Blog Archives
Expensive Enterprise Backup Tools – A survival guide
If you’re working for a big company, chances are that your IT already has a strategy and tools for dealing with backups. Many objects need to backed up (files, emails, virtual machines, databases…) and vendors are happy to provide software solutions for all those needs.
Usually, the first type of object that has to be protected is files: every company, even the smaller ones, have file servers with lots of data that has to be regularly backed up, so the data protection solution found in the majority of companies is typically built around the capabilities and features of backup tools designed and engineered for protecting the file system.
The same tools are probably capable of taking backups of different types of objects, by means of “plug-ins” or “agents” for databases, e-mail servers, virtual machines and so on. Unfortunately, those agents are often delusional and fail to deliver what they promise.
With regard to SQL Server database backups, these are the most common issues:
1. Naming things wrong
It’s not surprising that backup tools built for protecting the file system fail to name things properly when it comes down to database backups. What you often find is that transaction log backups are called “incremental backups” or full backups are instead called “snapshots”, according to whichever the naming convention is in the main file system backup process. It’s also not uncommon to find transaction log backups going under the name of “archive log backups”, because this is what they are called like in Oracle. This naming mismatch is potentially dangerous, because it can trick the DBA into choosing the wrong type of backup. The term “DBA” is not used here by accident, which takes us to the next point.
2. Potentially dangerous separation of duties
Backup tools are often run and controlled by windows admins, who may or may not be the same persons responsible for taking care of databases. Well, surprise: if you’re taking backups you’re responsible for them, and backups are the main task of the DBA, so… congrats: you’re the DBA now, like it or not.
If your windows admins are not ok with being the DBA, but at the same time are ok with taking backups, make sure that you discuss who gets accountable for data loss when thing go south. Don’t get fooled: you must not be responsible for restores (which, ultimately, is the reason why you take backups) if you don’t have control over the backup process. Period.
3. One size fits all

Some backup tools won’t allow you to back up individual databases with special schedules and policies, but will try to protect the whole instance as an atomic object, with a “one size fits all” approach. Be careful not to trade safety for simplicity.
4. Missing backup / restore options
Most (if not all) third-party backup tools do not offer the same flexibility that you have with native backups, so you will probably miss some of the backup/restore options. I’m not talking about overly exotic options such as KEEP_REPLICATION or NEW_BROKER: in some cases you may not be able to restore with NORECOVERY. Whether this is going to be a problem or not, only you can tell: go and check the possibilities of your data protection tool, because you might need a feature that is unavailable and you might need it when it’s too late.
5. Dangerous internal workings
Not all backup tools behind the covers are acting as you would expect. For instance, Microsoft Data Protection Manager (DPM) is unable to take transaction log backups streaming them directly to the backup server, but needs to write the backup set to a file first. I bet you can see what’s wrong with this idea: if your transaction log is growing due to an unexpected spike in activity, the only way to stop if from growing and eventually fill the disk is to take a t-log backup, but the backup itself will have to be written to disk. In the worst case, you won’t have enough disk space to perform the backup, so it will simply fail. In a similarly catastrophic scenario, the transaction log file may try to grow again while the log backup is being taken, resulting in failure to allocate disk space.It is incredibly ironic how you need disk space to perform a backup and you need a backup to release disk space, so I am just going to guess that the developers of DPM were simply trying to be funny when they designed this mechanism.
6. Incoherent schedules
Some backup tools are unable to provide a precise schedule and instead of running the backup operation when due, they add it to a queue that will eventually run everything. This may look like a trivial difference, but it is not: if your RPO is, let’s say, 15 minutes, transaction log backups have to occur every 15 minutes at most, so having transaction log backups executed from a queue would probably mean that some of them will exceed the RPO if at least one of the backups takes longer than usual. Detecting this condition is fairly simple: you just have to look at your backupset table in msdb.
7. Sysadmin privileges
All third-party backup applications rely on an API in SQL Server which is called “Virtual Device Interface” (or VDI in short). This API allows SQL Server to treat backup sessions from your data protection tool as devices, and perform backup/restore operations by using these devices as source/destination.
One of the downsides of VDI is that it requires sysadmin privileges on the SQL Server instance and Administrator privileges on the Windows box. In case you’re wondering, no: it’s not strictly necessary to have sysadmin privileges to back up a database.
8. VSS backups
A number of backup tools rely on taking VSS snapshots of the SQL Server databases. SQL Server supports VSS snapshots and has a provider for that. Unfortunately, it’s not impossible to see VSS backups interfering with other types of backups and/or failures initializing the VSS provider, which require a reboot to fix.
9. VM backups
Some backup vendors are more focused on backing up the whole virtual machine rather than the single database / instance that you want to protect. Taking a whole machine backup is different and you have to make sure that you understand what that means, especially compared to taking full, diff or log backups. For instance, did you know that taking VM backups is based on the snapshot feature of the hypervisor, which in turn runs VSS backups of snapshot-aware software, like SQL Server?
10. Interfere with other features
Oftentimes, these enterprise-grade super-expensive backup tools live on the assumption that they’re the only one tool you will ever use, and refuse to play nicely with other SQL Server features. For instance, they will happily try to back up transaction log for databases that are part of log shipping (see point #3), ending up with broken log chains.
11. Agents
All backup tools that take advantage of the VDI API require that you install an agent application locally on the SQL Server machine. While having an agent running on the windows machine is not overly concerning per se, on the other hand this means that the agent itself will have to be patched and upgraded from time to time, often requiring that you restart the machine to apply changes.
This also means that you might run into bugs in the agent that could prevent taking backups until you patch/upgrade the agent itself.
12. Illogical choices
Some data protection tools will force illogical policies and schedules on you for no reason whatsoever. For instance, EMC Networker cannot take transaction log backups of master and model (which must/should be in simple recovery anyway), so when you schedule transaction log backups for all databases on the instance, it won’t skip them, but take a full backup instead. Both databases are usually quite small, but still, taking a full backup every 15 or 5 minutes is less than ideal.
13. Not designed with availability in mind
Backing up the file system is very different from backing up SQL Server databases, as one might expect. One of the key differences is that with SQL Server databases you don’t have to deal with RPO and RTO only, but the way that you back up your databases can have a serious impact on the availability of the databases itself. To put that simply: if you don’t take transaction log backups, nothing truncates your logs, so it keeps growing and growing until space runs out either on the log file (and the database stops working) or on the disk (and the whole instance stops working). Backup operations are critical for RDBMSs: if something or somebody commits to performing backups every x minutes, that commitment MUST be fulfilled. For the record, many backup tools that offer the “one size fits all” approach will try to take full and transaction logs on the same schedule, so they will simply skip transaction log backups while taking full backups. This means that you might be exceeding your RPO, with no clear indication of that happening.
14. No support for SQL Server compression or encryption
A number of backup tools offer their own compression and encryption features (again, because the file system does not offer those), so they will try in each and every possible way to push their shiny-enterprise-expensive features instead of what you already have.
Compression helps keeping the backup and restore times under control, by keeping the size of the backup sets small: this means that the number of bytes that travels across the network will be smaller. Nowadays, the majority of backup solutions supports Data Domain or equivalent solutions: smart storage appliances that offer powerful compression and deduplication features to avoid storing the same information multiple times. These dedupe features can be incredibly effective and reduce immensely the amount of disk space needed for storing backups. Some data domains offer deduplication inside the appliance itself: data has to travel the network and reach the data domain, which takes care of breaking the file in blocks, calculate a hash on the blocks and store only the blocks whose hash was not found inside the data domain. This behavior is already clever enough, but some data domains improved it even further, with host deduplication (DDBoost, to name the most prominent product). Basically, what happens with host deduplication is that the hash of the blocks is calculated on the host and not on the data domain: in this way, all the duplicate blocks do not need to travel across the network, hence reducing the amount of time needed for backup operations.
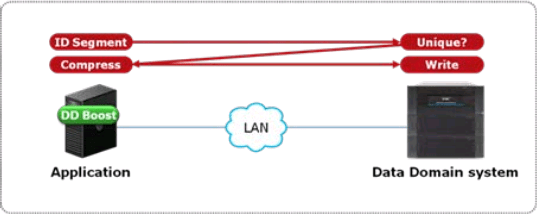
These dedupe technologies are incredibly useful and also allow backup admins to show to their boss all those shiny charts that depict how cleverly the data domain is reducing disk usage across the board. This is going to be so amazing that the backup admin will not allow you to deteriorate his exceptional dedupe stats by using any backup option that prevents deduplication from happening. The two main enemies of Data Domain efficiency are compression and encryption in the source data. Compression of similar uncompressed files does not produce similar compressed files, so chances of deduplication are much slimmer. Encryption of backups is non-deterministic, which means that two backup sets of the same exact database will be completely different, bringing down deduplication rates close to zero.
While the need for encryption is probably something that your backup admins could live with, they will try in every possible way to make you get rid of backup compression. Letting the data domain take care of compression and deduplication can be acceptable in many cases, but it must not be a hard rule, because of its possible impact on RTO.
The real issue with deduplication can be dramatically evident at restore time: the advantage of deduplication will be lost, because all the blocks that make up your backups will have to travel across the network.
Long story short: at backup time, deduplication can be extremely effective, but, at restore time, backup compression can be much more desirable and can make the difference between meeting and not meeting your RTO.
15. No separation of duties
What often happens with general-purpose backup tools is that management of a single object type is not possible. A number of tools will allow you to be a backup admin on the whole infrastructure or nothing, without the ability to manage database backups only. This may or may not be a problem, depending on how dangerous your windows admins consider your ability to manage the backup schedules of Exchange servers and file servers.
Some tools offer the possibility to create separate tenants and assign resources and schedules to particular tenants, each with its own set of administrators. This feature often comes with limitations, such as the inability to share resources throughout multiple tenants: if tape drives can be assigned to a single tenant and the company only owns a single tape drive, this option obviously goes out of the table.
16. No management tools
Often, the management tools offered by these backup vendors are simply ridiculous. Some use web applications with java applets or similar outdated/insecure technologies. Some offer command line tools but no GUI tools, some the other way around. The main takeaway is: make sure that your backup vendor gives you the tools that you need, which must include a command line or anything that can be automated.
17. Ridiculous RPO/RTO
The developers of some backup tools (DPM, I’m looking at you) decided that forcing a minimum schedule frequency of 15 minutes was a great idea. Well, in case you’re wondering, it’s not.
Other tools manage the internal metadata so dreadfully that loading the list of available backup sets can take forever, hence making restores excruciating exercises, that often fall outside of the requested RTO.
Make sure that tool you are using is able to deliver the RPO and RTO you agreed upon with the owners of the data.
Bottom line is: don’t let your backup vendor impose the policies for backups and restores. Your stakeholders are the owners of the data and everyone else is not entitled to dictate RPOs and RTOs. Make sure that your backup admins understand that your primary task is to perform restores (not backups!) and that the tool they are using with Exchange might not be the best choice for you. Talk to your backup admins, find the best solution together and test it across the board, with or without the use of third party tools, because, yes, native SQL Server backups can be the best choice for you.
COPY_ONLY backups and Log Shipping
Last week I was in the process of migrating a couple of SQL Server instances from 2008 R2 to 2012.
In order to let the migration complete quickly, I set up log shipping from the old instance to the new instance. Obviously, the existing backup jobs had to be disabled, otherwise they would have broken the log chain.
That got me thinking: was there a way to keep both “regular” transaction log backups (taken by the backup tool) and the transaction log backups taken by log shipping?

The first thing that came to my mind was the COPY_ONLY option available since SQL Server 2005.
You probably know that COPY_ONLY backups are useful when you have to take a backup for a special purpose, for instance when you have to restore from production to test. With the COPY_ONLY option, database backups don’t break the differential base and transaction log backups don’t break the log chain.
My initial thought was that I could ship COPY_ONLY backups to the secondary and keep taking scheduled transaction log backups with the existing backup tools.
I was dead wrong.
Let’s see it with an example on a TEST database.
I took 5 backups:
- FULL database backup, to initialize the log chain. Please note that COPY_ONLY backups cannot be used to initialize the log chain.
- LOG backup
- LOG backup with the COPY_ONLY option
- LOG backup
- LOG backup with the COPY_ONLY option
The backup information can be queried from backupset in msdb:
SELECT
ROW_NUMBER() OVER(ORDER BY bs.backup_start_date) AS [backup #]
,first_lsn
,last_lsn
,backup_start_date
,type
,is_copy_only
,DENSE_RANK() OVER(ORDER BY type, bs.first_lsn) AS sequence
FROM msdb.dbo.backupset bs
WHERE bs.database_name = 'TEST'

As you can see, the COPY_ONLY backups don’t truncate the transaction log and losing one of those backups wouldn’t break the log chain.
However, all backups always start from the first available LSN, which means that scheduled log backups taken without the COPY_ONLY option truncate the transaction log and make significant portions of the transaction log unavailable in the next COPY_ONLY backup.
You can see it clearly in the following picture: the LSNs highlighted in red should contain no gaps in order to be restored successfully to the secondary, but the regular TLOG backups break the log chain in the COPY_ONLY backups.

That means that there’s little or no point in taking COPY_ONLY transaction log backups, as “regular” backups will always determine gaps in the log chain.
When log shipping is used, the secondary server is the only backup you can have, unless you keep the TLOG backups or use your backup tool directly to ship the logs.
Why on earth should one take a COPY_ONLY TLOG backup (more than one at least) is beyond my comprehension, but that’s a whole different story.
Copy user databases to a different server with PowerShell
Sometimes you have to copy all user databases from a source server to a destination server.
Copying from development to test could be one reason, but I’m sure there are others.
Since the question came up on the forums at SQLServerCentral, I decided to modify a script I published some months ago to accomplish this task.
Here is the code:
## =============================================
## Author: Gianluca Sartori - @spaghettidba
## Create date: 2013-10-07
## Description: Copy user databases to a destination
## server
## =============================================
cls
sl "c:\"
$ErrorActionPreference = "Stop"
# Input your parameters here
$source = "SourceServer\Instance"
$sourceServerUNC = "SourceServer"
$destination = "DestServer\Instance"
# Shared folder on the destination server
# For instance "\\DestServer\D$"
$sharedFolder = "\\DestServer\sharedfolder"
# Path to the shared folder on the destination server
# For instance "D:"
$remoteSharedFolder = "PathOfSharedFolderOnDestServer"
$ts = Get-Date -Format yyyyMMdd
#
# Read default backup path of the source from the registry
#
$SQL_BackupDirectory = @"
EXEC master.dbo.xp_instance_regread
N'HKEY_LOCAL_MACHINE',
N'Software\Microsoft\MSSQLServer\MSSQLServer',
N'BackupDirectory'
"@
$info = Invoke-sqlcmd -Query $SQL_BackupDirectory -ServerInstance $source
$BackupDirectory = $info.Data
#
# Read master database files location
#
$SQL_Defaultpaths = "
SELECT *
FROM (
SELECT type_desc,
SUBSTRING(physical_name,1,LEN(physical_name) - CHARINDEX('\', REVERSE(physical_name)) + 1) AS physical_name
FROM master.sys.database_files
) AS src
PIVOT( MIN(physical_name) FOR type_desc IN ([ROWS],[LOG])) AS pvt
"
$info = Invoke-sqlcmd -Query $SQL_Defaultpaths -ServerInstance $destination
$DefaultData = $info.ROWS
$DefaultLog = $info.LOG
#
# Process all user databases
#
$SQL_FullRecoveryDatabases = @"
SELECT name
FROM master.sys.databases
WHERE name NOT IN ('master', 'model', 'tempdb', 'msdb', 'distribution')
"@
$info = Invoke-sqlcmd -Query $SQL_FullRecoveryDatabases -ServerInstance $source
$info | ForEach-Object {
try {
$DatabaseName = $_.Name
Write-Output "Processing database $DatabaseName"
$BackupFile = $DatabaseName + "_" + $ts + ".bak"
$BackupPath = $BackupDirectory + "\" + $BackupFile
$RemoteBackupPath = $remoteSharedFolder + "\" + $BackupFile
$SQL_BackupDatabase = "BACKUP DATABASE $DatabaseName TO DISK='$BackupPath' WITH INIT, COPY_ONLY, COMPRESSION;"
#
# Backup database to local path
#
Invoke-Sqlcmd -Query $SQL_BackupDatabase -ServerInstance $source -QueryTimeout 65535
Write-Output "Database backed up to $BackupPath"
$BackupPath = $BackupPath
$BackupFile = [System.IO.Path]::GetFileName($BackupPath)
$SQL_RestoreDatabase = "
RESTORE DATABASE $DatabaseName
FROM DISK='$RemoteBackupPath'
WITH RECOVERY, REPLACE,
"
$SQL_RestoreFilelistOnly = "
RESTORE FILELISTONLY
FROM DISK='$RemoteBackupPath';
"
#
# Move the backup to the destination
#
$remotesourcefile = $BackupPath.Substring(1, 2)
$remotesourcefile = $BackupPath.Replace($remotesourcefile, $remotesourcefile.replace(":","$"))
$remotesourcefile = "\\" + $sourceServerUNC + "\" + $remotesourcefile
Write-Output "Moving $remotesourcefile to $sharedFolder"
Move-Item $remotesourcefile $sharedFolder -Force
#
# Restore the backup on the destination
#
$i = 0
Invoke-Sqlcmd -Query $SQL_RestoreFilelistOnly -ServerInstance $destination -QueryTimeout 65535 | ForEach-Object {
$currentRow = $_
$physicalName = [System.IO.Path]::GetFileName($CurrentRow.PhysicalName)
if($CurrentRow.Type -eq "D") {
$newName = $DefaultData + $physicalName
}
else {
$newName = $DefaultLog + $physicalName
}
if($i -gt 0) {$SQL_RestoreDatabase += ","}
$SQL_RestoreDatabase += " MOVE '$($CurrentRow.LogicalName)' TO '$NewName'"
$i += 1
}
Write-Output "invoking restore command: $SQL_RestoreDatabase"
Invoke-Sqlcmd -Query $SQL_RestoreDatabase -ServerInstance $destination -QueryTimeout 65535
Write-Output "Restored database from $RemoteBackupPath"
#
# Delete the backup file
#
Write-Output "Deleting $($sharedFolder + "\" + $BackupFile) "
Remove-Item $($sharedFolder + "\" + $BackupFile) -ErrorAction SilentlyContinue
}
catch {
Write-Error $_
}
}
It’s a quick’n’dirty script, I’m sure there might be something to fix here and there. Just drop a comment if you find something.
Do you need sysadmin rights to backup a database?
 Looks like a silly question, doesn’t it? – Well, you would be surprised to know it’s not.
Looks like a silly question, doesn’t it? – Well, you would be surprised to know it’s not.
Obviously, you don’t need to be a sysadmin to simply issue a BACKUP statement. If you look up the BACKUP statement on BOL you’ll see in the “Security” section that
BACKUP DATABASE and BACKUP LOG permissions default to members of the sysadmin fixed server role and the db_owner and db_backupoperator fixed database roles.
But there’s more to it than just permissions on the database itself: in order to complete successfully, the backup device must be accessible:
[…] SQL Server must be able to read and write to the device; the account under which the SQL Server service runs must have write permissions. […]
While this statement sound sensible or even obvious when talking about file system devices, with other types of device it’s less obvious what “permissions” means. With other types of device I mean tapes and Virtual Backup Devices. Since probably nobody uses tapes directly anymore, basically I’m referring to Virtual Backup Devices.
VDI (Virtual Backup device Interface) is the standard API intended for use by third-party backup software vendors to perform backup operations. Basically, it allows an application to act as a storage device.
The VDI specification is available here (you just need the vbackup.chm help file contained in the self-extracting archive).
If you download and browse the documentation, under the “Security” topic, you will find a worrying statement:
The server connection for SQL Server that is used to issue the BACKUP or RESTORE commands must be logged in with the sysadmin fixed server role.
Wait, … what???!?!??!! Sysadmin???????
Sad but true, sysadmin is the only way to let an application take backups using the VDI API. There is no individual permission you can grant: it’s sysadmin or nothing.
Since most third-party backup sofwares rely on the VDI API, this looks like a serious security flaw: every SQL Server instance around the world that uses third-party backup utilities has a special sysadmin login used by the backup tool, or, even worse, the tool runs under the sa login.
In my opinion, this is an unacceptable limitation and I would like to see a better implementation in a future version, so I filed a suggestion on Connect.
If you agree with me, feel free to upvote and comment it.
Mirrored Backups: a useful feature?
One of the features found in the Enterprise Edition of SQL Server is the ability to take mirrored backups. Basically, taking a mirrored backup means creating additional copies of the backup media (up to three) using a single BACKUP command, eliminating the need to perform the copies with copy or robocopy.
The idea behind is that you can backup to multiple locations and increase the protection level by having additional copies of the backup set. In case one of the copies gets lost or corrupted, you can use the mirrored copy to perform a restore.
BACKUP DATABASE [AdventureWorks2008R2] TO DISK = 'C:\backup\AdventureWorks2008R2.bak' MIRROR TO DISK = 'H:\backup\AdventureWorks2008R2.bak' WITH FORMAT; GO
Another possible scenario for a mirrored backup is deferred tape migration: you can backup to a local disk and mirror to a shared folder on a file server. That way you could have a local copy of the backup set and restore it in case of need and let the mirrored copy migrate to tape when the disk backup software processes the file server’s disks.

Mirrored backup sets can be combined with striped backups, given that all the mirror copies contain the same number of stripes:
BACKUP DATABASE [AdventureWorks2008R2] TO DISK = 'C:\backup\AdventureWorks2008R2_1.bak', DISK = 'C:\backup\AdventureWorks2008R2_2.bak', DISK = 'C:\backup\AdventureWorks2008R2_3.bak' MIRROR TO DISK = 'H:\AdventureWorks2008R2_1.bak', DISK = 'H:\AdventureWorks2008R2_2.bak', DISK = 'H:\AdventureWorks2008R2_3.bak' WITH FORMAT; GO
When restoring from a striped + mirrored backup set, you can mix the files from one media with the files from another media, as each mirrored copy is an exact copy of the main backup set.
RESTORE DATABASE [AW_Restore] FROM DISK = N'C:\backup\AdventureWorks2008R2_1.bak', -- main media DISK = N'H:\AdventureWorks2008R2_2.bak', -- mirror media DISK = N'H:\AdventureWorks2008R2_3.bak' -- mirror media WITH FILE = 1, MOVE N'AdventureWorks2008R2_Data' TO N'C:\DATA\AW_Restore.mdf', MOVE N'AdventureWorks2008R2_Log' TO N'C:\DATA\AW_Restore_1.ldf', MOVE N'FileStreamDocuments2008R2' TO N'C:\DATA\AW_Restore_2.Documents2008R2', NOUNLOAD, STATS = 10; GO
Looks like a handy feature! However, some limitations apply:
- If striped, the mirror must contain the same number of stripes.
Looks sensible: each mirror copy is an exact copy of the main backup set, which would be impossible with a different number of devices. - Must be used with FORMAT option.
No append supported: the destination device must be overwritten. - Destination media must be of the same type.
You cannot use disk and tape together. I can understand the reason for this restriction, but, actually, it makes this feature much less useful than it could be. - Fails the backup if ANY of the mirrored copies fails.
This is the main pain point: creating multiple copies of the same backup set can end up reducing the protection level, because the whole backup process fails when at least one of the destination media is unavailable or faulty.
Does this mean that the ability to take mirrored backups is a useless feature?
Well, it highly depends on your point of view and what matters to you most. I would prefer having at least one copy of the database backup available rather than no backup at all.
Keeping in mind that:
- the same exact result can be accomplished using copy, xcopy or robocopy
- non-local copies are much more likely to fail rather than local copies
- taking multiple local copies is quite pointless
- Enterprise Edition costs a lot of money
- There’s no GUI in SSMS backup dialog, nor in Maintenance Plans
…I think I could live without this feature. At least, this is not one of the countless reasons why I would prefer Enterprise over cheaper editions.
Backup all user databases with TDPSQL
Stanislav Kamaletdin (twitter) today asked on #sqlhelp how to backup all user databases with TDP for SQL Server:

My first thought was to use the “*” wildcard, but this actually means all databases, not just user databases.
I ended up adapting a small batch file I’ve been using for a long time to take backups of all user databases with full recovery model:
@ECHO OFF
SQLCMD -E -Q "SET NOCOUNT ON; SELECT name FROM sys.databases WHERE name NOT IN ('master','model','msdb','tempdb')" -h -1 -o tdpsql_input.txt
FOR /F %%A IN (tdpsql_input.txt) DO CALL :perform %%A
GOTO end_batch
:perform
tdpsqlc backup %1 full /configfile=tdpsql.cfg /tsmoptfile=dsm.opt /sqlserver=servername /logfile=tdpsqlc.log
:end_batch
Most of the “trick” is in the SQLCMD line:
- -Q “query” executes the query and returns. I added “SET NOCOUNT ON;” to eliminate the row count from the output.
- -h -1 suppresses the column headers
- -o tdpsql_input.txt redirects the output to a text file
FOR /F %%A IN (tdpsql_input.txt) DO CALL :perform %%A