Blog Archives
SQL Server Infernals – Circle 6: Environment Pollutors

Don’t tell me that you didn’t see it coming: at some point, Developers end up being put to hell by a DBA!
I don’t want to enter the DBA/Developer wars, but some sins committed by Developers really deserve a ticket to the SQL Server hell. In particular, some of those sins are perpetrated when not even a single line of code is written yet and they have to do with the way the development environment is set up.
What they say in Heaven
Before starting a software project, the angelic developers set up their environment in the best of all ways, with proper environment isolation and definition. In particular they will have:
- Development Environment: this is the place (ideally a dev’s desktop) where the development work is performed. It should resemble the production environment as much as possible.
- Test Environment (QA): This is where the testers ensure the quality of the application, open bugs and review bug fixes. It should be identical to the production environment (in Heaven it is).
- User Acceptance Test Environment (UAT): this is where the clients test the quality of third-party applications, request features and file bugs.
- Staging Environment (Pre-Production): this environment is used to assemble, test and review newer versions of the database before it is moved into production. The hardware mirrors that of the production environment.
- Production Environment: This is where the real database lives. It can be updated from the staging environment, when available, as well as new functionality and bug fixes release from UAT or staging environment.
If your organization or the project are small, you probably don’t need all of these environments. In Heaven, where time and money are not a constraint, they have all of them and they’re all identical to production. Heh, Heaven is Heaven after all…
Environmental sinners will face SQL Server’s judgement
Setting up your development environment in the wrong way can harm SQL Server (and your software) in many ways, right from the start of the project, throughout its whole lifetime. Let’s see some of the most common sins:

A notable example of Polluted Database
- Using the production environment for development: frankly, I don’t think this sin needs any further explanation. On the other hand, don’t assume that nobody’s doing it, despite we’re in 2015: lots of damned developers’ souls confess this sin while entering the SQL Server hell!
- Using the test environment for development: Again, this seems so obvious that there should be no need to discuss it: development is development and test is test. The test environment(s) should be used to test the application, not to see it breaking every minute because you changed something. Developing the code and testing it are two different things and, even if you happen to be in charge of both, this is not a good reason to confuse the two tasks.
- Using a shared instance for development: Back in the old days, when I was working as an ASP classic developer in a software house, we had a shared development environment on a central IIS server, where everyone saved their code on a shared folder and just had to hit F5 in Internet Explorer to see the changes immediately in action.
If you think this model is foolish you’re 100% right, but in the 90s’ we didn’t know better. However, while everyone today agrees that it’s a terrible idea for code, you will still find hordes of developers not completely convinced that it’s an equally terrible idea as far as the database is concerned. Having a shared development database greatly simplifies the process of creating a consistent development database, which is a problem only if you have no authoritative source to build it from (which brings us to the next sin).
- No source control: Nobody in their right mind would start a software project today without using source control, yet source control for the database is still an esoteric topic, despite the plethora of tools to accomplish this task.
- Granting sysadmin rights to the application: If you’re using a local development instance (and you should), you probably are the administrator of that instance. Hey, nothing wrong with that, unless you use windows authentication in your application. In that case, whenever you debug the application in Visual Studio (or whatever you’re using), the application impersonates you (a sysadmin) when hitting the database, so there is no need to grant any permission in order to let the app perform anything on the instance.
So, what happens when you’re done with development and you have to deploy in test (or, worse, production)? Exactly: nothing works, because (hopefully) the application won’t run with sysadmin privileges in production. At that point, extracting the complete lists of permissions needed by the application is an overwhelming task that you could have happily avoided by developing with a non-privileged user in the first place. When using a regular user, each time the application needs additional permissions, you simply have to add a GRANT statement to the deployment script, which also acts as the documentation the DBA will ask for.
If you fail to provide this documentation, two things could happen: a) the DBA may refuse to deploy the database b) you could end up needing sysadmin privileges, which means a dedicated instance, which could in turn bring us back to a).
- Developing on a different version/edition from production: if your application is targeting SQL Server 2008 R2, developing on SQL Server 2012 could mean that you will discover incompatible T-SQL features after development. The same can be said for the SQL Server edition: if you are using a Developer Edition for development but you are targeting Standard Edition, you will discover the use of enterprise-only features when it’s too late. You can save yourself all the pain by using in development the same exact SQL Server version and edition you are targeting in production.
In the next episodes of SQL Server Infernals I’m afraid I will have to put more developers to hell. If you’re a developer, stay tuned to find out if your soul is a at risk! If you’re a DBA, stay tuned to enjoy seeing more developers damned!
SQL Server Infernals – Circle 5: Inconsistent Baptists
There’s a place in the SQL Server hell where you can find poor souls wandering the paths of their circle, shouting nonsense table names or system-generated constraint names, trying to baptize everything they find on their way in a different manner. They might seem innocuous at a first glance, but beware those damned souls, as they can raise confusion and endanger performance.
What they say in Heaven
Guided by the Intelligent Designer’s hands, database architects in Heaven always name their tables, columns and all database objects following the rules in the ISO 11179 standard. However, standards aside, the most important thing they do is adhere to a single naming convention, so that every angelic DBA and developer can sing in the same language.
It has to be said that even in Heaven some angels prefer specific naming conventions and some other angels might prefer different ones (say plural or singular table names), but as soon as they start to design a database, every disagreement magically disappears and they all sing in harmony.
Damnation by namification
Some naming conventions are better than others, but many times it all comes down to personal preference. It’s a highly debatable subject and I will refrain from posting here what my preference is. If you want to learn more about naming conventions, take advice from one of the masters.
That said, some naming conventions are really bad and adopting them is a one way ticket to the SQL Server hell:
- Hungarian Notation: my friends in Hungary will forgive me if I say that their notation doesn’t play well with database objects. In fact, the Hungarian Notation was conceived in order to overcome the lack of proper data types in the BCPL language, putting a metadata prefix in each variable name. For instance, a variable holding a string would carry the “str” prefix, while a variable holding a long integer would carry the “l” prefix.
SQL Server (and all modern relational databases) have proper data type support and all sorts of metadata discovery features, so there is no point in naming a table “tbl_customer” or a view “vwSales”. Moreover, if the DBA decides to break a table in two and expose its previous structure as a view (in order to prevent breaking existing code), having the “tbl” prefix in the view name completely defeats the purpose of identifying the object type by its prefix.
Next time you’re tempted to use the Hungarian Notation ask yourself: “is my name John or DBA_John?”
Hungary is a nice str_country.
- Using insanely short object names: Some legacy databases (yes, you, DB2/400) used to have a hard maximum of 10 characters for object names. It wasn’t uncommon to see table names such as “VN30SKF0OF” or “PRB10SPE4F”: good luck figuring out what those tables represented!
Fortunately, those days are gone and today there is no single reason to use alphabet soup names for your objects. The object name is a contract between the object and its contents and it should be immediately clear what the contents are by just glancing at the name.
- Using insanely long object names: On the other hand, table names such as “ThisIsTheViewThatContainsOrdersWhichAreYetToBeShipped” adds nothing to clarity of the schema. “UnshippedOrders” will do just as well.
- Mixing Languages: if you’re fortunate enough to be a native English speaker, you have no idea what this means. In countries such as Italy or Spain, this is a real issue. Many people may end up designing different parts the database schema and each designer may be inclined to use English (the lingua franca of Information Technology) or his/her first language. Needless to say that the result is a mess.
- Using the “sp_” prefix for stored procedures: it’s a special case of Hungarian Notation, with severe performance implications. In his blog, Aaron Bertrand discussed the notorious negative impact of the “sp_” prefix, offering a performance comparison with charts and crunchy numbers.
TL;DR version: SQL Server looks up objects with the sp_ prefix in the master database first, then in the user database. While it may look like a negligible performance issue, it can explode at scale.
- Using reserved keywords or illegal characters: While it’s still possible to include almost anything inside square brackets, the use of spaces, quotes or any other illegal character is a totally unneeded masochistic habit. Reserved keywords may also add a thrilling touch of insane confusion to your T-SQL code:
SELECT * FROM [TRUNCATE] [TABLE]
Enough said.
- Using system-generated names for constraints, indexes and so on: When you don’t name your constraints and indexes explicitly, SQL Server is kind enough as to do it for you, using a semi-random system-generated name. That’s great! Uh, wait a moment: this means that two databases deployed to two different instances will contains the same index with a different name, making all your deployment scripts nearly useless. Do yourself a favor and take the time to name all your objects explicitly.
- No naming convention or multiple, inconsistent naming conventions: The worst of all mistakes is having multiple naming conventions, or no naming convention at all (which is equal to “as many naming conventions as objects in the database”). Naming conventions is a sort of religious subject and there are multiple valid reasons to adopt one or another: the only thing you should absolutely avoid is turning your database into a sort of Babel tower, where multiple different languages are spoken and nobody understands what the others say.
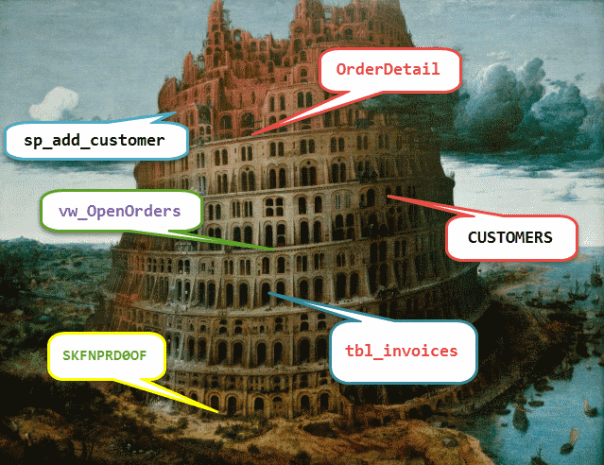

This is the last circle of SQL Server hell dedicated to Database Design sins: in the next episode of SQL Server Infernals we will venture into the first circle dedicated to development. Stay tuned!
SQL Server Infernals – Circle 4: Anarchic Designers
Constraints are sometimes annoying in real life, but no society can exist without rules and regulations. The same concept is found in Database Design: no good data can exist without constraints.
What they say in Heaven
Constraints define what is acceptable in the database and what does not comply with business rules. In Heaven, where the perfect database runs smoothly, no constraint is overlooked and all the data obeys to the rules of angels:
- Every column accepts only the data it was meant for, using the appropriate data type
- Every column that requires a value has a NOT NULL constraint
- Every column that references a key in a different table has a FOREIGN KEY constraint
- Every column that must comply with a business rule has a CHECK constraint
- Every column that must be populated with a predefined value has a DEFAULT constraint
- Every table has a PRIMARY KEY constraint
- Every group of columns that does not accept duplicate values has a UNIQUE constraint
Chaos belongs to hell
OK: Heaven is Heaven, but what about hell? Let’s see what will get you instant damnation:

- Using the wrong data type: we already found out that the SQL Server hell is full of Shaky Typers. The data type is the first constraint on your data: choose it carefully.
- No PRIMARY KEY constraints: In the relational model, tables have primary keys. Without a primary key, a table is not even a table (exception made for staging tables and other temporary objects). Do you want duplicate data and unusable data? Go on and drop your primary key.
- NULL and NOT NULL used interchangeably: NOT NULL is a constraint on your data: failing to mark required columns with NOT NULL will inevitably mean that you’ll end up having missing information in your rows. At the same time, marking all columns as NOT NULL will bring garbage data in the database, because users will start using dummy data to circumvent the stupid constraint. We already met these sinners in the First Circle of the SQL Server hell.
- No Foreign Key constraints: Foreign Keys can be annoying, because they force you to modify the database in the correct order, but following the rules pays off. Without proper constraints, what would happen if you tried to delete from a lookup table a key referenced in other tables? Unfortunately, it would work, silently destroying the correctness of your data.
What would happen if you tried to sneak in a row that references a non-existing key? Again, it would bring in invalid data.
- No CHECK constraints: Many columns have explicit or implicit constraints: failing to add them to the database schema means that values forbidden by the business rules will start to flow into the database. Some constraints are implicit, but equally important as the explicit ones. For instance:
- an order should never be placed in a future date
- a stock quantity should never be negative
- a ZIP code should only contain numeric characters
- a Social Security Number should be exactly 9 digits long
- Relying on the application to validate data: If I had €0.01 for every time I found invalid data in a database and the developers said “the application will guarantee consistency”, I would be blogging from my castle in Mauritius. Maybe the application can guarantee consistency for the data that it manipulates (and it won’t, trust me), but it can do nothing for other applications using the same database. Often the database is a hub for many applications, each with its own degree of complexity and each with its level of quality. Pretending that all these applications will independently guarantee that no invalid data is brought in is totally unrealistic.
The last circle of SQL Server hell dedicated to Database Design sins is the circle of Inconsistent Baptists, those who fail to comply to sensible naming conventions. Stay tuned!
SQL Server Infernals – Circle 3: Shaky Typers
Choosing the right data type for your columns is first of all a design decision that has tremendous impact on the correctness of the database schema. It is not just about performance or space usage: the data type is the first constraint on your data and it decides what can be persisted in your columns and what is not acceptable.
Choosing the wrong data type for your columns is a mistake that might make your life as a DBA look like hell.
What they say in Heaven
Guided by angelic spells, the hands that design databases in Heaven always choose the right data type. Database architects always look at the logical schema and ask the right questions about each attribute and they always manage to understand what the attribute is used for and what it will be used for in the future.
What will put you to hell
Choosing the wrong data type is like trying to fit a square peg in a round hole. The worst thing about it is that you end up damaging the peg… ahem… the data.

- Using numeric data types for non-numeric attributes: Even if a telephone number contains only digits and it’s called telephone number, it is not a number at all. It does not allow mathematical operations and it has no order relation (saying that a telephone number is greater than another one makes no sense). In fact, a telephone number is a code you have to dial to contact a telephone extension. The same can be said for ZIP codes, which only allow numeric digits, but are nothing like a number. Storing this data in a numeric column is looking for trouble.
- Storing data as their human-readable representation: A Notable example is dates stored as (var)char. The string representation of a date is not a date at all: without the validation rules included in the date types, any invalid date could be saved in your column, including ‘2015-02-30’ or ‘2015-33-99’. Moreover, varchar columns do not allow date manipulation functions, such as DATEADD, DATEDIFF, YEAR, MONTH and so on. Another reason why this is a terrible idea is that dates have their own sorting rules, which you lose when you store them as strings. You also need more storage space to save a string representation of a date compared to the proper date type. If you really want to convert a date to a string, you can find many algorithms and functions to perform the conversion in this article I wrote for SQLServerCentral in 2012, but please do it in your presentation layer, not when storing the data in your tables.
Another surprisingly common mistake in the AS/400 world is storing dates in three separate integer columns for year, month and day. I have no idea where this pattern comes from, but it definitely belongs to hell.
While much more uncommon in the wild, the same applies to numbers: storing them as varchars is a terrible idea.
Extra evil bonus: you get double evil points for storing dates and numbers as nvarchar: double the storage, double the pain.
- Using deprecated data types: (n)text and image are things of the past: get over it. The replacement (n)varchar(max) and varbinary(max) are much more powerful and flexible.
- Using “extended” data type just to “be safe”: This applies both to numeric and character columns: using a bigger data type just to play it safe can be a good idea at times, but not when the size of the column is well known upfront and is instead a vital constraint on the data itself. For instance, a ZIP code longer than 5 characters is obviously an error. A social security number longer than 9 digits is not valid.
Along the same lines, storing years in a int column is only going to be a waste of storage space. The same can be said about small lookup tables with just a handful of rows in them, where the key column can be a smallint or even a tinyint: it won’t save much space in the lookup table itself, but it can save lots of space in the main tables (with many more rows) where the code is referenced.
- Storing fixed-size information in varchar columns: Similarly to the previous sin, when your attribute has a fixed character size, there is no point in using a varying character type. If your attribute has exactly 3 characters, why use varchar(3)?
Extra evil bonus: varchar(1) will get you double points.
- Storing duration in time or datetime columns: Datetime and time represent points in time and they are not meant for storing durations. If you really want to store a duration, use a numeric column to store the number of seconds (it’s the ANSI standard unit measure for representing a duration). Even better, you could store the start/end date and time in two separate datetime columns. SQL Server 2016 also supports periods.
- Getting Unicode wrong: Choosing nvarchar for attributes that will never contain Unicode data and choosing varchar for attributes that can contain Unicode data are equally evil and will get you instant damnation. For instance, a ZIP code will only contain numeric characters, so using Unicode data types will have the only outcome of wasting space. At the same time, storing customer business names or annotations in varchar columns means that you won’t be able to persist international characters. While it may appear quite unlikely that such characters will ever appear in your database, you will regret your decision when that happens (and it will).
- Messing with XML: I’m not a big fan of XML in the database, but sometimes it can come handy. Storing XML data in a plain varchar column is a very bad idea. The XML data type provides validation rules that won’t allow in invalid or malformed XML and also provides functions to manipulate the XML data. Storing schema-less XML is another bad idea: if you have an XML schema use it, otherwise you will end up saving invalid data. On the other hand, using XML to go “beyond relational” and mimic Oracle’s nested tables will only get you damned. Fun times.
- Using different data types in different tables for the same attribute: there’s only one thing worse than getting your data types wrong: getting them wrong in multiple places. Once you decided the data type to store an attribute, don’t change your mind when designing new tables. If it is a varchar(10), don’t use varchar(15) in your next table. Usually proper foreign key constraints help you avoid this issue, but it’s not always the case.
If this query returns rows, chances are that you have schizophrenic columns in your database schema:WITH my_schema AS ( SELECT OBJECT_NAME(c.object_id) AS table_name, c.name AS column_name, t.name AS type_name, c.max_length, c.precision, c.scale FROM sys.columns AS c INNER JOIN sys.types AS t ON c.system_type_id = t.system_type_id ), incarnations AS ( SELECT *, DENSE_RANK() OVER ( PARTITION BY column_name ORDER BY type_name, max_length, precision, scale ) AS incarnation_number FROM my_schema ), incarnation_count AS ( SELECT *, MAX(incarnation_number) OVER ( PARTITION BY column_name ) AS incarnation_count FROM incarnations ) SELECT * FROM incarnation_count WHERE incarnation_count > 1 ORDER BY incarnation_count DESC, column_name, type_name, max_length, precision, scale;
The lack of proper constraints will be the topic of the next post, when we will meet the anarchic designers. Stay tuned!
SQL Server Infernals – Circle 2: Generalizers
Object-Oriented programming taught us that generalizing is a good thing and, whenever possible, we should do it. Complex class hierarchies are a good way of reusing code, hitting the specialized classes only when a special implementation is needed.
In the database world, the concept doesn’t play exactly well.
What they say in Heaven
In Heaven, there is a lookup table for each attribute, no matter how simple and no matter how small is the lookup table.
For instance, if your database is about sales, you probably have a Customers table and an Orders table, each with its own attributes resolved through a Foreign Key. The lookup tables are usually very small, with just a handful of rows in them:

Temptation comes from our own desires
Wouldn’t that be great if you could stop adding small, insignificant tables to your database schema? Wouldn’t it be a lot easier if you had ONE table to store all that lookup nonsense? “Less is more” after all, isn’t it?
If you had a “One True Lookup Table”, everything would be more elegant and simple. Look at this database schema:

Isn’t it elegant and clean?
Whenever you need a new lookup table, you just have to add rows to your OTLT™ (thanks Phil Factor for the acronym):
INSERT INTO LookupTable
(table_name, lookup_code, lookup_description)
VALUES
('Order_Status', 'OP', 'Open'),
('Order_Status', 'CL', 'Closed'),
('Order_Status', 'SH', 'Shipped');
Devil’s in the details
You may have less tables to deal with now, but there’s a price to pay. A bigger price than you would have expected.
- No foreign keys: Did you notice that the foreign keys are gone? In order to create a foreign key, you would have to add the lookup table name to the Orders and Customers tables, for each attribute stored in the lookup table. I don’t think you would like it.
- Generic data type: In order to merge all lookup tables in one, you need to choose a “generic” data type that fits for all. The most generic data type is a character-based type, so you’ll probably end up with a huge nvarchar column. You probably don’t want the same huge column in the referencing tables and you could end up having different data types between the main tables and the lookups. One more not-so-good idea. Moreover, when you’re joining your tables with the lookup table, you will have implicit (or explicit) conversions happening, which is a performance nightmare.
- Single Hotspot: Instead of hitting multiple tables for lookups, everyone will hit the same table over and over. This will create a hotspot in the database, with locking and latching issues all over the place.
- Acrobatic constraints: Defining constraints on a generic table becomes very difficult. Not an impossible deal, but very difficult. For the schema in this example, you could define a CHECK constraint to enforce the use of the correct data type, but the syntax of the constraint will not be very straightforward:
CHECK( CASE WHEN lookup_code = 'states' AND lookup_code LIKE '[A-Z][A-Z]' THEN 1 WHEN lookup_code = 'priorities' AND lookup_code LIKE '[0-9]' THEN 1 WHEN lookup_code = 'countries' AND lookup_code LIKE '[0-9][0-9][0-9]' THEN 1 WHEN lookup_code = 'status' AND lookup_code LIKE '[A-Z][A-Z]' THEN 1 ELSE 0 END = 1 )
It could get even worse
As soon as you start to realize that trading multiple lookup tables for an OTLT is not a good deal, devil will raise the bid and offer the ultimate generalization: the Entity Attribute Value, also known as “EAV”.
If you come to think of it, who needs fixed attributes in a table when you can have as many attributes as you want in a general-purpose table? Why messing with ALTER TABLE statements when you can have a single table that can store an infinite number of attributes that you can bind to any row in any table?
A typical EAV schema looks like this:

This way, you can have any type of attribute bound to your main entities. For instance, to define a “ship_date” attribute in your Orders table, you just have to insert a couple of rows in your EAV schema:
INSERT INTO Entities
(entity_id, entity_name)
VALUES
(1, 'Orders');
INSERT INTO AttributeNames
(attribute_id, entity_id, attribute_name)
VALUES
(1, 1, 'ship_date');
INSERT INTO AttributeValues
(attribute_id, entity_id, id, value)
VALUES
(1, 1, 123, '2015-06-24 22:10:00.000');
Looks like a great idea, doesn’t it? Unfortunately, it is not.
- Generic data types: again, what would prevent a date such as ‘2015-02-30 18:30:00.000’ from being assigned to the ship date? Uh-oh: nothing.
- No foreign keys: again, enforcing foreign key constraints would be impossible.
- A single hotspot in the database: every attribute for every table involved in this nonsense would have to be looked up in the same table.
- No constraints: how would you enforce a constraint as simple as “NOT NULL”? Good luck with that.
- Dreadful reporting queries: when you will be asked to create a report on a table that uses this paradigm (I said “when”, not “if”, because it will happen), you will have to OUTER JOIN to the EAV table for each and every attribute that you want to retrieve. In case you are wondering if this is good or bad, take into account that the optimizer starts to freak out when it finds too many JOINS in a query and will likely timeout looking for a decent execution plan, feeding you the best it could come up with (usually, a mess).
It depends?
Some software solutions are entirely based on user-defined attributes and the ability to define them is a central feature. For instance, many CRM solutions are heavily dependent on user-defined attributes. However, there are many ways to achieve the same results without resorting to an EAV design. For instance, one could wonder why ALTERing the database schema seems to be a less desirable solution.
There are also many flavors of EAV, with different degrees of evil involved. Some implementations at least provide different columns for different data types, some others use XML or JSON.
The EAV design comes with the intent of solving a real world problem that doesn’t have a definitive answer in the relational model. In partial defense of the “generalizers”, it has to be said that this is a challenging problem. Nevertheless, like Dante put his political enemies to hell, I am the “poet” and I’m afraid that the generalizers will have to get accustomed to sulfur. It just takes a couple of thousand years, after all.
Who will be damned next?
In the next circle of the SQL Server hell we will meet the shaky typers – the poor souls that chose the wrong data types for their columns. Stay tuned for more!
SQL Server Infernals – Circle 1: Undernormalizers
There’s a special place in the SQL Server Hell for those who design their schema without following the Best Practices. In this first episode of SQL Server Infernals, we will explore together the Row of the Poor Schema Designers, also known as “undernormalizers”.
What they say in Heaven
In Heaven, where all Best Practices are followed and everything runs smoothly while angels sing, they design their databases following the rules of normalization. Once upon a time, there was a man who spent a considerable amount of his life working on defining the rules of the relational model. That man was Edgar Codd.
Mr. Codd laid down the rules of normalization, which are known as “normal forms”. The normal forms define the attributes of a well-designed database schema. While there are more normal forms, it is widely accepted that a schema is normalized when it follows the first three normal forms. Here is the simplest possible enunciations of each:
- 1NF – Every relation has a primary key, every relation contains only atomic attributes
- 2NF – 1NF + Every attribute in a relation depends on the whole key
- 3NF – 2NF + Every attribute in a relation depends only on the key
In a single line: “The key, the whole key, nothing but the key (so help me Codd)”.
Clues you’re doing it wrong
- Repeating data (redundancies): the same information has to be saved in multiple places
- Inconsistent data between tables (anomalies): the same information has different values in different tables
- Data separated by commas
- Structured data in “note” columns
- Columns with a numeric suffix (e.g. Zone1, Zone2, Zone3…)

What will put you to hell
- No primary key: did you notice that the normal forms talk about “relations” rather than “tables”? The relational model is a mathematical model, which, at some point has to be translated to a physical implementation. Tables are exactly this: the physical implementation of relations.
If your table has no primary key and relations must have a primary key, chances are that your table is the physical implementation of something else (a bin, a pile, a bag… whatever: not a relation anyway).
When tables have no primary key, any data can be stored inside them, even duplicate rows. Once duplicate data is inside the table, there is no way to tell which row is good and which one is the duplicate.
- Surrogate keys only: this is in fact a variation on the “no primary key” sin: if your table has a surrogate key (such as an identity or uniqueidentifier column), make sure that it is not the only unique key in the table, otherwise you will end up storing duplicates, with only the surrogate key as a difference. This is no different from having no primary key at all.
If you decide that your table is best implemented with a surrogate key (often because the natural key is composite or too wide), make sure that you create a UNIQUE constraint on the natural key.
- Non-atomic attributes: if your table has columns that contain multiple values, the likelihood of a design mistake goes to the roof. For instance, when you find data such as “sales@company.com,marketing@company.com” in a “email” column, chances are that the designer of the database forgot to take into account that the entity (for instance a customer) might have multiple email addresses.
While many efficient split algorithms are available, storing the data in this format has many downsides:- Indexing individual items is impossible
- Searching for individual items is hard
- Updating an item requires writing the whole comma separated value
- Locking a single item is impossible (reduced concurrency)
- CHECK constraints are hard to implement
Whenever you find non-atomic attributes, be prepared to refactor the database schema, because something is really wrong and there is no way to fix it without moving the attribute to a different table.
- Use of NULL when not necessary: NULL is a constraint on the data: if an attribute is mandatory, make it mandatory! Allowing NULLs on mandatory data will open the door to data that does not meet the business rules. What are you doing with rows that are missing mandatory attributes?
If your table has too many NULLs in it, you probably have designed it wrong and you are trying to fit too many attributes in a single table (an implicit dependency?): move them to a separate table.
- Use of dummy data: The other side of the coin is “no NULLs allowed anywhere”. Not all attributes are mandatory: if you pretend it is so, the users will start putting dummy data into your columns to work around the restriction. Typical examples are “.” or empty strings for character-based columns and “0” for numeric-based columns. Once those dummy values are in, can you tell the difference between “dummy” zeros and “real” zeros? Of course you can’t.
- Designing the database when specs are incomplete/unclear: This is the worst of all mistakes. Changing the database schema once it is in production is a bloodbath: everything built on top of that schema will have to change. Many of the design mistakes described above are the consequence of incomplete specifics or lack of analysis.
It is discouraging to note how some popular design patterns do not take into account the intrinsic complexity of refactoring a database schema and demand the implementation of the schema to automated tools, based on the object classes that represent the domain. Yes, I’m talking about you, Code First. In my book, “code first” is a synonym of “design someday”. Don’t let any automated tool design your database schema: you know better than that!
- Premature denormalization: some devil’s advocates will tell you that normalization slows down the database and that you should be denormalizing your schema from the start. Don’t believe what they say! Most normalized schemas can cope with sustained reads and SQL Server offers many features (such as indexed views) to deal with high numbers of joins, which is usually the point for denormalization. Of course, if you’re working on a BI project, denormalization is expected and desirable instead.
An old saying goes: “Normalize ‘til it hurts, then denormalize ‘til it works”, but there’s nothing preventing the database from working on a normalized schema. If reads on the database are slow, it is quite unlikely that the cause is over-normalization: it is much more presumable that your queries and/or your indexessuckare sub-optimal.
In the next episode of SQL Server Infernals I will discuss a particular database design sin: the dynamic schema. Stay tuned for more.
Announcing SQL Server Infernals
Today I’m starting a new blog series called “SQL Server Infernals”.
Throughout this series, I will take your hand and walk you through the hell of SQL Server Worst Practices, as Virgil did with Dante in his Commedia.
You may ask why you should care about worst practices, when you have loads of great sources for Best Practices. The answer is that they are not enough.
- There are too many Best Practices: how are you supposed to know all of them?
- There is no time to follow them all: when you’re in a hurry, sometimes it’s enough to know that you’re not doing it completely wrong.
- They seem to be all equally important: experience helps you understand which Best Practices really are important and which ones are not.
- It’s not always clear what happens when you don’t follow them.
On the other hand, Worst Practices can help you understand what threat is behind the corner:
- They show you the mistakes to avoid
- You can learn from someone else’s mistakes (I made plenty throughout my career…)
Obviously, as usual, it depends: not everything is black or white and sometimes you will find in this blog series something that not everyone will agree is a Worst Practice. Sometimes you are forced by some constraint to adopt a solution that you will find here listed as a bad idea. No problem: nobody is pointing a finger at your work.
I will break the Worst Practices in categories, each one related to a specific area of SQL Server:
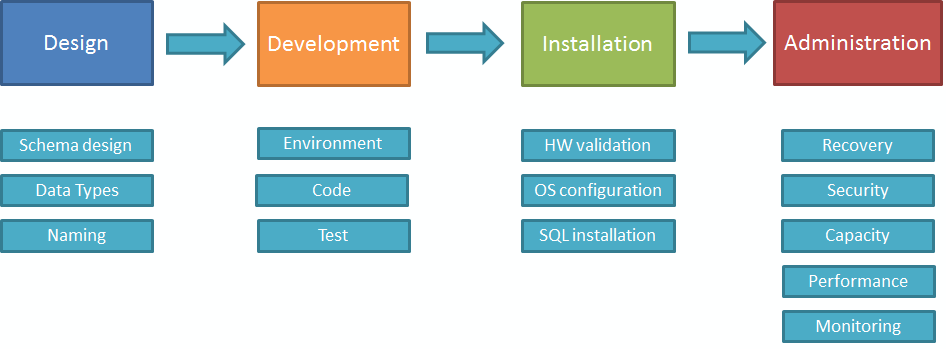
Stay tuned for your walk through the SQL Server hell!
Your pilgrim’s guide,
The SpaghettiDBA
Native Client Aliases don’t like Trailing Spaces
I usually don’t post small things like this, but today I fought with this obnoxious problem long enough to convince me that it deserved a shout out to the community.
When you create an alias in the SQL Server Configuration Manager, make sure that the alias name contains no spaces, otherwise it won’t work as you expect.
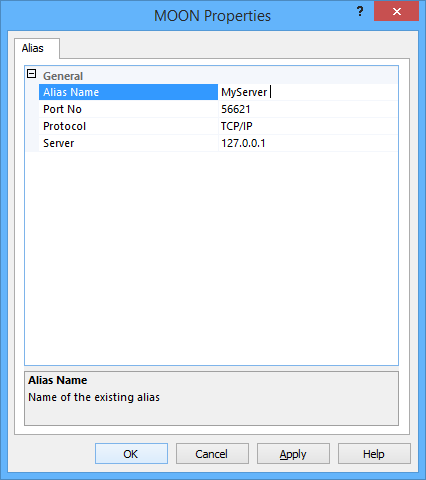
In my case, I had a Reporting Services instance with many data sources pointing to a SQL Server instance (let’s call it MyServer) and I wanted to redirect connections to a different instance using an alias. So I opened Configuration Manager and created an alias like this:

To my great surprise, the alias didn’t work and it took quite some time to notice that something was wrong. The server “MyServer” was a perfectly working existing instance of SQL Server, so no connection was dropped: they all just happened to contact the wrong server. If spotting the problem was hard, fixing it turned out to be even harder: why on earth did the alias refuse to work, while all other aliases were working perfectly?
It turned out to be the simplest of all answers: a trailing space in the alias name.
Just looking at the alias properties it wasn’t too obvious that something was off, but clicking on the alias name field, the cursor appeared slightly more on the right than it should have been:
Bottom line is: always check your assumptions, because problems like to hide where you won’t search for them.
Counting the number of rows in a table
Don’t be fooled by the title of this post: while counting the number of rows in a table is a trivial task for you, it is not trivial at all for SQL Server.
Every time you run your COUNT(*) query, SQL Server has to scan an index or a heap to calculate that seemingly innocuous number and send it to your application. This means a lot of unnecessary reads and unnecessary blocking.
Jes Schultz Borland blogged about it some time ago and also Aaron Bertrand has a blog post on this subject. I will refrain from repeating here what they both said: go read their blogs to understand why COUNT(*) is a not a good tool for this task.
The alternative to COUNT(*) is reading the count from the table metadata, querying sys.partitions, something along these lines:
SELECT SUM(p.rows)
FROM sys.partitions p
WHERE p.object_id = OBJECT_ID('MyTable')
AND p.index_id IN (0,1); -- heap or clustered index
Many variations of this query include JOINs to sys.tables, sys.schemas or sys.indexes, which are not strictly necessary in my opinion. However, the shortest version of the count is still quite verbose and error prone.
Fortunately, there’s a shorter version of this query that relies on the system function OBJECTPROPERTYEX:
SELECT OBJECTPROPERTYEX(OBJECT_ID('MyTable'),'cardinality')
Where does it read data from? STATISTICS IO doesn’t return anything for this query, so I had to set up an Extended Events session to capture lock_acquired events and find out the system tables read by this function:

Basically, it’s just sysallocunits and sysrowsets.
It’s nice, short and easy to remember. Enjoy.
How to post a T-SQL question on a public forum
If you want to have faster turnaround on your forum questions, you will need to provide enough information to the forum users in order to answer your question.
In particular, talking about T-SQL questions, there are three things that your question must include:
- Table scripts
- Sample data
- Expected output
Table Script and Sample data
Please make sure that anyone trying to answer your question can quickly work on the same data set you’re working on, or, at least the problematic part of it. The data should be in the same place where you have it, which is inside your tables.
You will have to provide a script that creates your table and inserts data inside that table.
Converting your data to INSERT statements can be tedious: fortunately, some tools can do it for you.
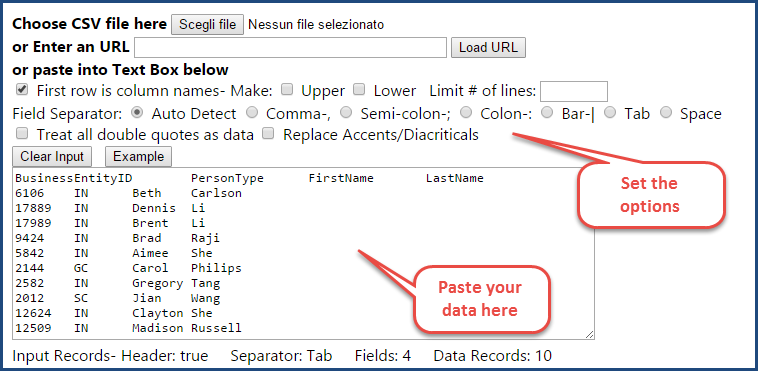
How do you convert a SSMS results grid, a CSV file or an Excel spreadsheet to INSERT statements? In other words, how do you convert this…

into this?
USE [tempdb] GO CREATE TABLE [dbo].[Person]( [BusinessEntityID] [int] NOT NULL PRIMARY KEY CLUSTERED, [PersonType] [nchar](2) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL ) GO INSERT INTO Person VALUES (6106,'IN','Beth','Carlson'); INSERT INTO Person VALUES (17889,'IN','Dennis','Li'); INSERT INTO Person VALUES (17989,'IN','Brent','Li'); INSERT INTO Person VALUES (9424,'IN','Brad','Raji'); INSERT INTO Person VALUES (5842,'IN','Aimee','She'); INSERT INTO Person VALUES (2144,'GC','Carol','Philips'); INSERT INTO Person VALUES (2582,'IN','Gregory','Tang'); INSERT INTO Person VALUES (2012,'SC','Jian','Wang'); INSERT INTO Person VALUES (12624,'IN','Clayton','She'); INSERT INTO Person VALUES (12509,'IN','Madison','Russell'); GO
The easiest way to perform the transformation is to copy all the data and paste it over at ConvertCSV:


Another great tool for this task is SQLFiddle.
OPTIONAL: The insert statements will include the field names: if you want to make your code more concise, you can remove that part by selecting the column names with your mouse holding the ALT key and then delete the selection. Here’s a description of how the rectangular selection works in SSMS 2012 and 2014 (doesn’t work in SSMS 2008).
Expected output
The expected output should be something immediately readable and understandable. There’s another tool that can help you obtain it.
Go to https://ozh.github.io/ascii-tables/, paste your data in the “Input” textarea, press “Create Table” and grab your table from the “Output” textarea.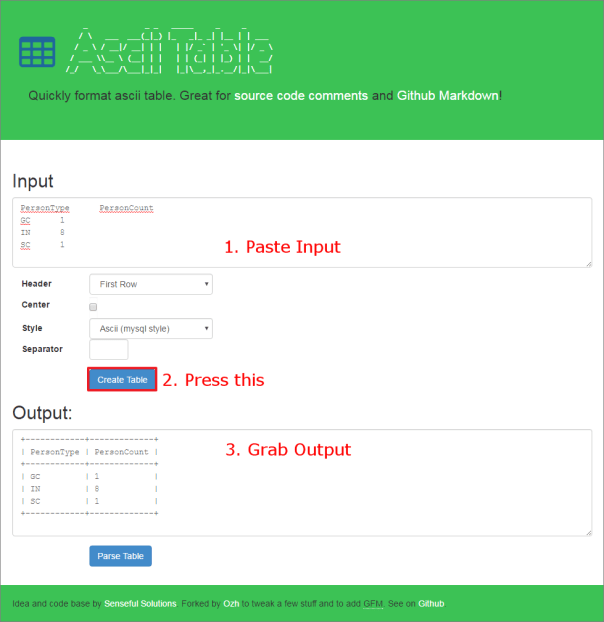 Here’s what your output should look like:
Here’s what your output should look like:
+------------+-------------+ | PersonType | PersonCount | +------------+-------------+ | GC | 1 | | IN | 8 | | SC | 1 | +------------+-------------+
Show what you have tried
Everybody will be more willing to help you if you show that you have put some effort into solving your problem. If you have a query, include it, even if it doesn’t do exactly what you’re after.
Please please please, format your query before posting! You can format your queries online for free at PoorSQL.com
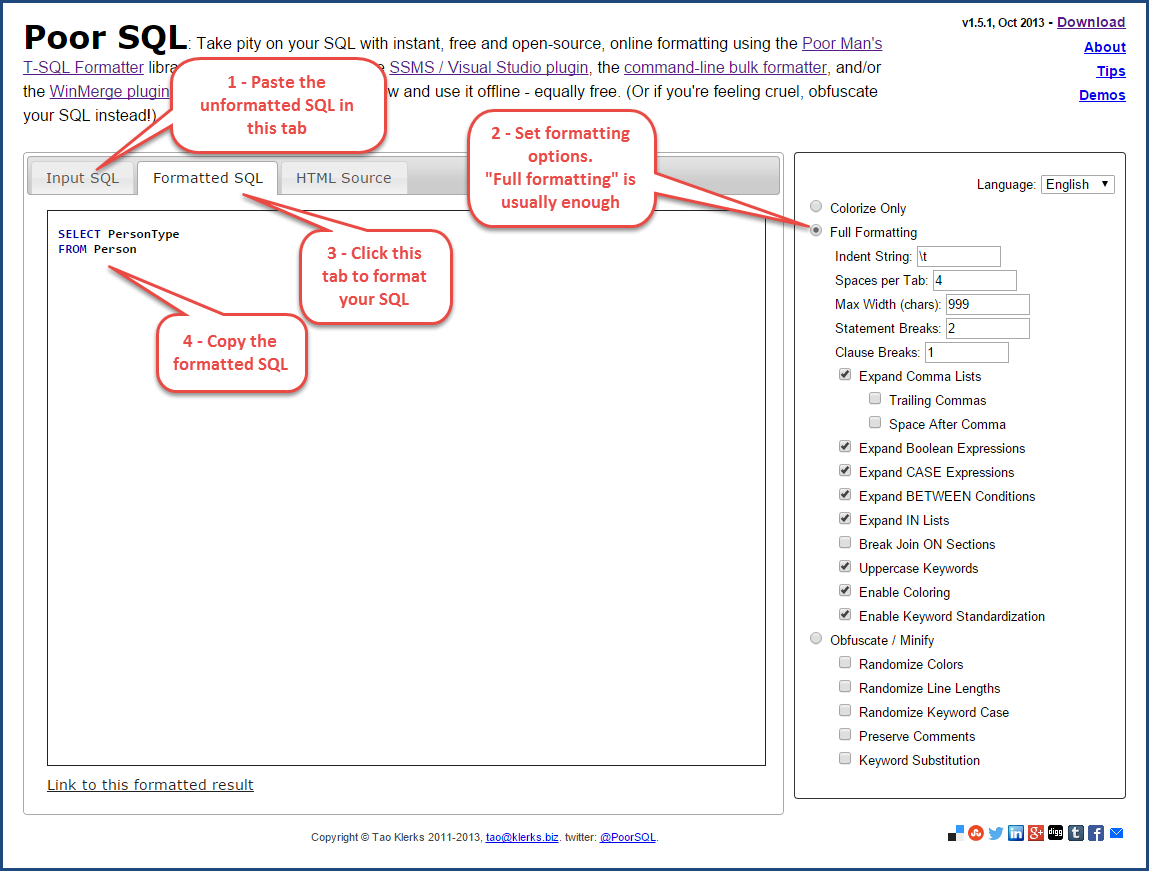
Simply paste your code then open the “Formatted SQL” tab to grab your code in a more readable way.
Putting it all together
Here is what your question should look like when everything is ok:
Hi all, I have a table called Person and I have to extract the number of rows for each person type.
This is the table script and some sample data:
USE [tempdb] GO CREATE TABLE [dbo].[Person]( [BusinessEntityID] [int] NOT NULL PRIMARY KEY CLUSTERED, [PersonType] [nchar](2) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL ) GO INSERT INTO Person VALUES (6106,'IN','Beth','Carlson'); INSERT INTO Person VALUES (17889,'IN','Dennis','Li'); INSERT INTO Person VALUES (17989,'IN','Brent','Li'); INSERT INTO Person VALUES (9424,'IN','Brad','Raji'); INSERT INTO Person VALUES (5842,'IN','Aimee','She'); INSERT INTO Person VALUES (2144,'GC','Carol','Philips'); INSERT INTO Person VALUES (2582,'IN','Gregory','Tang'); INSERT INTO Person VALUES (2012,'SC','Jian','Wang'); INSERT INTO Person VALUES (12624,'IN','Clayton','She'); INSERT INTO Person VALUES (12509,'IN','Madison','Russell');This is what I’m trying to obtain:
+------------+-------------+ | PersonType | PersonCount | +------------+-------------+ | GC | 1 | | IN | 8 | | SC | 1 | +------------+-------------+Here is what I have tried:
SELECT PersonType FROM PersonHow do I do that?
If you include this information in your posts, I promise you will get blazingly fast answers.
