Blog Archives
Tracking Table Usage and Identifying Unused Objects
One of the things I hate the most about “old” databases is the fact that unused tables are kept forever, because nobody knows whether they’re used or not. Sometimes it’s really hard to tell. Some databases are accessed by a huge number of applications, reports, ETL tools and God knows what else. In these cases, deciding whether you should drop a table or not is a tough call.
Search your codebase
The easiest way to know if a table is used, is to search the codebase for occurences of the table name. However, finding the table name in the code does not mean it is used: there are code branches that in turn are not used. Modern languages and development tools can help you identify unused methods and objects, but it’s not always feasible or 100% reliable (binary dependencies, scripts, dynamic code are, off top of my head, some exceptions).
On the other hand, not finding the table name in the code does not mean you can delete it with no issues. The table could be used by dynamic code and the name retrieved from a configuration file or a table in the database.
In other cases, the source code is not available at all.
Index usage: clues, not evidence
Another way to approach the problem is by measuring the effects of the code execution against the database, in other words, by looking at the information stored by SQL Server whenever a table is accessed.
The DMV sys.dm_db_index_usage_stats records information on all seeks, scans, lookups and updates against indexes and is a very good place to start the investigation. If something is writing to the table or reading from it, you will see the numbers go up and the dates moving forward.
Great, so we’re done and this post is over? Not exactly: there are some more facts to take into account.
First of all, the DMV gets cleared every time SQL Server is restarted, so the accuracy of the data returned is heavily dependant on how long the instance has been running. Moreover, some actions (rebuilding the index, to name one) reset the index usage stats and if you want to rely on sensible stats, your only option is to persist the data in some place regularly.
To achieve this goal, I coded this simple stored procedure that reads the stats from the DMV and stores it in a table, updating the read and write counts for each subsequent execution.
-- You have a TOOLS database, right?
-- If not, create one, you will thank me later
USE TOOLS;
GO
-- A place for everything, everything in its place
IF SCHEMA_ID('meta') IS NULL
EXEC('CREATE SCHEMA meta;')
GO
-- This table will hold index usage summarized at table level
CREATE TABLE meta.index_usage(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
)
-- This table will hold the last snapshot taken
-- It will be used to capture the snapshot and
-- merge it with the destination table
CREATE TABLE meta.index_usage_last_snapshot(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
)
GO
-- This procedure captures index usage stats
-- and merges the stats with the ones already captured
CREATE PROCEDURE meta.record_index_usage
AS
BEGIN
SET NOCOUNT ON;
IF OBJECT_ID('tempdb..#stats') IS NOT NULL
DROP TABLE #stats;
-- We will use the index stats multiple times, so parking
-- them in a temp table is convenient
CREATE TABLE #stats(
db_name sysname,
schema_name sysname,
object_name sysname,
read_count bigint,
last_read datetime,
write_count bigint,
last_write datetime,
PRIMARY KEY CLUSTERED (db_name, schema_name, object_name)
);
-- Reads index usage stats and aggregates stats at table level
-- Aggregated data is saved in the temporary table
WITH index_stats AS (
SELECT DB_NAME(database_id) AS db_name,
OBJECT_SCHEMA_NAME(object_id,database_id) AS schema_name,
OBJECT_NAME(object_id, database_id) AS object_name,
user_seeks + user_scans + user_lookups AS read_count,
user_updates AS write_count,
last_read = (
SELECT MAX(value)
FROM (
VALUES(last_user_seek),(last_user_scan),(last_user_lookup)
) AS v(value)
),
last_write = last_user_update
FROM sys.dm_db_index_usage_stats
WHERE DB_NAME(database_id) NOT IN ('master','model','tempdb','msdb')
)
INSERT INTO #stats
SELECT db_name,
schema_name,
object_name,
SUM(read_count) AS read_count,
MAX(last_read) AS last_read,
SUM(write_count) AS write_count,
MAX(last_write) AS last_write
FROM index_stats
GROUP BY db_name,
schema_name,
object_name;
DECLARE @last_date_in_snapshot datetime;
DECLARE @sqlserver_start_date datetime;
-- reads maximum read/write date from the data already saved in the last snapshot table
SELECT @last_date_in_snapshot = MAX(CASE WHEN last_read > last_write THEN last_read ELSE last_write END)
FROM meta.index_usage_last_snapshot;
-- reads SQL Server start time
SELECT @sqlserver_start_date = sqlserver_start_time FROM sys.dm_os_sys_info;
-- handle restarted server: last snapshot is before server start time
IF (@last_date_in_snapshot) < (@sqlserver_start_date)
TRUNCATE TABLE meta.index_usage_last_snapshot;
-- handle snapshot table empty
IF NOT EXISTS(SELECT * FROM meta.index_usage_last_snapshot)
INSERT INTO meta.index_usage_last_snapshot
SELECT * FROM #stats;
-- merges data in the target table with the new collected data
WITH offset_stats AS (
SELECT newstats.db_name,
newstats.schema_name,
newstats.object_name,
-- if new < old, the stats have been reset
newstats.read_count -
CASE
WHEN newstats.read_count < ISNULL(oldstats.read_count,0) THEN 0
ELSE ISNULL(oldstats.read_count,0)
END
AS read_count,
newstats.last_read,
-- if new < old, the stats have been reset
newstats.write_count -
CASE
WHEN newstats.write_count < ISNULL(oldstats.write_count,0) THEN 0
ELSE ISNULL(oldstats.write_count,0)
END
AS write_count,
newstats.last_write
FROM #stats AS newstats
LEFT JOIN meta.index_usage_last_snapshot AS oldstats
ON newstats.db_name = oldstats.db_name
AND newstats.schema_name = oldstats.schema_name
AND newstats.object_name = oldstats.object_name
)
MERGE INTO meta.index_usage AS dest
USING offset_stats AS src
ON src.db_name = dest.db_name
AND src.schema_name = dest.schema_name
AND src.object_name = dest.object_name
WHEN MATCHED THEN
UPDATE SET read_count += src.read_count,
last_read = src.last_read,
write_count += src.write_count,
last_write = src.last_write
WHEN NOT MATCHED BY TARGET THEN
INSERT VALUES (
src.db_name,
src.schema_name,
src.object_name,
src.read_count,
src.last_read,
src.write_count,
src.last_write
);
-- empty the last snapshot
TRUNCATE TABLE meta.index_usage_last_snapshot;
-- replace it with the new collected data
INSERT INTO meta.index_usage_last_snapshot
SELECT * FROM #stats;
END
GO
You can schedule the execution of the stored procedure every hour or so and you will see data flow in the meta.index_usage_last_snapshot table. Last read/write date will be updated and the read/write counts will be incremented by comparing saved counts with the captured ones: if I had 1000 reads in the previous snapshot and I capture 1200 reads, the total reads column must be incremented by 200.
So, if I don’t find my table in this list after monitoring for some days, is it safe to assume that it can be deleted? Probably yes. More on that later.
What these stats don’t tell you is what to do when you do find the table in the list. It would be reasonable to think that the table is used, but there are several reasons why it may have ended up being read or written and not all of them will be ascribable to an application.
For instance, if a table is merge replicated, the replication agents will access it and read counts will go up. What the index usage stats tell us is that something is using a table but it says nothing about the nature of that something. If you want to find out more, you need to set up some kind of monitoring that records additional information about where reads and writes come from.
Extended Events to the rescue
For this purpose, an audit is probably too verbose, because it will record an entry for each access to each table being audited. The audit file will grow very quickly if not limited to a few objects to investigate. Moreover, audits have to be set up for each table and kept running for a reasonable time before drawing conclusions.
Audits are based on Extended Events: is there another way to do the same thing Audits do using extended events directly? Of course there is, but it’s trickier than you would expect.
First of all, the Extended Events used by the audit feature are not available directly. You’ve been hearing several times that audits use Extended Events but nobody ever told you which events they are using: the reason is that those events are not usable in a custom Extended Events session (the SecAudit package is marked as “private”). As a consequence, if you want to audit table access, you will have to use some other kind of event.
In order to find out which Extended Events provide information at the object level, we can query the sys.dm_xe_object_columns DMV:
SELECT object_name, description FROM sys.dm_xe_object_columns WHERE name = 'object_id'
As you will see, the only event that could help in this case is the lock_acquired event. Whenever a table is accessed, a lock will be taken and capturing those locks is a quick and easy way to discover activity on the tables.
Here is the definition of a session to capture locking information:
CREATE EVENT SESSION [audit_table_usage] ON SERVER
ADD EVENT sqlserver.lock_acquired (
SET collect_database_name = (0)
,collect_resource_description = (1)
ACTION(sqlserver.client_app_name, sqlserver.is_system, sqlserver.server_principal_name)
WHERE (
[package0].[equal_boolean]([sqlserver].[is_system], (0)) -- user SPID
AND [package0].[equal_uint64]([resource_type], (5)) -- OBJECT
AND [package0].[not_equal_uint64]([database_id], (32767)) -- resourcedb
AND [package0].[greater_than_uint64]([database_id], (4)) -- user database
AND [package0].[greater_than_equal_int64]([object_id], (245575913)) -- user object
AND (
[mode] = (1) -- SCH-S
OR [mode] = (6) -- IS
OR [mode] = (8) -- IX
OR [mode] = (3) -- S
OR [mode] = (5) -- X
)
)
)
WITH (
MAX_MEMORY = 20480 KB
,EVENT_RETENTION_MODE = ALLOW_MULTIPLE_EVENT_LOSS
,MAX_DISPATCH_LATENCY = 30 SECONDS
,MAX_EVENT_SIZE = 0 KB
,MEMORY_PARTITION_MODE = NONE
,TRACK_CAUSALITY = OFF
,STARTUP_STATE = OFF
);
GO
If you start this session and monitor the data captured with the “Watch live data” window, you will soon notice that a huge number of events gets captured, which means that the output will also be huge and analyzing it can become a daunting task. Saving this data to a file target is not the way to go here: is there another way?
The main point here is that there is no need for the individual events, but the interesting information is the aggregated data from those events. Ideally, you would need to group by object_id and get the maximum read or write date. If possible, counting reads and writes by object_id would be great. At a first look, it seems like a good fit for the histogram target, however you will soon discover that the histogram target can “group” on a single column, which is not what you want. Object_ids are not unique and you can have the same object_id in different databases. Moreover, the histogram target can only count events and is not suitable for other types of aggregation, such as MAX.
Streaming the events with Powershell
Fortunately, when something is not available natively, you can code your own implementation. In this case, you can use the Extended Events streaming API to attach to the session and evaluate the events as soon as they show up in the stream.
In this example, I will show you how to capture the client application name along with the database and object id and group events on these 3 fields. If you are interested in additional fields (such as host name or login name), you will need to group by those fields as well.
In the same way, if you want to aggregate additional fields, you will have to implement your own logic. In this example, I am computing the MAX aggregate for the read and write events, without computing the COUNT. The reason is that it’s not easy to predict whether the count will be accurate or not, because different kind of locks will be taken in different situations (under snapshot isolation no shared locks are taken, so you have to rely on SCH-S locks; when no dirty pages are present SQL Server takes IS locks and not S locks…).
Before going to the Powershell code, you will need two tables to store the information:
USE TOOLS;
GO
CREATE TABLE meta.table_usage_xe(
db_name sysname,
schema_name sysname,
object_name sysname,
client_app_name nvarchar(128),
last_read datetime,
last_write datetime,
PRIMARY KEY(db_name, schema_name, object_name, client_app_name)
);
CREATE TABLE meta.table_usage_xe_last_snapshot(
database_id int,
object_id int,
client_app_name nvarchar(128),
last_read datetime,
last_write datetime,
PRIMARY KEY(database_id, object_id, client_app_name)
);
Now that you have a nice place to store the aggregated information, you can start this script to capture the events and persist them.
sl $Env:Temp
#For SQL Server 2014:
Add-Type -Path 'C:\Program Files\Microsoft SQL Server\120\Shared\Microsoft.SqlServer.XE.Core.dll'
Add-Type -Path 'C:\Program Files\Microsoft SQL Server\120\Shared\Microsoft.SqlServer.XEvent.Linq.dll'
#For SQL Server 2012:
#Add-Type -Path 'C:\Program Files\Microsoft SQL Server\110\Shared\Microsoft.SqlServer.XEvent.Linq.dll'
$connectionString = 'Data Source = YourServerNameGoesHere; Initial Catalog = master; Integrated Security = SSPI'
$SessionName = "audit_table_usage"
# loads all object ids for table objects and their database id
# table object_ids will be saved in order to rule out whether
# the locked object is a table or something else.
$commandText = "
DECLARE @results TABLE (
object_id int,
database_id int
);
DECLARE @sql nvarchar(max);
SET @sql = '
SELECT object_id, db_id()
FROM sys.tables t
WHERE is_ms_shipped = 0
';
DECLARE @statement nvarchar(max);
SET @statement = (
SELECT 'EXEC ' + QUOTENAME(name) + '.sys.sp_executesql @sql; '
FROM sys.databases d
WHERE name NOT IN ('master','model','msdb','tempdb')
FOR XML PATH(''), TYPE
).value('.','nvarchar(max)');
INSERT @results
EXEC sp_executesql @statement, N'@sql nvarchar(max)', @sql;
SELECT *
FROM @results
"
$objCache = @{}
$conn = New-Object -TypeName System.Data.SqlClient.SqlConnection -ArgumentList $connectionString
$cmd = New-Object -TypeName System.Data.SqlClient.SqlCommand
$cmd.CommandText = $commandText
$cmd.Connection = $conn
$conn.Open()
$conn.ChangeDatabase("master")
$rdr = $cmd.ExecuteReader()
# load table object_ids and store them in a hashtable
while ($rdr.Read()) {
$objId = $rdr.GetInt32(0)
$dbId = $rdr.GetInt32(1)
if(-not $objCache.ContainsKey($objId)){
$objCache.add($objId,@($dbId))
}
else {
$arr = $objCache.Get_Item($objId)
$arr += $dbId
$objCache.set_Item($objId, $arr)
}
}
$conn.Close()
# create a DataTable to hold lock information in memory
$queue = New-Object -TypeName System.Data.DataTable
$queue.TableName = $SessionName
[Void]$queue.Columns.Add("database_id",[Int32])
[Void]$queue.Columns.Add("object_id",[Int32])
[Void]$queue.Columns.Add("client_app_name",[String])
[Void]$queue.Columns.Add("last_read",[DateTime])
[Void]$queue.Columns.Add("last_write",[DateTime])
# create a DataView to perform searches in the DataTable
$dview = New-Object -TypeName System.Data.DataView
$dview.Table = $queue
$dview.Sort = "database_id, client_app_name, object_id"
$last_dump = [DateTime]::Now
# connect to the Extended Events session
[Microsoft.SqlServer.XEvent.Linq.QueryableXEventData] $events = New-Object -TypeName Microsoft.SqlServer.XEvent.Linq.QueryableXEventData `
-ArgumentList @($connectionString, $SessionName, [Microsoft.SqlServer.XEvent.Linq.EventStreamSourceOptions]::EventStream, [Microsoft.SqlServer.XEvent.Linq.EventStreamCacheOptions]::DoNotCache)
$events | % {
$currentEvent = $_
$database_id = $currentEvent.Fields["database_id"].Value
$client_app_name = $currentEvent.Actions["client_app_name"].Value
if($client_app_name -eq $null) { $client_app_name = [string]::Empty }
$object_id = $currentEvent.Fields["object_id"].Value
$mode = $currentEvent.Fields["mode"].Value
# search the object id in the object cache
# if found (and database id matches) ==> table
# otherwise ==> some other kind of object (not interesting)
if($objCache.ContainsKey($object_id) -and $objCache.Get_Item($object_id) -contains $database_id)
{
# search the DataTable by database_id, client app name and object_id
$found_rows = $dview.FindRows(@($database_id, $client_app_name, $object_id))
# if not found, add a row
if($found_rows.Count -eq 0){
$current_row = $queue.Rows.Add()
$current_row["database_id"] = $database_id
$current_row["client_app_name"] = $client_app_name
$current_row["object_id"] = $object_id
}
else {
$current_row = $found_rows[0]
}
if(($mode.Value -eq "IX") -or ($mode.Value -eq "X")) {
# Exclusive or Intent-Exclusive lock: count this as a write
$current_row["last_write"] = [DateTime]::Now
}
else {
# Shared or Intent-Shared lock: count this as a read
# SCH-S locks counted here as well (snapshot isolation ==> no shared locks)
$current_row["last_read"] = [DateTime]::Now
}
}
$ts = New-TimeSpan -Start $last_dump -End (get-date)
# Dump to database every 5 minutes
if($ts.TotalMinutes -gt 5) {
$last_dump = [DateTime]::Now
# BCP data to the staging table TOOLS.meta.table_usage_xe_last_snapshot
$bcp = New-Object -TypeName System.Data.SqlClient.SqlBulkCopy -ArgumentList @($connectionString)
$bcp.DestinationTableName = "TOOLS.meta.table_usage_xe_last_snapshot"
$bcp.Batchsize = 1000
$bcp.BulkCopyTimeout = 0
$bcp.WriteToServer($queue)
# Merge data with the destination table TOOLS.meta.table_usage_xe
$statement = "
BEGIN TRANSACTION
BEGIN TRY
MERGE INTO meta.table_usage_xe AS dest
USING (
SELECT db_name(database_id) AS db_name,
object_schema_name(object_id, database_id) AS schema_name,
object_name(object_id, database_id) AS object_name,
client_app_name,
last_read,
last_write
FROM meta.table_usage_xe_last_snapshot
) AS src
ON src.db_name = dest.db_name
AND src.schema_name = dest.schema_name
AND src.object_name = dest.object_name
AND src.client_app_name = dest.client_app_name
WHEN MATCHED THEN
UPDATE SET last_read = src.last_read,
last_write = src.last_write
WHEN NOT MATCHED THEN
INSERT (db_name, schema_name, object_name, client_app_name, last_read, last_write)
VALUES (db_name, schema_name, object_name, client_app_name, last_read, last_write);
TRUNCATE TABLE meta.table_usage_xe_last_snapshot;
COMMIT;
END TRY
BEGIN CATCH
ROLLBACK;
THROW;
END CATCH
"
$conn = New-Object -TypeName System.Data.SqlClient.SqlConnection -ArgumentList $connectionString
$cmd = New-Object -TypeName System.Data.SqlClient.SqlCommand
$cmd.CommandText = $statement
$cmd.Connection = $conn
$conn.Open()
$conn.ChangeDatabase("TOOLS")
[Void]$cmd.ExecuteNonQuery()
$conn.Close()
$queue.Rows.Clear()
}
}
WARNING: Be careful running this script against a production server: I tried it with a reasonaly busy server and the CPU/memory load of powershell.exe is non-negligible. On the other hand, the load imposed by the session per se is very low: make sure you run this script from a different machine and not on the database server.
What to do with unused objects
After monitoring for a reasonable amount of time, you will start to notice that some objects are never used and you will probably want to delete them. Don’t!
In my experience, as soon as you delete an object, something that uses it (and you didn’t capture) pops up and fails. In those cases, you want to restore the objects very quickly. I usually move everything to a “trash” schema and have it sitting there for some time (six months/one year) and eventually empty the trash. If somebody asks for a restore, it’s just as simple as an ALTER SCHEMA … TRANSFER statement.
Bottom line
Cleaning up clutter from a database is not simple: hopefully the techniques in this post will help you in the task. Everything would be much simpler if the Extended Events histogram target was more flexible, but please keep in mind that it’s not about the tools: these techniques can help you identify unused objects when no other information is available, but nothing is a good substitute for a correct use of the database. When new tables are added to a database, keep track of the request and take notes about who uses the tables for which purpose: everything will be much easier in the long run.
Speaking at SQLSaturday Pordenone
Next week, on Saturday 28, make sure you don’t miss SQLSaturday Pordenone!

Pordenone is the place where the Italian adventure with SQLSaturday started, more than two years ago. It was the beginning of a journey that brought many SQLSaturdays to Italy, with our most successful one in Parma last November.
Now we’re back in Pordenone to top that result!
We have a fantastic schedule for this event, with a great speaker lineup and great topics for the sessions. Everything is set in the right direction to be a great day of free learning and fun.
I will have two sessions this time:
SQL Server Security in an Insecure World
In this session I will talk about security, with a general introduction to the topic and then I’ll go straight to demonstrate some of the vulnerabilities that attackers could use to take over your server. Yes, I’ll be demonstrating SQL-Injection attacks: SQL-I is still a top security issue, even if we’re in 2015. Everyone must be aware of the risks and take action immediately.
I will also describe the security features available in SQL Server to lock down the server as much as possible, but the key concept I will try to drive is that security is a process, not a feature.
If you want to find out more, join me at 12:00 PM in room S7.
Extending the Data Collector to Monitor SQL Server effortlessly
In this session I will try to promote one of the least used features in SQL Server: the Data Collector. It doesn’t have all the bells and whistles of the expensive monitoring suites, but it does the job pretty well. Things start to be painfully difficult when you try to extend it with additional collection sets, but the good news is that there’s an open-source project that provides a GUI to manage and customize the collection sets. The project is called ExtendedTSQLCollector and it does much more than just adding a GUI to the Data Collector: it also provides two additional collector types to collect data from LOB columns (in case you’re wondering, no – the vanilla Data Collector doesn’t support LOB columns) and Extended Events sessions.
I will also demonstrate a convenient way to centralize and extend the Data Collector reports to create a reporting and alerting solution for free.
Sounds interesting? Join me at 4:30 PM in room S7.
So, what are you waiting for? Register now and join us in Pordenone!
Blame it on Connect
![]() Some weeks ago I blogged about the discouraging signals coming from Connect and my post started a discussion that didn’t go very far. Instead it died quite soon: somebody commented the post and ranted about his Connect experience. I’m blogging again about Connect, but I don’t want to start a personal war against Microsoft: today I want to look at what happened from a new perspective.
Some weeks ago I blogged about the discouraging signals coming from Connect and my post started a discussion that didn’t go very far. Instead it died quite soon: somebody commented the post and ranted about his Connect experience. I’m blogging again about Connect, but I don’t want to start a personal war against Microsoft: today I want to look at what happened from a new perspective.
What I find disappointing is a different aspect of the reactions from the SQL Server community, which made me think that maybe it’s not only Connect’s fault.
My post was in the headlines of SQL Server Central and was also included in the weekly links that Brent Ozar sends out with the Brent Ozar Unlimited newsletter, so it got a lot of views that day. Looking at my wordpress stats, I see that thousands of people read my post (to be fair, I can only say that they opened the page, I cannot tell whether they read the post or not) and some hundreds of people clicked the link to the original Connect item that started my rant.
Nobody upvoted the item. Yup, nobody.
Ok, very few people love the Data Collector and I rarely see it used in the wild, so, yes: I can understand how nobody cares about a bug in it. But, hey, it’s not my only Connect item that got no love from the community. Here’s another one, involving data corruption when using linked servers. See? Only 9 upvotes.
Here’s another one yet, that involves the setup program. No upvotes except mine.
What’s the point I want to drive? The voting system and the comments are the only way we have to improve the content on Connect. If we disregard the tools we have in our hands, there’s no use in complaining about the feedback system at all.
We need more community engagement
Filing our own items on Connect is not enough: we have to get involved in the platform to make our voice heard in more ways. When we find an item that we’d like to get fixed, we should definitely upvote it. At the same time, when we find items that are poorly described or are related to an issue that can be solved without bothering the support team, we should interact with the OP and ask for clarification or provide an alternative answer. When appropriate, we should also downvote poor questions.
Some popular Q&A sites like StackOverflow have built successful models based on this paradigm, like it or not. Moreover, the “points” system has proved successful at driving user engagement, which is something totally missing from Connect: you file your complaint and never come back.
Some online communities have moderators, who can play a fundamental role in the community. They can flag inappropriate items, edit and format questions and comments. The can also close questions or put them on hold. If part of the problem with Connect is the signal/noise ratio, more power to moderators is a possible answer.
Can PASS help?
In this post, Kevin Kline says that one of the ways that PASS should improve itself could be playing a better role in advocacy, telling Microsoft what are the features we really would like to see in SQL Server vNext and what are the bugs we really need to get fixed in the product. The idea is that Microsoft would (or at least should) listen more attentively to a whole community of users rather than to single individuals.
It’s a great idea and I think that PASS should really go for it. Unfortunately, something like that will never substitute Connect, because it’s a platform to collect feedback for all Microsoft products and not only for SQL Server. Moreover, how PASS is planning to gather the user feedback is still unclear: would it be using a voting system like Connect’s? How would that be different from Connect itself then?
Speed matters
Another thing that I think drives people away from Connect is its dreadful slowness. Connect is slow and nobody uses slow sites. It seems to be getting better lately, but we’re still not there. StackOverflow is probably using a fraction of Microsoft’s hardware and money to run all the StackExchange network at the speed of light. Part of its success is the responsiveness and Connect has a long way to go to catch up.
Bottom line
Connect has its issues, we all know it, but it’s not all Microsoft’s fault. The individual users can do something to improve the quality of the feedback and they definitely should. Everybody can start now! More votes means more attention, less votes means less love. Simple and straightforward.
On the other hand, the communities can contribute too. How they can contribute is not clear yet, but some communities (like PASS) have lots of people that volunteer and make their voice heard. It would really be a shame if that voice got lost.
Microsoft, please do your part. Users and communities want to contribute: help yourself by helping them and you won’t regret it. Responsiveness is the keyword here: we need a more responsive site and more responsive support engineers.
Who’s up to the challenge?
Installing multiple default instances on a single server
As you probably know, SQL Server allows only one default instance per server. The reason is not actually something special to SQL Server, but it has to do with the way TCP/IP endpoints work.
In fact, a SQL Server default instance is nothing special compared to a named instance: it has a specific instance id (MSSQLSERVER) and listens on a well-known TCP port (1433), but it has no other intrinsic property or feature that makes it different from any other instance.
Let’s look closely to these properties: the instance id is specific to a SQL Server instance and it has to be unique. In this regard, MSSQLSERVER makes no exception. Similarly, a TCP endpoint must be unique and there can be only one socket listening on a specific endpoint.
Nevertheless, I will show you a way to have multiple “default” instances installed on the same server, even if it might look impossible at a first look.
Install two instances of SQL Server
First of all, you need to have two (or more) instances installed on your server. In this example I will use the server “FANGIO” and I will install two named instances: INST01 and INST02.
Here’s what my Configuration Manager looks like once the two instances are ready:

In this case I used two named instances, but it would have worked even if I used a default instance and a named instance. Remember? Default instances are nothing special.
Provision IP addresses
Each SQL Server instance must listen on a different TCP endpoint, but this does not mean that each instance has to listen on a different port: a TCP endpoint is made of an IP address and a port. This means that two instances can listen on the same port, as long as the IP addresses are different.
In this case, you just need to add a new IP address to the server, one for each SQL Server instance that you want to listen on port 1433.

Configure network protocols
Now that you have multiple IP addresses, you just have to tell SQL Server to listen on that specific address, port 1433.
Open the Configuration Manager and enable TCP/IP:

Now open the properties applet and disable “Listen All”:

In the IP Addresses tab, configure the IP address and the port:

In this case I enabled the address 10.0.1.101 for INST01 and I disabled all the remaining addresses. For INST02 I enabled 10.0.1.102.
Configure DNS
Now the server has two IP addresses and they both resolve to its network name (FANGIO). In order to let clients connect to the appropriate SQL Server instance, you need to create two separate “A” records in DNS to resolve to each IP address.
In this case I don’t have a DNS server (it’s my home lab) so I will use the hosts file:

Final Setup
Now the example setup looks like this:
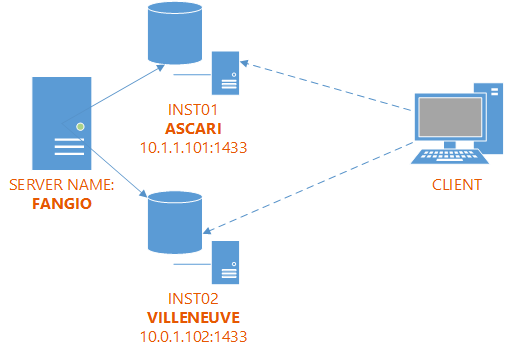
When a client connects to the default instance on ASCARI, it is connecting to FANGIO\INST01 instead. Similarly, the default instance on VILLENEUVE corresponds to FANGIO\INST02.

Why would I want to do this?
If you had only default instances in your servers, moving databases around for maintenances, upgrades or consolidations would be just a matter of adding a CNAME to your DNS.
With named instances, the only way to redirect connections to a different server is by using a SQLClient alias. Unfortunately, aliases are client-side settings and have to be deployed to each and every client in order to work. Group policies can deploy aliases to multiple machines at once, but policies are not evaluated immediately, while a DNS entry can propagate very quickly.
Another reason to use this setup is the ability to bypass the SQLBrowser: when a named instance is specified, the client has to contact the SQLBrowser service on port 1434 with a small UDP datagram and receive back the list of instances, along with the port they’re listening on. When the default instance is specified, there is no need to contact the SQLBrowser, because we already know the port it is listening on (it’s 1433, unless it has been changed).
Sometimes the firewall settings for SQLBrowser are tricky to set up, especially with clusters. Another thing I recently discovered is that SQLBrower allows attackers to create huge DDOS attacks using a 440x amplification factor.
Security concerns
Some setup guides recommend that you change the port SQL Server listens on to something different from 1433, which is a well-known port, more likely to be discovered by attackers. I think that an attacker skilled enough to penetrate your server needs much more resistance than just “hiding” your instance to a non-default port. A quick port scan would immediately reveal any SQL Server instance listening on any port, so this is really a moot point in my opinion.
Bottom line
SQL Server allows only one default instance to be installed on a machine, but with a few simple steps every instance can be made a “default” instance. The main advantage of such a setup is the ability to redirect client connections to a database instance with a simple change in the DNS configuration.
I’m an MVP: now what?
 Today when I checked my mailbox I found an amazing surprise: I joined the ranks of the Most Valuable Professionals for SQL Server!
Today when I checked my mailbox I found an amazing surprise: I joined the ranks of the Most Valuable Professionals for SQL Server!
I am honoured to join a community of people that I highly respect and have always been my inspiration. The MVPs I had the pleasure to meet are a model to strive for: exceptional technical experts and great community leaders that devote their own time to spread their knowledge. I have never considered myself nearly as good as those exceptional people and receiving this award means that now I have to live up to the overwhelming expectations that it sets.
So, now what?
This award maybe means that I’m on the right track. I will continue to help the community with my contribution, hoping that somebody find it useful in the journey with SQL Server. I will continue to spread whatever I know about SQL Server and all the technologies around it with my blog posts, my articles and my forum answers. I will continue to speak at conferences, SQL Saturdays and technology events around me.
The award opens new possibilities and new ways to contribute and I won’t miss the opportunity to do more!
I am really grateful to those who made it happen, in particular the exceptional people at sqlservercentral.com, where my journey with the SQL Server community began many years ago.
A huge thank you goes also to the Italian #sqlfamily that introduced me to speaking at SQL Server events.
And now, let’s rock this 2015!
Another good reason to avoid AUTO_CLOSE
Does anybody need another good reason to avoid setting AUTO_CLOSE on a database? Looks like I found one.
Some days ago, all of a sudden, a database started to throw errors along the lines of “The log for database MyDatabase is not available”. The instance was an old 2008 R2 Express (don’t get me started on why an Express Edition is in production…) with some small databases.
The log was definitely there and the database looked online. Actually, I was able to query the tables, but every attempt to update the contents ended up with the “log unavailable” error.
Then I opened the ERRORLOG and found something really interesting: lots and lots of entries similar to “Starting up database MyDatabase” over and over… Does it ring a bell?
Yes, it’s AUTO_CLOSE
Looks like SQL Server closed the database and failed to open it completely, hence the “log unavailable” errors.
What should be done now to bring the database back to normal behaviour? Simply bring the database offline and then back online:
ALTER DATABASE MyDatabase SET OFFLINE; ALTER DATABASE MyDatabase SET ONLINE;
And while we’re at it, let’s disable AUTO_CLOSE:
ALTER DATABASE MyDatabase SET AUTO_CLOSE OFF;
How can such a situation be prevented? There are many ways to accomplish this, ranging from PBM (Policy Based Management) to scheduled T-SQL health checks (see sp_blitz for instance).
See? Best practices are not for losers!
Installing SQL Server 2014 Language Reference Help from disk
Some weeks ago I had to wipe my machine and reinstall everything from scratch, SQL Server included.
For some reason that I still don’t understand, SQL Server Management Studio installed fine, but I couldn’t install Books Online from the online help repository. Unfortunately, installing from offline is not an option with SQL Server 2014, because the installation media doesn’t include the Language Reference documentation.
The issue is well known: Aaron Bertrand blogged about it back in april when SQL Server 2014 came out and he updated his post in august when the documentation was finally completely published. He also blogged about it at SQLSentry.
However, I couldn’t get that method to work: the Help Library Manager kept firing errors as soon as I clicked the “Install from Online” link. The error message was “An exception has occurred. See the event log for details.”
Needless to say that the event log had no interesting information to add.
If you are experiencing the same issue, here is a method to install the language reference from disk without downloading the help content from the Help Library Manager:
1 . Open a web browser and point it to the following url: http://services.mtps.microsoft.com/ServiceAPI/products/dd433097/dn632688/books/dn754848/en-us
2. Download the individual .cab files listed in that page to a location in your disk (e.g. c:\temp\langref\)
3. Create a text file name HelpContentSetup.msha in the same folder as the .cab files and paste the following html:
<html xmlns="http://www.w3.org/1999/xhtml">
<head />
<body class="vendor-book">
<div class="details">
<span class="vendor">Microsoft</span>
<span class="locale">en-us</span>
<span class="product">SQL Server 2014</span>
<span class="name">Microsoft SQL Server Language Reference</span>
</div>
<div class="package-list">
<div class="package">
<span class="name">SQL_Server_2014_Books_Online_B4164_SQL_120_en-us_1</span>
<span class="deployed">False</span>
<a class="current-link" href="sql_server_2014_books_online_b4164_sql_120_en-us_1(0b10b277-ad40-ef9d-0d66-22173fb3e568).cab">sql_server_2014_books_online_b4164_sql_120_en-us_1(0b10b277-ad40-ef9d-0d66-22173fb3e568).cab</a>
</div>
<div class="package">
<span class="name">SQL_Server_2014_Microsoft_SQL_Server_Language_Reference_B4246_SQL_120_en-us_1</span>
<span class="deployed">False</span>
<a class="current-link" href="sql_server_2014_microsoft_sql_server_language_reference_b4246_sql_120_en-us_1(5c1ad741-d0e3-a4a8-d9c0-057e2ddfa6e1).cab">sql_server_2014_microsoft_sql_server_language_reference_b4246_sql_120_en-us_1(5c1ad741-d0e3-a4a8-d9c0-057e2ddfa6e1).cab</a>
</div>
<div class="package">
<span class="name">SQL_Server_2014_Microsoft_SQL_Server_Language_Reference_B4246_SQL_120_en-us_2</span>
<span class="deployed">False</span>
<a class="current-link" href="sql_server_2014_microsoft_sql_server_language_reference_b4246_sql_120_en-us_2(24815f90-9e36-db87-887b-cf20727e5e73).cab">sql_server_2014_microsoft_sql_server_language_reference_b4246_sql_120_en-us_2(24815f90-9e36-db87-887b-cf20727e5e73).cab</a>
</div>
</div>
</body>
</html>
4 . Open the Help Library Manager and select “Install content from disk”
5. Browse to the .msha you just created and click Next

6. The SQL Server 2014 node will appear. Click the Add link
7. Click the Update button and let the installation start

8. Installation will start and process the cab files

9. Installation finished!
9. To check whether everything is fine, click on the “remove content” link and you should see the documentation.

Done! It was easy after all, wasn’t it?
Database Free Space Monitoring – The right way
Lately I spent some time evaluating some monitoring tools for SQL Server and one thing that struck me very negatively is how none of them (to date) has been reporting database free space correctly.
I was actively evaluating one of those tools when one of my production databases ran out of space without any sort of warning.
I was so upset that I decided to code my own monitoring script.
Some things to take into account:
- Hard set limits for file growth have to be considered: a drive with lots of space is useless if the database file cannot grow and take it.
- If fixed growth is used, there must be enough space in the drive to accomodate the growth amount you set.
- If percent growth is used, you have to calculate recursively how much your database file will grow before taking all the space in the drive
- Some scripts found in blogs and books don’t account for mount points. Use
sys.dm_os_volume_statsto include mount points in your calculation (unless you’re running SQL Server versions prior to 2012). - Database free space alone is not enough. NTFS performance start degrading when the drive free space drops below 20%. Make sure you’re monitoring that as well.
- 20% of a huge database can be lots of space. You can change that threshold to whatever you find appropriate (for instance, less than 20% AND less than 20 GB)
That said, here is my script, I hope you find it useful.
-- create a temporary table to hold data from sys.master_files
IF OBJECT_ID('tempdb..#masterfiles') IS NOT NULL
DROP TABLE #masterfiles;
CREATE TABLE #masterfiles (
database_id int,
type_desc varchar(10),
name sysname,
physical_name varchar(255),
size_mb int,
max_size_mb int,
growth int,
is_percent_growth bit,
data_space_id int,
data_space_name nvarchar(128) NULL,
drive nvarchar(512),
mbfree int
);
-- extract file information from sys.master_files
-- and correlate each file to its logical volume
INSERT INTO #masterfiles
SELECT
mf.database_id
,type_desc
,name
,physical_name
,size_mb = size / 128
,max_size_mb =
CASE
WHEN max_size = 268435456 AND type_desc = 'LOG' THEN -1
ELSE
CASE
WHEN max_size = -1 THEN -1
ELSE max_size / 128
END
END
,mf.growth
,mf.is_percent_growth
,mf.data_space_id
,NULL
,d.volume_mount_point
,d.available_bytes / 1024 / 1024
FROM sys.master_files AS mf
CROSS APPLY sys.dm_os_volume_stats(database_id, file_id) AS d;
-- add an "emptyspace" column to hold empty space for each file
ALTER TABLE #masterfiles ADD emptyspace_mb int NULL;
-- iterate through all databases to calculate empty space for its files
DECLARE @name sysname;
DECLARE c CURSOR FORWARD_ONLY READ_ONLY STATIC LOCAL
FOR
SELECT name
FROM sys.databases
WHERE state_desc = 'ONLINE'
OPEN c
FETCH NEXT FROM c INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @sql nvarchar(max)
DECLARE @statement nvarchar(max)
SET @sql = '
UPDATE mf
SET emptyspace_mb = size_mb - FILEPROPERTY(name,''SpaceUsed'') / 128,
data_space_name =
ISNULL(
(SELECT name FROM sys.data_spaces WHERE data_space_id = mf.data_space_id),
''LOG''
)
FROM #masterfiles AS mf
WHERE database_id = DB_ID();
'
SET @statement = 'EXEC ' + QUOTENAME(@name) + '.sys.sp_executesql @sql'
EXEC sp_executesql @statement, N'@sql nvarchar(max)', @sql
FETCH NEXT FROM c INTO @name
END
CLOSE c
DEALLOCATE c
-- create a scalar function to simulate the growth of the database in the drive's available space
IF OBJECT_ID('tempdb..calculateAvailableSpace') IS NOT NULL
EXEC tempdb.sys.sp_executesql N'DROP FUNCTION calculateAvailableSpace'
EXEC tempdb.sys.sp_executesql N'
CREATE FUNCTION calculateAvailableSpace(
@diskFreeSpaceMB float,
@currentSizeMB float,
@growth float,
@is_percent_growth bit
)
RETURNS int
AS
BEGIN
IF @currentSizeMB = 0
SET @currentSizeMB = 1
DECLARE @returnValue int = 0
IF @is_percent_growth = 0
BEGIN
SET @returnValue = (@growth /128) * CAST((@diskFreeSpaceMB / (ISNULL(NULLIF(@growth,0),1) / 128)) AS int)
END
ELSE
BEGIN
DECLARE @prevsize AS float = 0
DECLARE @calcsize AS float = @currentSizeMB
WHILE @calcsize < @diskFreeSpaceMB
BEGIN
SET @prevsize = @calcsize
SET @calcsize = @calcsize + @calcsize * @growth / 100.0
END
SET @returnValue = @prevsize - @currentSizeMB
IF @returnValue < 0
SET @returnValue = 0
END
RETURN @returnValue
END
'
-- report database filegroups with less than 20% available space
;WITH masterfiles AS (
SELECT *
,available_space =
CASE mf.max_size_mb
WHEN -1 THEN tempdb.dbo.calculateAvailableSpace(mbfree, size_mb, growth, is_percent_growth)
ELSE max_size_mb - size_mb
END
+ emptyspace_mb
FROM #masterfiles AS mf
),
spaces AS (
SELECT
DB_NAME(database_id) AS database_name
,data_space_name
,type_desc
,SUM(size_mb) AS size_mb
,SUM(available_space) AS available_space_mb
,SUM(available_space) * 100 /
CASE SUM(size_mb)
WHEN 0 THEN 1
ELSE SUM(size_mb)
END AS available_space_percent
FROM masterfiles
GROUP BY DB_NAME(database_id)
,data_space_name
,type_desc
)
SELECT *
FROM spaces
WHERE available_space_percent < 20
ORDER BY available_space_percent ASC
IF OBJECT_ID('tempdb..#masterfiles') IS NOT NULL
DROP TABLE #masterfiles;
IF OBJECT_ID('tempdb..calculateAvailableSpace') IS NOT NULL
EXEC tempdb.sys.sp_executesql N'DROP FUNCTION calculateAvailableSpace'
I am sure that there are smarter scripts around that calculate it correctly and I am also sure that there are other ways to obtain the same results (PowerShell, to name one). The important thing is that your script takes every important aspect into account and warns you immediately when the database space drops below your threshold, not when the available space is over.
Last time it happened to me it was a late saturday night and, while I really love my job, I can come up with many better ways to spend my saturday night.
I'm pretty sure you do as well.
Announcing ExtendedTSQLCollector
I haven’t been blogging much lately, actually I haven’t been blogging at all in the last 4 months. The reason behind is I have been putting all my efforts in a new project I started recently, which absorbed all my attention and spare time.
I am proud to announce that my project is now live and available to everyone for download.
 The project name is ExtendedTSQLCollector and you can find it at http://extendedtsqlcollector.codeplex.com. As you may have already guessed, it’s a bridge between two technologies that were not meant to work together, that could instead bring great advantages when combined: Extended Events and Data Collector.
The project name is ExtendedTSQLCollector and you can find it at http://extendedtsqlcollector.codeplex.com. As you may have already guessed, it’s a bridge between two technologies that were not meant to work together, that could instead bring great advantages when combined: Extended Events and Data Collector.
ExtendedTSQLCollector is a set of two Collector Types built to overcome some of the limitations found in the built-in collector types and extend their functionality to include the ability to collect data from XE sessions.
The first Collector Type is the “Extended T-SQL Query” collector type, which was my initial goal when I started the project. If you have had the chance to play with the built-in “Generic T-SQL Query” collector type, you may have noticed that not all datatypes are supported. For instance, it’s impossible to collect data from XML or varchar(max) columns. This is due to the intermediate format used by this collector type: the SSIS raw files.
The “Extended T-SQL Query” collector type uses a different intermediate format, which allows collecting data of any data type. This is particularly useful, because SQL Server exposes lots of information in XML format (just think of the execution plans!) and you no longer need to code custom SSIS packages to collect that data.
The second Collector Type is the “Extended XE Reader” collector type, which takes advantage of the Extended Events streaming APIs to collect data from an Extended Events session, without the need to specify additional targets such as .xel files or ring buffers. This means no file system bloat due to .xel rollover files and no memory consumption for additional ring buffers: all the events are read directly from the session and processed in near real-time.
In addition to the filter predicates defined in the XE session, you can add more filter predicates on the data to collect and upload to the MDW and decide which columns (fields and actions) to collect. The collector will take care of creating the target table in your MDW database and upload all the data that satisfies the filter predicates.
The near real-time behavior of this collector type allowed me to include an additional feature to the mix: the ability to fire alerts in response to Extended Events. The current release (1.5) allows firing email alerts when the events are captured, with additional filter predicates and the ability to include event fields and actions in the email body. You can find more information on XE alerts in the documentation.
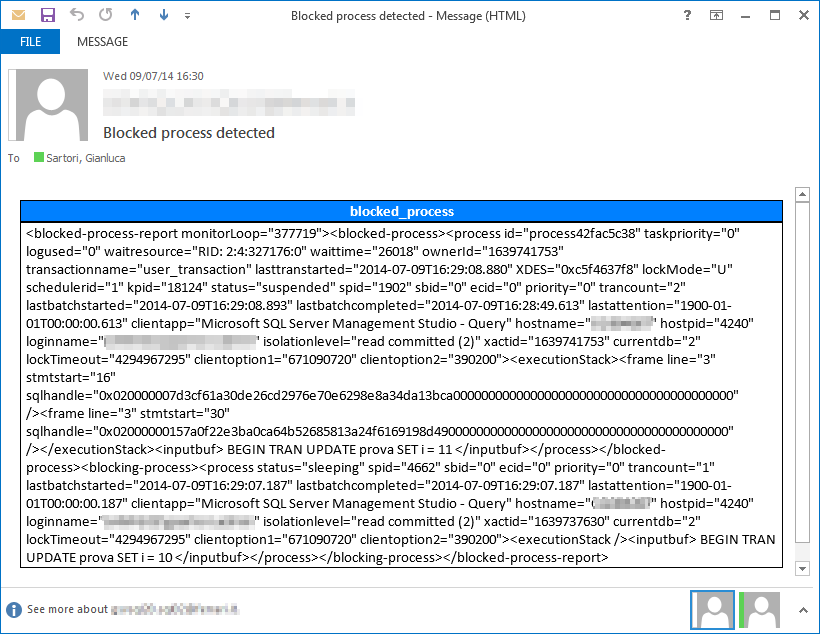
Here is an example of the email alerts generated by the XEReader collector type for the blocked_process event:
Another part of the project is the CollectionSet Manager, a GUI to install the collector types to the target servers and configure collection sets and collection items. I think that one of the reasons why the Data Collector is very underutilized by DBAs is the lack of a Graphical UI. Besides the features specific to the ExtendedTSQLCollector, such as installing the collector type, this small utility aims at providing the features missing in the SSMS Data Collector UI. This part of the project is still at an early stage, but I am planning to release it in the next few months.
My journey through the ins and outs of the Data Collector allowed me to understand deeply how it works and how to set it up and troubleshoot it. Now I am planning to start a blog series on this topic, from the basics to the advanced features. Stay tuned 🙂
I don’t want to go into deep details on the setup and configuration of this small project: I just wanted to ignite your curiosity and make you rush to codeplex to download your copy of ExtendedTSQLCollector.
What are you waiting for?
Verdasys Digital Guardian and SQL Server
I’m writing this post as a reminder for myself and possibly to help out the poor souls that may suffer the same fate as me.
There’s a software out there called “Digital Guardian” which is a data loss protection tool. Your computer may be running this software without you knowing: your system administrators may have installed it in order to prevent users from performing operations that don’t comply to corporate policies and may lead to data loss incidents.
For instance, Digital Guardian can prevent users from writing to USB pendrives and walk out of the office with a copy of the data in their pocket. Actually, this is just one of the policies than can be enforced by Digital Guardian: it’s a complete data protection framework that offers many powerful features.
The bad news is Digital Guardian relies on an agent daemon that runs very deep in the operating system and modifies the OS behaviour based on the policies defined by the system administrators. Most of the time, the user is notified of the tool’s intervention with explicit messages, stating that the operation is not permitted by corporate policies.
Sometimes (here comes the painful part) things randomly fail without any meaningful indication that Digital Guardian is responsible of the failure. Instead of getting sensible policy violation messages, you may get generic error messages that won’t be anywhere easy to troubleshoot. Sometimes, errors are not even due to policy violations, but are caused by the modifications in the OS behaviour introduced by Digital Guardian itself.
For instance, when installing SQL Server, you may be presented this error message:

Is the error message “No more data is available” anywhere helpful? Not really.
I spent countless hours trying to understand what went wrong and I finally understood the cause of the failure when a coworker pointed out that Digital Guardian was running on that particular server.
What happened here?
Digital Guardian clumsily tries to hide itself. If you look for it in the installed programs applet in Control Panel you won’t find it. It also tries to hide itself in the registry, so when you enumerate the registry key “HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall\Digital Guardian Agent” you will get an error.
In one of the early stages, SQL Server’s setup verifies what software is installed in the machine and when it encounters Digital Guardian’s registry key, it fails miserably.
The only way to get past the error is to disable Digital Guardian.
Are you comfortable with running SQL Server on a machine with such a tool installed?
OK, you managed to install SQL Server by disabling Digital Guardian: now what?
- What if SQL Server crashes?
- What if everything turns horribly slow?
- What if you get data corruption?
- What if…?
Tools that interact with the OS at such low level scare the hell out of me. Anything that you install and run on a machine with such a tool becomes completely unreliable in my opinion. SQL Server was not intended to run against a modified OS and it was not tested to run like that.
SQL Server has its own security tools. They may not be perfect, but it’s how the product was intended to work and, frankly, they’re largely sufficient for 99% of the use cases. Probably, enabling TDE is better than preventing everyone from writing to USB drives.
If you think SQL Server security features are not enough for you, go on and activate one of those pesky tools. But let me ask: are you sure that you fall in that 1% ?
