en-us
2. Download the individual .cab files listed in that page to a location in your disk (e.g. c:\temp\langref\)
3. Create a text file name HelpContentSetup.msha in the same folder as the .cab files and paste the following html:
<html xmlns="http://www.w3.org/1999/xhtml">
<head />
<body class="vendor-book">
<div class="details">
<span class="vendor">Microsoft</span>
<span class="locale">en-us</span>
<span class="product">SQL Server 2014</span>
<span class="name">Microsoft SQL Server Language Reference</span>
</div>
<div class="package-list">
<div class="package">
<span class="name">SQL_Server_2014_Books_Online_B4164_SQL_120_en-us_1</span>
<span class="deployed">False</span>
<a class="current-link" href="sql_server_2014_books_online_b4164_sql_120_en-us_1(0b10b277-ad40-ef9d-0d66-22173fb3e568).cab">sql_server_2014_books_online_b4164_sql_120_en-us_1(0b10b277-ad40-ef9d-0d66-22173fb3e568).cab</a>
</div>
<div class="package">
<span class="name">SQL_Server_2014_Microsoft_SQL_Server_Language_Reference_B4246_SQL_120_en-us_1</span>
<span class="deployed">False</span>
<a class="current-link" href="sql_server_2014_microsoft_sql_server_language_reference_b4246_sql_120_en-us_1(5c1ad741-d0e3-a4a8-d9c0-057e2ddfa6e1).cab">sql_server_2014_microsoft_sql_server_language_reference_b4246_sql_120_en-us_1(5c1ad741-d0e3-a4a8-d9c0-057e2ddfa6e1).cab</a>
</div>
<div class="package">
<span class="name">SQL_Server_2014_Microsoft_SQL_Server_Language_Reference_B4246_SQL_120_en-us_2</span>
<span class="deployed">False</span>
<a class="current-link" href="sql_server_2014_microsoft_sql_server_language_reference_b4246_sql_120_en-us_2(24815f90-9e36-db87-887b-cf20727e5e73).cab">sql_server_2014_microsoft_sql_server_language_reference_b4246_sql_120_en-us_2(24815f90-9e36-db87-887b-cf20727e5e73).cab</a>
</div>
</div>
</body>
</html>
4 . Open the Help Library Manager and select “Install content from disk”
5. Browse to the .msha you just created and click Next

6. The SQL Server 2014 node will appear. Click the Add link
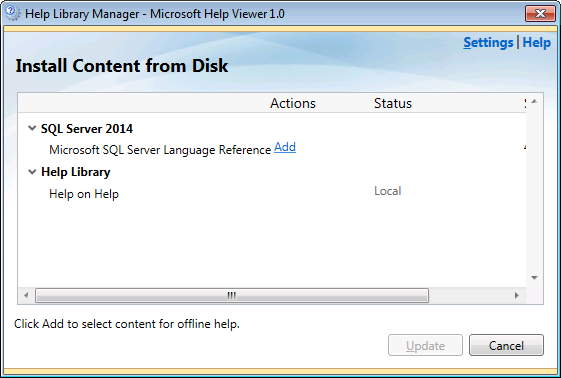
7. Click the Update button and let the installation start

8. Installation will start and process the cab files

9. Installation finished!
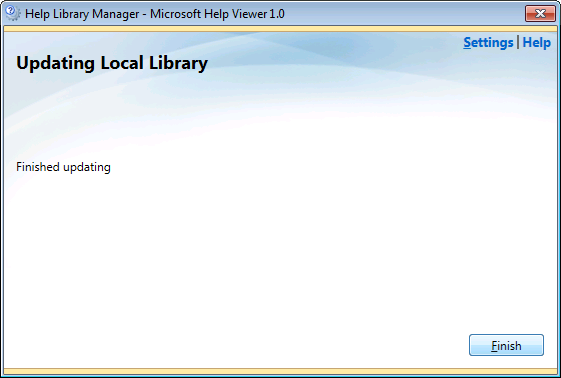
9. To check whether everything is fine, click on the “remove content” link and you should see the documentation.

Done! It was easy after all, wasn’t it?
Database Free Space Monitoring – The right way
Lately I spent some time evaluating some monitoring tools for SQL Server and one thing that struck me very negatively is how none of them (to date) has been reporting database free space correctly.
I was actively evaluating one of those tools when one of my production databases ran out of space without any sort of warning.
I was so upset that I decided to code my own monitoring script.
Some things to take into account:
- Hard set limits for file growth have to be considered: a drive with lots of space is useless if the database file cannot grow and take it.
- If fixed growth is used, there must be enough space in the drive to accomodate the growth amount you set.
- If percent growth is used, you have to calculate recursively how much your database file will grow before taking all the space in the drive
- Some scripts found in blogs and books don’t account for mount points. Use
sys.dm_os_volume_statsto include mount points in your calculation (unless you’re running SQL Server versions prior to 2012). - Database free space alone is not enough. NTFS performance start degrading when the drive free space drops below 20%. Make sure you’re monitoring that as well.
- 20% of a huge database can be lots of space. You can change that threshold to whatever you find appropriate (for instance, less than 20% AND less than 20 GB)
That said, here is my script, I hope you find it useful.
-- create a temporary table to hold data from sys.master_files
IF OBJECT_ID('tempdb..#masterfiles') IS NOT NULL
DROP TABLE #masterfiles;
CREATE TABLE #masterfiles (
database_id int,
type_desc varchar(10),
name sysname,
physical_name varchar(255),
size_mb int,
max_size_mb int,
growth int,
is_percent_growth bit,
data_space_id int,
data_space_name nvarchar(128) NULL,
drive nvarchar(512),
mbfree int
);
-- extract file information from sys.master_files
-- and correlate each file to its logical volume
INSERT INTO #masterfiles
SELECT
mf.database_id
,type_desc
,name
,physical_name
,size_mb = size / 128
,max_size_mb =
CASE
WHEN max_size = 268435456 AND type_desc = 'LOG' THEN -1
ELSE
CASE
WHEN max_size = -1 THEN -1
ELSE max_size / 128
END
END
,mf.growth
,mf.is_percent_growth
,mf.data_space_id
,NULL
,d.volume_mount_point
,d.available_bytes / 1024 / 1024
FROM sys.master_files AS mf
CROSS APPLY sys.dm_os_volume_stats(database_id, file_id) AS d;
-- add an "emptyspace" column to hold empty space for each file
ALTER TABLE #masterfiles ADD emptyspace_mb int NULL;
-- iterate through all databases to calculate empty space for its files
DECLARE @name sysname;
DECLARE c CURSOR FORWARD_ONLY READ_ONLY STATIC LOCAL
FOR
SELECT name
FROM sys.databases
WHERE state_desc = 'ONLINE'
OPEN c
FETCH NEXT FROM c INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @sql nvarchar(max)
DECLARE @statement nvarchar(max)
SET @sql = '
UPDATE mf
SET emptyspace_mb = size_mb - FILEPROPERTY(name,''SpaceUsed'') / 128,
data_space_name =
ISNULL(
(SELECT name FROM sys.data_spaces WHERE data_space_id = mf.data_space_id),
''LOG''
)
FROM #masterfiles AS mf
WHERE database_id = DB_ID();
'
SET @statement = 'EXEC ' + QUOTENAME(@name) + '.sys.sp_executesql @sql'
EXEC sp_executesql @statement, N'@sql nvarchar(max)', @sql
FETCH NEXT FROM c INTO @name
END
CLOSE c
DEALLOCATE c
-- create a scalar function to simulate the growth of the database in the drive's available space
IF OBJECT_ID('tempdb..calculateAvailableSpace') IS NOT NULL
EXEC tempdb.sys.sp_executesql N'DROP FUNCTION calculateAvailableSpace'
EXEC tempdb.sys.sp_executesql N'
CREATE FUNCTION calculateAvailableSpace(
@diskFreeSpaceMB float,
@currentSizeMB float,
@growth float,
@is_percent_growth bit
)
RETURNS int
AS
BEGIN
IF @currentSizeMB = 0
SET @currentSizeMB = 1
DECLARE @returnValue int = 0
IF @is_percent_growth = 0
BEGIN
SET @returnValue = (@growth /128) * CAST((@diskFreeSpaceMB / (ISNULL(NULLIF(@growth,0),1) / 128)) AS int)
END
ELSE
BEGIN
DECLARE @prevsize AS float = 0
DECLARE @calcsize AS float = @currentSizeMB
WHILE @calcsize < @diskFreeSpaceMB
BEGIN
SET @prevsize = @calcsize
SET @calcsize = @calcsize + @calcsize * @growth / 100.0
END
SET @returnValue = @prevsize - @currentSizeMB
IF @returnValue < 0
SET @returnValue = 0
END
RETURN @returnValue
END
'
-- report database filegroups with less than 20% available space
;WITH masterfiles AS (
SELECT *
,available_space =
CASE mf.max_size_mb
WHEN -1 THEN tempdb.dbo.calculateAvailableSpace(mbfree, size_mb, growth, is_percent_growth)
ELSE max_size_mb - size_mb
END
+ emptyspace_mb
FROM #masterfiles AS mf
),
spaces AS (
SELECT
DB_NAME(database_id) AS database_name
,data_space_name
,type_desc
,SUM(size_mb) AS size_mb
,SUM(available_space) AS available_space_mb
,SUM(available_space) * 100 /
CASE SUM(size_mb)
WHEN 0 THEN 1
ELSE SUM(size_mb)
END AS available_space_percent
FROM masterfiles
GROUP BY DB_NAME(database_id)
,data_space_name
,type_desc
)
SELECT *
FROM spaces
WHERE available_space_percent < 20
ORDER BY available_space_percent ASC
IF OBJECT_ID('tempdb..#masterfiles') IS NOT NULL
DROP TABLE #masterfiles;
IF OBJECT_ID('tempdb..calculateAvailableSpace') IS NOT NULL
EXEC tempdb.sys.sp_executesql N'DROP FUNCTION calculateAvailableSpace'
I am sure that there are smarter scripts around that calculate it correctly and I am also sure that there are other ways to obtain the same results (PowerShell, to name one). The important thing is that your script takes every important aspect into account and warns you immediately when the database space drops below your threshold, not when the available space is over.
Last time it happened to me it was a late saturday night and, while I really love my job, I can come up with many better ways to spend my saturday night.
I'm pretty sure you do as well.
Announcing ExtendedTSQLCollector
I haven’t been blogging much lately, actually I haven’t been blogging at all in the last 4 months. The reason behind is I have been putting all my efforts in a new project I started recently, which absorbed all my attention and spare time.
I am proud to announce that my project is now live and available to everyone for download.
 The project name is ExtendedTSQLCollector and you can find it at http://extendedtsqlcollector.codeplex.com. As you may have already guessed, it’s a bridge between two technologies that were not meant to work together, that could instead bring great advantages when combined: Extended Events and Data Collector.
The project name is ExtendedTSQLCollector and you can find it at http://extendedtsqlcollector.codeplex.com. As you may have already guessed, it’s a bridge between two technologies that were not meant to work together, that could instead bring great advantages when combined: Extended Events and Data Collector.
ExtendedTSQLCollector is a set of two Collector Types built to overcome some of the limitations found in the built-in collector types and extend their functionality to include the ability to collect data from XE sessions.
The first Collector Type is the “Extended T-SQL Query” collector type, which was my initial goal when I started the project. If you have had the chance to play with the built-in “Generic T-SQL Query” collector type, you may have noticed that not all datatypes are supported. For instance, it’s impossible to collect data from XML or varchar(max) columns. This is due to the intermediate format used by this collector type: the SSIS raw files.
The “Extended T-SQL Query” collector type uses a different intermediate format, which allows collecting data of any data type. This is particularly useful, because SQL Server exposes lots of information in XML format (just think of the execution plans!) and you no longer need to code custom SSIS packages to collect that data.
The second Collector Type is the “Extended XE Reader” collector type, which takes advantage of the Extended Events streaming APIs to collect data from an Extended Events session, without the need to specify additional targets such as .xel files or ring buffers. This means no file system bloat due to .xel rollover files and no memory consumption for additional ring buffers: all the events are read directly from the session and processed in near real-time.
In addition to the filter predicates defined in the XE session, you can add more filter predicates on the data to collect and upload to the MDW and decide which columns (fields and actions) to collect. The collector will take care of creating the target table in your MDW database and upload all the data that satisfies the filter predicates.
The near real-time behavior of this collector type allowed me to include an additional feature to the mix: the ability to fire alerts in response to Extended Events. The current release (1.5) allows firing email alerts when the events are captured, with additional filter predicates and the ability to include event fields and actions in the email body. You can find more information on XE alerts in the documentation.
Here is an example of the email alerts generated by the XEReader collector type for the blocked_process event:
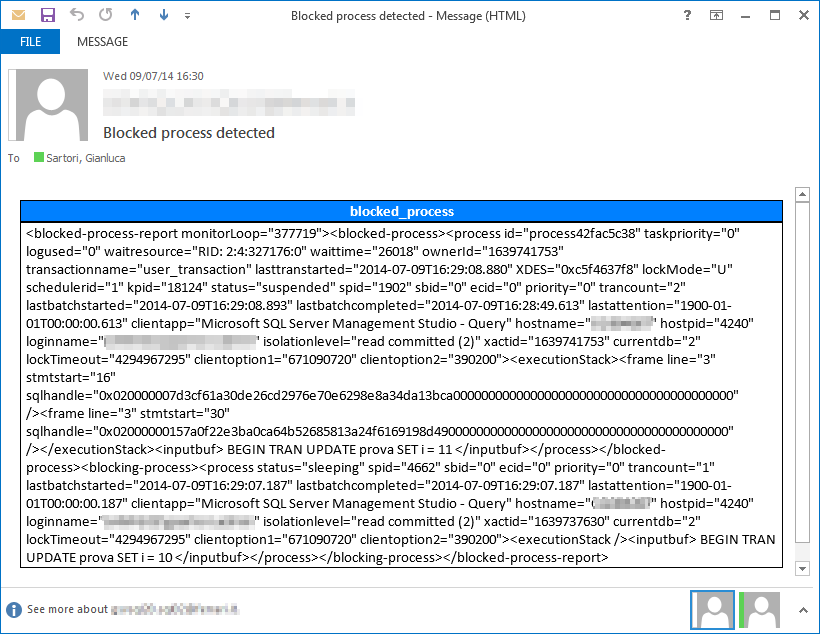
Another part of the project is the CollectionSet Manager, a GUI to install the collector types to the target servers and configure collection sets and collection items. I think that one of the reasons why the Data Collector is very underutilized by DBAs is the lack of a Graphical UI. Besides the features specific to the ExtendedTSQLCollector, such as installing the collector type, this small utility aims at providing the features missing in the SSMS Data Collector UI. This part of the project is still at an early stage, but I am planning to release it in the next few months.
My journey through the ins and outs of the Data Collector allowed me to understand deeply how it works and how to set it up and troubleshoot it. Now I am planning to start a blog series on this topic, from the basics to the advanced features. Stay tuned 🙂
I don’t want to go into deep details on the setup and configuration of this small project: I just wanted to ignite your curiosity and make you rush to codeplex to download your copy of ExtendedTSQLCollector.
What are you waiting for?
COPY_ONLY backups and Log Shipping
Last week I was in the process of migrating a couple of SQL Server instances from 2008 R2 to 2012.
In order to let the migration complete quickly, I set up log shipping from the old instance to the new instance. Obviously, the existing backup jobs had to be disabled, otherwise they would have broken the log chain.
That got me thinking: was there a way to keep both “regular” transaction log backups (taken by the backup tool) and the transaction log backups taken by log shipping?

The first thing that came to my mind was the COPY_ONLY option available since SQL Server 2005.
You probably know that COPY_ONLY backups are useful when you have to take a backup for a special purpose, for instance when you have to restore from production to test. With the COPY_ONLY option, database backups don’t break the differential base and transaction log backups don’t break the log chain.
My initial thought was that I could ship COPY_ONLY backups to the secondary and keep taking scheduled transaction log backups with the existing backup tools.
I was dead wrong.
Let’s see it with an example on a TEST database.
I took 5 backups:
- FULL database backup, to initialize the log chain. Please note that COPY_ONLY backups cannot be used to initialize the log chain.
- LOG backup
- LOG backup with the COPY_ONLY option
- LOG backup
- LOG backup with the COPY_ONLY option
The backup information can be queried from backupset in msdb:
SELECT
ROW_NUMBER() OVER(ORDER BY bs.backup_start_date) AS [backup #]
,first_lsn
,last_lsn
,backup_start_date
,type
,is_copy_only
,DENSE_RANK() OVER(ORDER BY type, bs.first_lsn) AS sequence
FROM msdb.dbo.backupset bs
WHERE bs.database_name = 'TEST'

As you can see, the COPY_ONLY backups don’t truncate the transaction log and losing one of those backups wouldn’t break the log chain.
However, all backups always start from the first available LSN, which means that scheduled log backups taken without the COPY_ONLY option truncate the transaction log and make significant portions of the transaction log unavailable in the next COPY_ONLY backup.
You can see it clearly in the following picture: the LSNs highlighted in red should contain no gaps in order to be restored successfully to the secondary, but the regular TLOG backups break the log chain in the COPY_ONLY backups.

That means that there’s little or no point in taking COPY_ONLY transaction log backups, as “regular” backups will always determine gaps in the log chain.
When log shipping is used, the secondary server is the only backup you can have, unless you keep the TLOG backups or use your backup tool directly to ship the logs.
Why on earth should one take a COPY_ONLY TLOG backup (more than one at least) is beyond my comprehension, but that’s a whole different story.
SQL2014: Defining non-unique indexes in the CREATE TABLE statement
Now that my SQL Server 2014 CTP1 virtual machine is ready, I started to play with it and some new features and differences with the previous versions are starting to appear.
What I want to write about today is a T-SQL enhancement to DDL statements that brings in some new interesting considerations.
SQL Server 2014 now supports a new T-SQL syntax that allows defining an index in the CREATE TABLE statement without having to issue separate CREATE INDEX statements.
Up to now, the same could be achieved only with PRIMARY KEY and UNIQUE constraints, thus allowing UNIQUE indexes only.
For instance, the following statement creates a table with a unique clustered index on order_id and a unique nonclustered index on PO_number:
CREATE TABLE #orders (
order_id uniqueidentifier NOT NULL
PRIMARY KEY CLUSTERED DEFAULT NEWSEQUENTIALID()
,PO_number varchar(50) NOT NULL UNIQUE
,order_date datetime NOT NULL
,total_amount decimal(18,3)
)
OK, but what if I want to add a non-unique index to my table?
SQL Server 2014 offers a new syntax to do that inline with the table DDL:
CREATE TABLE #orders (
order_id uniqueidentifier NOT NULL
PRIMARY KEY CLUSTERED DEFAULT NEWSEQUENTIALID()
,PO_number varchar(50) NOT NULL UNIQUE
-- creates a nonclustered index on order_date
,order_date datetime NOT NULL INDEX IX_order_date
,total_amount decimal(18,3)
)
A similar syntax can be used to create a compound index:
CREATE TABLE #orders (
order_id uniqueidentifier NOT NULL
PRIMARY KEY CLUSTERED DEFAULT NEWSEQUENTIALID()
,PO_number varchar(50) NOT NULL UNIQUE
,order_date datetime NOT NULL INDEX IX_order_date
,total_amount decimal(18,3)
-- creates a compound index on PO_number and order_date
,INDEX IX_orders_compound(PO_number, order_date)
)
An interesting aspect of this new syntax is that it allows creating non-unique nonclustered indexes to table variables, which is something that couldn’t be done in the previous versions.
The syntax to use is the same as for permanent tables:
DECLARE @orders TABLE (
order_id uniqueidentifier NOT NULL
PRIMARY KEY CLUSTERED DEFAULT NEWSEQUENTIALID()
,PO_number varchar(50) NOT NULL UNIQUE
,order_date datetime NOT NULL INDEX IX_order_date
,total_amount decimal(18,3)
)
Cool! But, wait: does this mean that table variables will now behave in the same way permanent tables do?
Not exactly.
Table variables don’t have statistics, and being able to create indexes on them won’t change anything in this regard.
Do you want a proof? OK, the skeptics can run the following code. Please make sure you capture the actual execution plan.
SET NOCOUNT ON;
-- create the table variable
DECLARE @orders TABLE (
order_id uniqueidentifier NOT NULL
PRIMARY KEY CLUSTERED DEFAULT NEWSEQUENTIALID()
,PO_number varchar(50) NOT NULL UNIQUE
,order_date datetime NOT NULL INDEX IX_order_date
,total_amount decimal(18,3)
)
-- insert some data
INSERT INTO @orders (order_date, PO_number, total_amount)
SELECT
order_date = DATEADD(second, CHECKSUM(NEWID()), GETDATE())
,PO_number = CAST(NEWID() AS varchar(50))
,total_amount = CHECKSUM(NEWID()) / 1000.0
FROM sys.all_columns
-
SELECT COUNT(*)
FROM @orders
WHERE order_date > GETDATE()
OPTION (
-- activate some (undocumented) trace flags to show
-- statistics usage. More information on the flags
-- can be found on Paul White's blog:
-- http://sqlblog.com/blogs/paul_white/archive/2011/09/21/how-to-find-the-statistics-used-to-compile-an-execution-plan.aspx
-- redirect output to the messages tab
QUERYTRACEON 3604
-- show "interesting" statistics
,QUERYTRACEON 9292
-- show loaded statistics
,QUERYTRACEON 9402
-- add RECOMPILE to let the optimizer "see"
-- the table cardinality
,RECOMPILE
)
The output of the above batch is empty. Looks like no stats were loaded.
The actual execution plan confirms that no stats were loaded and the estimated cardinality of the table variable is way off:

If we repeat the test with a temporary table, we see a different behaviour.
SET NOCOUNT ON;
IF OBJECT_ID('tempdb..#orders') IS NOT NULL
DROP TABLE #orders;
CREATE TABLE #orders (
order_id uniqueidentifier NOT NULL
PRIMARY KEY CLUSTERED DEFAULT NEWSEQUENTIALID()
,PO_number varchar(50) NOT NULL UNIQUE
,order_date datetime NOT NULL INDEX IX_order_date
,total_amount decimal(18,3)
)
INSERT INTO #orders (order_date, PO_number, total_amount)
SELECT
order_date = DATEADD(second, CHECKSUM(NEWID()), GETDATE())
,PO_number = CAST(NEWID() AS varchar(50))
,total_amount = CHECKSUM(NEWID()) / 1000.0
FROM sys.all_columns
SELECT COUNT(*)
FROM #orders
WHERE order_date > GETDATE()
OPTION (
QUERYTRACEON 3604
,QUERYTRACEON 9292
,QUERYTRACEON 9402
)
This time the messages tab contains some output:
Stats header loaded: DbName: tempdb, ObjName: #orders, IndexId: 2, ColumnName: order_date, EmptyTable: FALSE Stats header loaded: DbName: tempdb, ObjName: #orders, IndexId: 2, ColumnName: order_date, EmptyTable: FALSE
The optimizer identified the statistics on the oder_date column as “interesting” and then loaded the stats header.
Again, the actual execution plan confirms that a better estimation is available:

The lack of statistics has always been the most significant difference between table variables and temporary tables and SQL2014 doesn’t appear to change the rules (yet).
A viable alternative to dynamic SQL in administration scripts
As a DBA, you probably have your toolbox full of scripts, procedures and functions that you use for the day-to-day administration of your instances.
I’m no exception and my hard drive is full of scripts that I tend to accumulate and never throw away, even if I know I will never need (or find?) them again.
However, my preferred way to organize and maintain my administration scripts is a database called “TOOLS”, which contains all the scripts I regularly use.
One of the challenges involved in keeping the scripts in a database rather than in a script file is the inability to choose a database context for the execution. When a statement is encapsulated in a view, function or stored procedure in a database, every reference to a database-specific object is limited to the database that contains the programmable object itself. The only way to overcome this limitation is the use of dynamic sql.
For instance, if I want to query the name of the tables in a database, I can use the following statement:
SELECT name FROM sys.tables
The statement references a catalog view specific to a single database, so if I enclose it in a stored procedure, the table names returned by this query are those found in the database that contains the stored procedure itself:
USE TOOLS; GO CREATE PROCEDURE getTableNames AS SELECT name FROM sys.tables; GO EXEC getTableNames;
This is usually not an issue, since most stored procedures will not cross the boundaries of the database they are created in. Administration scripts are different, because they are meant as a single entry point to maintain the whole SQL server instance.
In order to let the statement work against a different database, you need to choose one of the following solutions:
- dynamic SQL
- sp_executesql
- marking as a system object
- … an alternative way
Each of these techniques has its PROs and its CONs and I will try to describe them in this post.
1. Dynamic SQL
It’s probably the easiest way to solve the issue: you just have to concatenate the database name to the objects names.
USE TOOLS;
GO
ALTER PROCEDURE getTableNames @db_name sysname
AS
BEGIN
DECLARE @sql nvarchar(max)
SET @sql = 'SELECT name FROM '+ QUOTENAME(@db_name) +'.sys.tables';
EXEC(@sql)
END
GO
EXEC getTableNames 'msdb';
PROS:
- very easy to implement for simple statements
CONS:
- can rapidly turn to a nightmare with big, complicated statements, as each object must be concatenated with the database name. Different objects have different ways to be related to the database: tables and views can be concatenated directly, while functions such as OBJECT_NAME accept an additional parameter to specify the database name.
- the statement has to be treated as a string and enclosed in quotes, which means that:
- quotes must be escaped, and escaped quotes must be escaped again and escaped and re-escaped quotes… ok, you know what I mean
- no development aids such as intellisense, just-in-time syntax checks and syntax coloring
2. sp_executesql
It’s a neater way to avoid concatenating the database name to each object referenced in the statement.
USE TOOLS;
GO
ALTER PROCEDURE getTableNames @db_name sysname
AS
BEGIN
-- use a @sql variable to store the whole query
-- without concatenating the database name
DECLARE @sql nvarchar(max);
SET @sql = 'SELECT name FROM sys.tables';
-- concatenate the database name to the
-- sp_executesql call, just once
DECLARE @cmd nvarchar(max);
SET @cmd = 'EXEC '+ QUOTENAME(@db_name) +'.sys.sp_executesql @sql';
EXEC sp_executesql @cmd, N'@sql nvarchar(max)', @sql
END
GO
EXEC getTableNames 'msdb';
PROS:
- the dynamic sql is taken as a whole and does not need to be cluttered with multiple concatenations
CONS:
- needs some more work than a straight concatenation and can be seen as “obscure”
- suffers from the same issues found with plain dynamic sql, because the statement is, again, treated as a string
3. System object
Nice and easy: every stored procedure you create in the master database with the “sp_” prefix can be executed from any database context.
Using the undocumented stored procedure sp_MS_marksystemobject you can also mark the stored procedure as a “system object” and let it reference the tables in the database from which it is invoked.
USE master;
GO
ALTER PROCEDURE sp_getTableNames
AS
BEGIN
SELECT name FROM sys.tables
END
GO
EXEC sys.sp_MS_marksystemobject 'sp_getTableNames'
GO
USE msdb;
GO
EXEC sp_getTableNames;
PROS:
- no need to use dynamic sql
CONS:
- requires creating objects in the “master” database, which is something I tend to avoid
- works with stored procedures only (actually, it works with other objects, such as tables and views, but you have to use the “sp_” prefix. The day I will find a view named “sp_getTableNames” in the master database it won’t be safe to stay near me)
An alternative method:
It would be really helpful if we could store the statement we want to execute inside an object that doesn’t involve dynamic sql and doesn’t need to be stored in the master database. In other words, we need a way to get the best of both worlds.
Is there such a solution? Apparently, there isn’t.
The ideal object to store a statement and reuse it later is a view, but there is no way to “execute” a view against a different database. In fact you don’t execute a view, you just select from it, which is quite a different thing.
What you “execute” when you select from a view is the statement in its definition (not really, but let me simplify).
So, what we would need to do is just read the definition from a view and use the statement against the target database. Sounds straightforward, but it’s not.
The definition of a view also contains the “CREATE VIEW” statement and stripping it off is not just as easy as it seems.
Let’s see the issue with an example: I will create a view to query the last update date of the index statistics in a database, using the query from Glenn Berry’s Diagnostic Queries.
USE TOOLS;
GO
-- When were Statistics last updated on all indexes? (Query 48)
CREATE VIEW statisticsLastUpdate
AS
SELECT
DB_NAME() AS database_name
,o.NAME AS stat_name
,i.NAME AS [Index Name]
,STATS_DATE(i.[object_id], i.index_id) AS [Statistics Date]
,s.auto_created
,s.no_recompute
,s.user_created
,st.row_count
FROM sys.objects AS o WITH (NOLOCK)
INNER JOIN sys.indexes AS i WITH (NOLOCK)
ON o.[object_id] = i.[object_id]
INNER JOIN sys.stats AS s WITH (NOLOCK)
ON i.[object_id] = s.[object_id]
AND i.index_id = s.stats_id
INNER JOIN sys.dm_db_partition_stats AS st WITH (NOLOCK)
ON o.[object_id] = st.[object_id]
AND i.[index_id] = st.[index_id]
WHERE o.[type] = 'U';
I just had to remove ORDER BY and OPTION(RECOMPILE) because query hints cannot be used in views.
Querying the object definition returns the whole definition of the view, not only the SELECT statement:
SELECT OBJECT_DEFINITION(OBJECT_ID('statisticsLastUpdate')) AS definition
definition
-------------------------------------------------------------------
-- When were Statistics last updated on all indexes? (Query 48)
CREATE VIEW statisticsLastUpdate
AS
SELECT
DB_NAME() AS database_name
,o.NAME AS stat_name
,i.NAME AS [Index Name]
,STATS_DATE(i.[object_id], i.index_id) AS [Statistics Date]
,s.auto_created
,s.no_recompute
(1 row(s) affected)
In order to extract the SELECT statement, we would need something able to parse (properly!) the view definition and we all know how complex it can be.
Fortunately, SQL Server ships with an undocumented function used in replication that can help solving the problem: its name is fn_replgetparsedddlcmd.
This function accepts some parameters, lightly documented in the code: fn_replgetparsedddlcmd (@ddlcmd, @FirstToken, @objectType, @dbname, @owner, @objname, @targetobject)
Going back to the example, we can use this function to extract the SELECT statement from the view definition:
SELECT master.sys.fn_replgetparsedddlcmd(
OBJECT_DEFINITION(OBJECT_ID('statisticsLastUpdate'))
,'CREATE'
,'VIEW'
,DB_NAME()
,'dbo'
,'statisticsLastUpdate'
,NULL
) AS statement
statement
---------------------------------------------------------------------
AS
SELECT
DB_NAME() AS database_name
,o.NAME AS stat_name
,i.NAME AS [Index Name]
,STATS_DATE(i.[object_id], i.index_id) AS [Statistics Date]
,s.auto_created
,s.no_recompute
,s.user_created
,st.row_count
(1 row(s) affected)
The text returned by the function still contains the “AS” keyword, but removing it is a no-brainer:
DECLARE @cmd nvarchar(max)
SELECT @cmd = master.sys.fn_replgetparsedddlcmd(
OBJECT_DEFINITION(OBJECT_ID('statisticsLastUpdate'))
,'CREATE'
,'VIEW'
,DB_NAME()
,'dbo'
,'statisticsLastUpdate'
,NULL
)
SELECT @cmd = RIGHT(@cmd, LEN(@cmd) - 2) -- Removes "AS"
SELECT @cmd AS statement
statement
-------------------------------------------------------------------
SELECT
DB_NAME() AS database_name
,o.NAME AS stat_name
,i.NAME AS [Index Name]
,STATS_DATE(i.[object_id], i.index_id) AS [Statistics Date]
,s.auto_created
,s.no_recompute
,s.user_created
,st.row_count
(1 row(s) affected)
Now that we are able to read the SELECT statement from a view’s definition, we can execute that statement against any database we like, or even against all the databases in the instance.
-- =============================================
-- Author: Gianluca Sartori - spaghettidba
-- Create date: 2013-04-16
-- Description: Extracts the view definition
-- and runs the statement in the
-- database specified by @db_name
-- If the target database is a pattern,
-- the statement gets executed against
-- all databases matching the pattern.
-- =============================================
CREATE PROCEDURE [dba_execute_view]
@view_name sysname
,@db_name sysname
AS
BEGIN
SET NOCOUNT,
XACT_ABORT,
QUOTED_IDENTIFIER,
ANSI_NULLS,
ANSI_PADDING,
ANSI_WARNINGS,
ARITHABORT,
CONCAT_NULL_YIELDS_NULL ON;
SET NUMERIC_ROUNDABORT OFF;
DECLARE @cmd nvarchar(max)
DECLARE @sql nvarchar(max)
DECLARE @vw_schema sysname
DECLARE @vw_name sysname
IF OBJECT_ID(@view_name) IS NULL
BEGIN
RAISERROR('No suitable object found for name %s',16,1,@view_name)
RETURN
END
IF DB_ID(@db_name) IS NULL
AND @db_name NOT IN ('[USER]','[SYSTEM]')
AND @db_name IS NOT NULL
BEGIN
RAISERROR('No suitable database found for name %s',16,1,@view_name)
RETURN
END
SELECT @vw_schema = OBJECT_SCHEMA_NAME(OBJECT_ID(@view_name)),
@vw_name = OBJECT_NAME(OBJECT_ID(@view_name))
SELECT @cmd = master.sys.fn_replgetparsedddlcmd(
OBJECT_DEFINITION(OBJECT_ID(@view_name))
,'CREATE'
,'VIEW'
,DB_NAME()
,@vw_schema
,@vw_name
,NULL
)
SELECT @cmd = RIGHT(@cmd, LEN(@cmd) - 2) -- Removes "AS"
-- CREATE A TARGET TEMP TABLE
SET @sql = N'
SELECT TOP(0) * INTO #results FROM ' + @view_name + ';
INSERT #results
EXEC [dba_ForEachDB]
@statement = @cmd,
@name_pattern = @db_name;
SELECT * FROM #results;'
EXEC sp_executesql
@sql
,N'@cmd nvarchar(max), @db_name sysname'
,@cmd
,@db_name
END
The procedure depends on dba_ForEachDB, the stored procedure I posted a couple of years ago that replaces the one shipped by Microsoft. If you still prefer their version, you’re free to modify the code as you wish.
Now that we have a stored procedure that “executes” a view, we can use it to query statistics update information from a different database:
EXEC [dba_execute_view] 'statisticsLastUpdate', 'msdb'

We could also query the same information from all user databases:
EXEC [dba_execute_view] 'statisticsLastUpdate', '[USER]'

That’s it, very easy and straightforward.
Just one suggestion for the SELECT statements in the views: add a DB_NAME() column, in order to understand where the data comes from, or it’s going to be a total mess.
Next steps:
This is just the basic idea, the code can be improved in many ways.
For instance, we could add a parameter to decide whether the results must be piped to a temporary table or not. As you probably know, INSERT…EXEC cannot be nested, so you might want to pipe the results to a table in a different way.
Another thing you might want to add is the ability to order the results according to an additional parameter.
To sum it up, with a little help from Microsoft, we can now safely create a database packed with all our administration stuff and execute the queries against any database in our instance.
Moving system databases to the default data and log paths
Recently I had to assess and tune quite a lot of SQL Server instances and one the things that are often overlooked is the location of the system databases.
I often see instance where the system databases are located in the system drives under the SQL Server default installation path, which is bad for many reasons, especially for tempdb.
I had to move the system databases so many times that I ended up coding a script to automate the process.
The script finds all system databases that are not sitting in the default data and log paths and issues the ALTER DATABASE statements needed to move the files to the default paths.
Obviously, to let the script work, the default data and log paths must have been set in the instance properties:

You may also point out that moving all system databases to the default data and log paths is not always a good idea. And you would be right: for instance, if possible, the tempdb database should be working on a fast dedicated disk. However, very often I find myself dealing with low-end servers where separate data and log disks are a luxury, not to mention a dedicated tempdb disk. If you are concerned about moving tempd to the default data and log paths, you can modify the script accordingly.
-- =============================================
-- Author: Gianluca Sartori - spaghettidba
-- Create date: 2013-03-22
-- Description: Moves the system databases to the
-- default data and log paths and
-- updates SQL Server startup params
-- accordingly.
-- =============================================
SET NOCOUNT ON;
USE master;
-- Find default data and log paths
-- reading from the registry
DECLARE @defaultDataLocation nvarchar(4000)
DECLARE @defaultLogLocation nvarchar(4000)
EXEC master.dbo.xp_instance_regread
N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer',
N'DefaultData',
@defaultDataLocation OUTPUT
EXEC master.dbo.xp_instance_regread
N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer',
N'DefaultLog',
@defaultLogLocation OUTPUT
-- Loop through all system databases
-- and move to the default data and log paths
DECLARE @sql nvarchar(max)
DECLARE stmts CURSOR STATIC LOCAL FORWARD_ONLY
FOR
SELECT
' ALTER DATABASE '+ DB_NAME(database_id) +
' MODIFY FILE ( ' +
' NAME = '''+ name +''', ' +
' FILENAME = '''+
CASE type_desc
WHEN 'ROWS' THEN @defaultDataLocation
ELSE @defaultLogLocation
END +
'\'+ RIGHT(physical_name,CHARINDEX('\',REVERSE(physical_name),1)-1) +'''' +
' )'
FROM sys.master_files
WHERE DB_NAME(database_id) IN ('master','model','msdb','tempdb')
AND (
physical_name NOT LIKE @defaultDataLocation + '%'
OR physical_name NOT LIKE @defaultLogLocation + '%'
)
OPEN stmts
FETCH NEXT FROM stmts INTO @sql
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT @sql
EXEC(@sql)
FETCH NEXT FROM stmts INTO @sql
END
CLOSE stmts
DEALLOCATE stmts
-- Update SQL Server startup parameters
-- to reflect the new master data and log
-- files locations
DECLARE @val nvarchar(500)
DECLARE @key nvarchar(100)
DECLARE @regvalues TABLE (
parameter nvarchar(100),
value nvarchar(500)
)
INSERT @regvalues
EXEC master.dbo.xp_instance_regenumvalues
N'HKEY_LOCAL_MACHINE',
N'SOFTWARE\Microsoft\MSSQLServer\MSSQLServer\Parameters'
DECLARE reg CURSOR STATIC LOCAL FORWARD_ONLY
FOR
SELECT *
FROM @regvalues
WHERE value LIKE '-d%'
OR value LIKE '-l%'
OPEN reg
FETCH NEXT FROM reg INTO @key, @val
WHILE @@FETCH_STATUS = 0
BEGIN
IF @val LIKE '-d%'
SET @val = '-d' + (
SELECT physical_name
FROM sys.master_files
WHERE DB_NAME(database_id) = 'master'
AND type_desc = 'ROWS'
)
IF @val LIKE '-l%'
SET @val = '-l' + (
SELECT physical_name
FROM sys.master_files
WHERE DB_NAME(database_id) = 'master'
AND type_desc = 'LOG'
)
EXEC master.dbo.xp_instance_regwrite
N'HKEY_LOCAL_MACHINE',
N'SOFTWARE\Microsoft\MSSQLServer\MSSQLServer\Parameters',
@key,
N'REG_SZ',
@val
FETCH NEXT FROM reg INTO @key, @val
END
CLOSE reg
DEALLOCATE reg
After running this script, you can shut down the SQL Server service and move the data and log files to the appropriate locations.
When the files are ready, you can bring SQL Server back online.
BE CAREFUL! Before running this script against a clustered instance, check what the xp_instance_regread commands return: I have seen cases with SQL Server not reading from the appropriate keys.
