Blog Archives
A bug in merge replication with FILESTREAM data
I wish I could say that every DBA has a love/hate relationship with Replication, but, let’s face it, it’s only hate. But it could get worse: it could be Merge Replication. Or even worse: Merge Replication with FILESTREAM.
What could possibly top all this hatred and despair if not a bug? Well, I happened to find one, that I will describe here.
The scenario
I published tables with FILESTREAM data before, but it seems like there is a particular planetary alignment that triggers an error during the execution of the snapshot agent.
This unlikely combination consists in a merge article with a FILESTREAM column and two UNIQUE indexes on the ROWGUIDCOL column. Yes, I know that generally it does not make sense to have two indexes on the same column, but this happened to be one of the cases where it did, so we had a CLUSTERED PRIMARY KEY on the uniqueidentifier column decorated with the ROWGUIDCOL attribute and, on top, one more NONCLUSTERED UNIQUE index on the same column, backed by a UNIQUE constraint.
Setting up the publication does not throw any error, but generating the initial snapshot for the publication does:
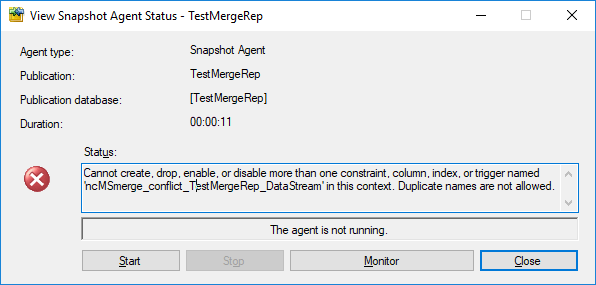
Cannot create, drop, enable, or disable more than one constraint, column, index, or trigger named 'ncMSmerge_conflict_TestMergeRep_DataStream' in this context. Duplicate names are not allowed.
Basically, the snapshot agent is complaining about the uniqueness of the name of one of the indexes it is trying to create on the conflict table. The interesting fact about this bug is that it doesn’t appear when the table has no FILESTREAM column and it doesn’t appear when the table doesn’t have the redundant UNIQUE constraint on the ROWGUID column: both conditions need to be met.
The script
Here is the full script to reproduce the bug.
Before you run it, make sure that:
- FILESTREAM is enabled
- Distribution is configured
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| USE master; | |
| GO | |
| — | |
| — CLEANUP | |
| — | |
| IF DB_ID('TestMergeRep') IS NOT NULL | |
| BEGIN | |
| BEGIN TRY | |
| exec TestMergeRep.sys.sp_dropmergepublication @publication=N'TestMergeRep'; | |
| END TRY | |
| BEGIN CATCH | |
| PRINT 'sp_dropmergepublication failed' | |
| END CATCH | |
| BEGIN TRY | |
| exec TestMergeRep.sys.sp_removedbreplication 'TestMergeRep', 'merge'; | |
| END TRY | |
| BEGIN CATCH | |
| PRINT 'sp_removedbreplication failed' | |
| END CATCH | |
| BEGIN TRY | |
| exec TestMergeRep.sys.sp_replicationdboption @dbname = N'TestMergeRep', @optname = N'merge publish', @value = N'false'; | |
| END TRY | |
| BEGIN CATCH | |
| PRINT 'sp_replicationdboption failed' | |
| END CATCH | |
| ALTER DATABASE TestMergeRep SET SINGLE_USER WITH ROLLBACK IMMEDIATE; | |
| DROP DATABASE TestMergeRep; | |
| END | |
| GO | |
| — | |
| — CREATE DATABASE | |
| — | |
| CREATE DATABASE TestMergeRep; | |
| GO | |
| — WE NEED A FILESTREAM FILEGROUP | |
| DECLARE @path nvarchar(128), @sql nvarchar(max); | |
| SELECT @path = LEFT(physical_name, LEN(physical_name) – CHARINDEX('\', REVERSE(physical_name),1) + 1) | |
| FROM sys.database_files | |
| WHERE type = 0 | |
| ALTER DATABASE TestMergeRep | |
| ADD | |
| FILEGROUP [TestmergeRep_FileStream01] CONTAINS FILESTREAM; | |
| SET @sql = ' | |
| ALTER DATABASE TestMergeRep | |
| ADD | |
| FILE | |
| ( NAME = N''TestmergeRep_FS01'', FILENAME = ''' + @path + 'TestMergeRep_FS01'' , MAXSIZE = UNLIMITED) | |
| TO FILEGROUP [TestmergeRep_FileStream01]; | |
| ' | |
| EXEC(@sql) | |
| — | |
| — CREATE TABLE | |
| — | |
| USE TestMergeRep; | |
| GO | |
| SET ANSI_NULLS ON | |
| GO | |
| SET QUOTED_IDENTIFIER ON | |
| GO | |
| CREATE TABLE [dbo].[DataStream]( | |
| [DataStreamGUID] [uniqueidentifier] ROWGUIDCOL NOT NULL, | |
| [ValueData] [varbinary](max) FILESTREAM NOT NULL, | |
| CONSTRAINT [DataStream_DataStream_PK] PRIMARY KEY CLUSTERED | |
| ( | |
| [DataStreamGUID] ASC | |
| ) | |
| ) | |
| GO | |
| — I know it doesn't make sense, but the bug only shows | |
| — when the table has a second UNIQUE constraint on the PK column | |
| ALTER TABLE [DataStream] ADD CONSTRAINT UQ_MESL_DataStreamPK UNIQUE ([DataStreamGUID]); | |
| — WORKAROUND: create the UNIQUE index without creating the UNIQUE constraint: | |
| –CREATE UNIQUE NONCLUSTERED INDEX UQ_MESL_DataStreamPK ON [DataStream] ([DataStreamGUID]); | |
| — | |
| — SET UP REPLICATION | |
| — | |
| USE master | |
| EXEC sp_replicationdboption | |
| @dbname = N'TestMergeRep', | |
| @optname = N'merge publish', | |
| @value = N'true'; | |
| use [TestMergeRep] | |
| exec sp_addmergepublication | |
| @publication = N'TestMergeRep', | |
| @description = N'Merge publication of database TestMergeRep.', | |
| @retention = 30, | |
| @sync_mode = N'native', | |
| @allow_push = N'true', | |
| @allow_pull = N'true', | |
| @allow_anonymous = N'false', | |
| @enabled_for_internet = N'false', | |
| @conflict_logging = N'publisher', | |
| @dynamic_filters = N'false', | |
| @snapshot_in_defaultfolder = N'true', | |
| @compress_snapshot = N'false', | |
| @ftp_port = 21, | |
| @ftp_login = N'anonymous', | |
| @conflict_retention = 14, | |
| @keep_partition_changes = N'false', | |
| @allow_subscription_copy = N'false', | |
| @allow_synctoalternate = N'false', | |
| @add_to_active_directory = N'false', | |
| @max_concurrent_merge = 0, | |
| @max_concurrent_dynamic_snapshots = 0, | |
| @publication_compatibility_level = N'100RTM', | |
| @use_partition_groups = N'false'; | |
| exec sp_addpublication_snapshot | |
| @publication = N'TestMergeRep', | |
| @frequency_type = 1, | |
| @frequency_interval = 1, | |
| @frequency_relative_interval = 1, | |
| @frequency_recurrence_factor = 1, | |
| @frequency_subday = 1, | |
| @frequency_subday_interval = 5, | |
| @active_start_date = 0, | |
| @active_end_date = 0, | |
| @active_start_time_of_day = 10000, | |
| @active_end_time_of_day = 235959; | |
| exec sp_addmergearticle | |
| @publication = N'TestMergeRep', | |
| @article = N'DataStream', | |
| @source_owner = N'dbo', | |
| @source_object = N'DataStream', | |
| @type = N'table', | |
| @description = null, | |
| @column_tracking = N'true', | |
| @pre_creation_cmd = N'drop', | |
| @creation_script = null, | |
| @schema_option = 0x000000010C034FD1, | |
| @article_resolver = null, | |
| @subset_filterclause = N'', | |
| @vertical_partition = N'false', | |
| @destination_owner = N'dbo', | |
| @verify_resolver_signature = 0, | |
| @allow_interactive_resolver = N'false', | |
| @fast_multicol_updateproc = N'true', | |
| @check_permissions = 0, | |
| @identityrangemanagementoption = 'manual', | |
| @delete_tracking = N'true', | |
| @stream_blob_columns = N'false', | |
| @force_invalidate_snapshot = 1; | |
| — Sets all merge jobs owned by sa | |
| DECLARE @job_id uniqueidentifier | |
| DECLARE c CURSOR STATIC LOCAL FORWARD_ONLY READ_ONLY | |
| FOR | |
| SELECT job_id | |
| FROM msdb.dbo.sysjobs AS sj | |
| INNER JOIN msdb.dbo.syscategories AS sc | |
| ON sj.category_id = sc.category_id | |
| WHERE sc.name = 'REPL-Merge'; | |
| OPEN c | |
| FETCH NEXT FROM c INTO @job_id | |
| WHILE @@FETCH_STATUS = 0 | |
| BEGIN | |
| EXEC msdb.dbo.sp_update_job @job_id=@job_id , @owner_login_name=N'sa' | |
| FETCH NEXT FROM c INTO @job_id | |
| END | |
| CLOSE c | |
| DEALLOCATE c |
After running the script, start the snapshot agent and you’ll see the error appearing:
Workaround
One way to get rid of the bug is to enforce the uniqueness of the data by using a UNIQUE index instead of a UNIQUE constraint:
CREATE UNIQUE NONCLUSTERED INDEX UQ_MESL_DataStreamPK ON [DataStream] ([DataStreamGUID]);
With this index, the snapshot agent completes correctly. Please note that the index would have been UNIQUE anyway, because its key is a superset of the primary key.
Hope this helps!
Please Vote!
This bug has been filed on UserVoice and can be found here: https://feedback.azure.com/forums/908035-sql-server/suggestions/34735489-bug-in-merge-replication-snapshot-agent-with-files
Please upvote it!
