Category Archives: SQL Server
Benchmarking with WorkloadTools
If you ever tried to capture a benchmark on your SQL Server, you probably know that it is a complex operation. Not an impossible task, but definitely something that needs to be planned, timed and studied very thoroughly.
The main idea is that you capture a workload from production, you extract some performance information, then you replay the same workload to one or more environments that you want to put to test, while capturing the same performance information. At the end of the process, you can compare performance under different conditions, identify regressions, avoid unwanted situations and rate your tuning efforts.
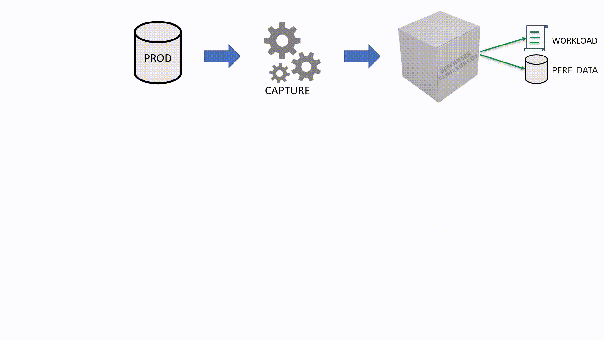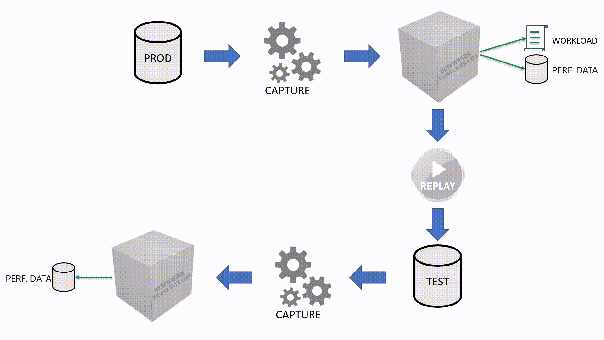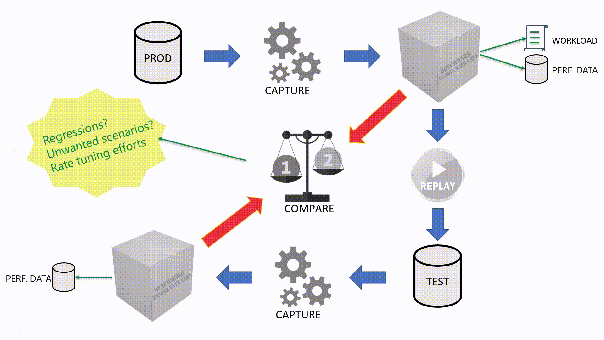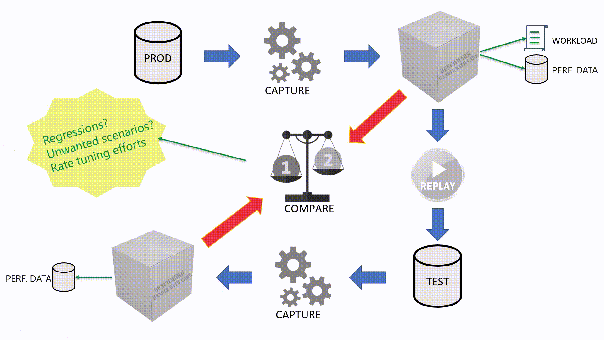
A big part of the complexity, let’s face it, comes from the fact that the tools that we have had in our toolbelt so far are complex and suffer from a number of limitations that make this exercise very similar to a hurdle race.
If you want to replay a workload from production to test, you need to be able to capture the workload first. Even before you start, you’re already confronted with a myriad of questions:
- What do you use for this? A server-side trace? Extended events? Profiler maybe?
- Which events do you capture? Which fields?
- How long do you need to run the capture? How much is enough? One hour? One day? One week? One month?
- Can you apply some filters?
- Will you have enough disk space to store the captured data?
Throughout the years, you’ve had multiple tools for capturing workloads, each with its own strengths and limitations:
- Profiler
- GOOD: extremely easy to use
- BAD: non-negligible impact on the server
- Extended Events
- GOOD: lightweight
- BAD: not compatible with older versions of SQLServer
- SQL Trace
- GOOD: less impactful than profiler
- BAD: deprecated
However, capturing the workload is not enough: you need to be able to replay it and analyze/compare the performance data.
But fear not! You have some tools that can help you here:
- RML Utilities
- SQL Nexus
- Distributed Replay
- Database Experimentation Assistant (DEA)
The bad news is that (again) each of these tools has its limitations and hurdles, even if the tin says that any monkey could do it. There is nothing like running ReadTrace.exe or Dreplay.exe against a huge set of trace files, only to have it fail after two hours, without a meaningful error message (true story). Moreover, of all these tools, only Distributed Replay (and DEA, which is built on top of it) support Azure SqlDatabase and Azure Managed instances: if you’re working with Azure, be prepared to forget everything you know about traces and RML Utilities.
Introducing WorkloadTools
Throughout my career, I had to go through the pain of benchmarking often enough to get fed up with all the existing tools and decide to code my own. The result of this endeavor is WorkloadTools: a collection of tools to collect, analyze and replay SQL Server workloads, on premises and in the cloud.
At the moment, the project includes 3 tools:
- SqlWorkload – a command line tool to capture, replay and analyze a workload
- ConvertWorkload – a command line tool to convert existing workloads (traces and extended events) to the format used by SqlWorkload
- WorkloadViewer – a GUI tool to visualize and analyze workload data
SqlWorkload is different from the traditional tools, because it lets you choose the technology for the capture: SqlTrace, Extended Events or a pre-recorded workload file. SqlWorkload also lets you choose the platform that you prefer: it works with older versions of SqlServer (tested from 2008 onwards, but nothing prevents it from running on SqlServer 2000) and newer versions, like 2017 or 2019. But the groundbreaking feature of SqlWorkload is its ability to work with Azure Sql Database Managed Instances and Azure Sql Database, by capturing Extended Events on Azure blob storage.
The capture is performed by a “Listener”, that reads the workload events from the source and forwards them immediately to a collection of “Consumers”, each specialized for performing a particular task on the events that it receives. You have a consumer for replaying the workload, a consumer for saving the workload to a file and a consumer for analyzing the workload to a database.
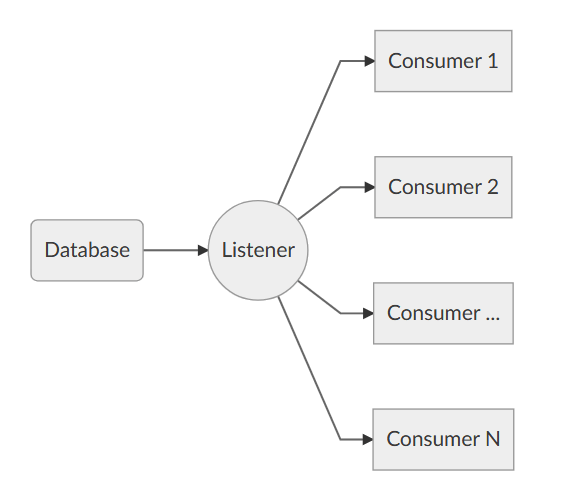
This flexible architecture allows you to do things differently from the existing tools. The traditional approach to benchmarking has always been:
- capture to one or more files
- analyze the files
- replay and capture
- analyze the files
- compare
SqlWorkload does not force you to save your workload to disk completely before you can start working with it, but it lets you forward the events to any type of consumer as soon as it is captured, thus enabling new types of workflows for your benchmarking activities. With SqlWorkload you are free to analyze the events while capturing, but you can also replay to a target database in real-time, while a second instance of SqlWorkload analyzes the events on the target.

If you’re used to a more traditional approach to benchmarking, you can certainly do things the usual way: you can capture a workload to a file, then use that file as a source for both the workload analysis and the replay. While replaying, you can capture the workload to a second set of files, that you can analyze to extract performance data. Another possibility is to analyze the workload directly while you capture it, writing to a workload file that you can use only for the replay.
As you can see, you have many possibilities and you are free to choose the solution that makes sense the most in your scenario. You may think that all this flexibility comes at the price of simplicity, but you’d be surprised by how easy it is to get started with WorkloadTools. SqlWorkload was designed to be as simple as possible, without having to learn and remember countless command line switches. Instead, it can be controlled by providing parameters in .JSON files, that can be saved, kept around and used as templates for the next benchmark.
For instance, the .JSON configuration file for “SqlWorkload A” in the picture above would look like this:
{
"Controller": {
"Listener":
{
"__type": "ExtendedEventsWorkloadListener",
"ConnectionInfo":
{
"ServerName": "SourceServer",
"DatabaseName": "SourceDatabase",
"UserName": "sa",
"Password": "P4$$w0rd!"
},
"DatabaseFilter": "SourceDatabase"
},
"Consumers":
[
{
"__type": "ReplayConsumer",
"ConnectionInfo":
{
"ServerName": "TargetServer",
"DatabaseName": "TargetDatabase",
"UserName": "sa",
"Password": "Pa$$w0rd!"
}
},
{
"__type": "AnalysisConsumer",
"ConnectionInfo":
{
"ServerName": "AnalysisServer",
"DatabaseName": "AnalysisDatabase",
"SchemaName": "baseline",
"UserName": "sa",
"Password": "P4$$w0rd!"
},
"UploadIntervalSeconds": 60
}
]
}
}
As you can see, SqlWorkload expects very basic information and does not need to set up complex traces or XE sessions: all you have to do is configure what type of Listener to use and its parameters, then you need to specify which Consumers to use and their parameters (mainly connection details and credentials) and SqlWorkload will take care of the rest.
If you need to do control the process in more detail, you can certainly do so: the full list of parameters that you can specify in .JSON files is available in the documentation of SqlWorkload at GitHub.
Once the capture is over and you completely persisted the workload analysis to a database, you can use WorkloadViewer to visualize it. WorkloadViewer will show you charts for Cpu, Duration and Batches/sec, comparing how the two benchmarks performed. You can also use the filters at the top to focus the analysis on a subset of the data or you can zoom and pan on the horizontal axis to select a portion of the workload to analyze.

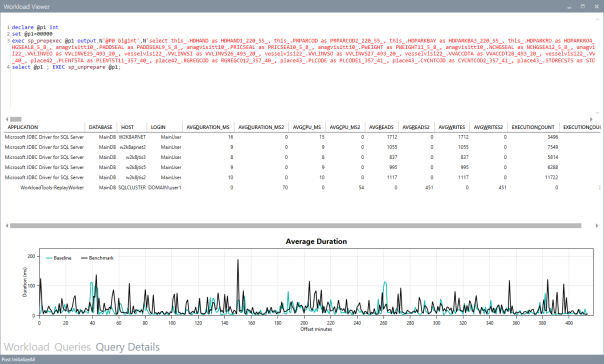
You can also use the “Queries” tab to see an overview of the individual batches captured in the workload. For each of those batches, you’ll be able to see the text of the queries and you will see stats for cpu, duration, reads, writes and number of executions. Sorting by any of these columns will let you spot immediately the regressions between the baseline and the benchmark and you will know exactly where to start tuning.

If you double click one of the queries, you will go to the Query Details tab, which will show you additional data about the selected query, along with its performance over time:
If WorkloadViewer is not enough for you, the project also includes a PowerBI dashboard that you can use to analyze the data from every angle. Does it look exciting enough? Wait, there’s more…
If you already have a pre-captured workload in any format (SqlTrace or Extended Events) you can use the command line tool ConvertWorkload to create a new workload file in the intermediate format used and understood by SqlWorkload (spoiler: it’s a SqLite database), in order to use it as the source for a WorkloadFileListener. This means that you can feed your existing trace data to the WorkloadTools analysis database, or replay it to a test database, even if the workload was not captured with WorkloadTools in the first place.
We have barely scratched the surface of what WorkloadTools can do: in the next weeks I will post detailed information on how to perform specific tasks with WorkloadTools, like capturing to a workload file or performing a real-time replay. In the meantime, you can read the documentation or you can join me at SqlBits, where I will introduce WorkloadTools during my session.
Stay tuned!
A bug in merge replication with FILESTREAM data
I wish I could say that every DBA has a love/hate relationship with Replication, but, let’s face it, it’s only hate. But it could get worse: it could be Merge Replication. Or even worse: Merge Replication with FILESTREAM.
What could possibly top all this hatred and despair if not a bug? Well, I happened to find one, that I will describe here.
The scenario
I published tables with FILESTREAM data before, but it seems like there is a particular planetary alignment that triggers an error during the execution of the snapshot agent.
This unlikely combination consists in a merge article with a FILESTREAM column and two UNIQUE indexes on the ROWGUIDCOL column. Yes, I know that generally it does not make sense to have two indexes on the same column, but this happened to be one of the cases where it did, so we had a CLUSTERED PRIMARY KEY on the uniqueidentifier column decorated with the ROWGUIDCOL attribute and, on top, one more NONCLUSTERED UNIQUE index on the same column, backed by a UNIQUE constraint.
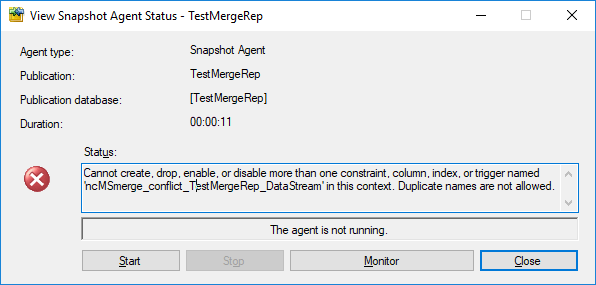
Setting up the publication does not throw any error, but generating the initial snapshot for the publication does:
Cannot create, drop, enable, or disable more than one constraint, column, index, or trigger named 'ncMSmerge_conflict_TestMergeRep_DataStream' in this context. Duplicate names are not allowed.
Basically, the snapshot agent is complaining about the uniqueness of the name of one of the indexes it is trying to create on the conflict table. The interesting fact about this bug is that it doesn’t appear when the table has no FILESTREAM column and it doesn’t appear when the table doesn’t have the redundant UNIQUE constraint on the ROWGUID column: both conditions need to be met.
The script
Here is the full script to reproduce the bug.
Before you run it, make sure that:
- FILESTREAM is enabled
- Distribution is configured
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| USE master; | |
| GO | |
| — | |
| — CLEANUP | |
| — | |
| IF DB_ID('TestMergeRep') IS NOT NULL | |
| BEGIN | |
| BEGIN TRY | |
| exec TestMergeRep.sys.sp_dropmergepublication @publication=N'TestMergeRep'; | |
| END TRY | |
| BEGIN CATCH | |
| PRINT 'sp_dropmergepublication failed' | |
| END CATCH | |
| BEGIN TRY | |
| exec TestMergeRep.sys.sp_removedbreplication 'TestMergeRep', 'merge'; | |
| END TRY | |
| BEGIN CATCH | |
| PRINT 'sp_removedbreplication failed' | |
| END CATCH | |
| BEGIN TRY | |
| exec TestMergeRep.sys.sp_replicationdboption @dbname = N'TestMergeRep', @optname = N'merge publish', @value = N'false'; | |
| END TRY | |
| BEGIN CATCH | |
| PRINT 'sp_replicationdboption failed' | |
| END CATCH | |
| ALTER DATABASE TestMergeRep SET SINGLE_USER WITH ROLLBACK IMMEDIATE; | |
| DROP DATABASE TestMergeRep; | |
| END | |
| GO | |
| — | |
| — CREATE DATABASE | |
| — | |
| CREATE DATABASE TestMergeRep; | |
| GO | |
| — WE NEED A FILESTREAM FILEGROUP | |
| DECLARE @path nvarchar(128), @sql nvarchar(max); | |
| SELECT @path = LEFT(physical_name, LEN(physical_name) – CHARINDEX('\', REVERSE(physical_name),1) + 1) | |
| FROM sys.database_files | |
| WHERE type = 0 | |
| ALTER DATABASE TestMergeRep | |
| ADD | |
| FILEGROUP [TestmergeRep_FileStream01] CONTAINS FILESTREAM; | |
| SET @sql = ' | |
| ALTER DATABASE TestMergeRep | |
| ADD | |
| FILE | |
| ( NAME = N''TestmergeRep_FS01'', FILENAME = ''' + @path + 'TestMergeRep_FS01'' , MAXSIZE = UNLIMITED) | |
| TO FILEGROUP [TestmergeRep_FileStream01]; | |
| ' | |
| EXEC(@sql) | |
| — | |
| — CREATE TABLE | |
| — | |
| USE TestMergeRep; | |
| GO | |
| SET ANSI_NULLS ON | |
| GO | |
| SET QUOTED_IDENTIFIER ON | |
| GO | |
| CREATE TABLE [dbo].[DataStream]( | |
| [DataStreamGUID] [uniqueidentifier] ROWGUIDCOL NOT NULL, | |
| [ValueData] [varbinary](max) FILESTREAM NOT NULL, | |
| CONSTRAINT [DataStream_DataStream_PK] PRIMARY KEY CLUSTERED | |
| ( | |
| [DataStreamGUID] ASC | |
| ) | |
| ) | |
| GO | |
| — I know it doesn't make sense, but the bug only shows | |
| — when the table has a second UNIQUE constraint on the PK column | |
| ALTER TABLE [DataStream] ADD CONSTRAINT UQ_MESL_DataStreamPK UNIQUE ([DataStreamGUID]); | |
| — WORKAROUND: create the UNIQUE index without creating the UNIQUE constraint: | |
| –CREATE UNIQUE NONCLUSTERED INDEX UQ_MESL_DataStreamPK ON [DataStream] ([DataStreamGUID]); | |
| — | |
| — SET UP REPLICATION | |
| — | |
| USE master | |
| EXEC sp_replicationdboption | |
| @dbname = N'TestMergeRep', | |
| @optname = N'merge publish', | |
| @value = N'true'; | |
| use [TestMergeRep] | |
| exec sp_addmergepublication | |
| @publication = N'TestMergeRep', | |
| @description = N'Merge publication of database TestMergeRep.', | |
| @retention = 30, | |
| @sync_mode = N'native', | |
| @allow_push = N'true', | |
| @allow_pull = N'true', | |
| @allow_anonymous = N'false', | |
| @enabled_for_internet = N'false', | |
| @conflict_logging = N'publisher', | |
| @dynamic_filters = N'false', | |
| @snapshot_in_defaultfolder = N'true', | |
| @compress_snapshot = N'false', | |
| @ftp_port = 21, | |
| @ftp_login = N'anonymous', | |
| @conflict_retention = 14, | |
| @keep_partition_changes = N'false', | |
| @allow_subscription_copy = N'false', | |
| @allow_synctoalternate = N'false', | |
| @add_to_active_directory = N'false', | |
| @max_concurrent_merge = 0, | |
| @max_concurrent_dynamic_snapshots = 0, | |
| @publication_compatibility_level = N'100RTM', | |
| @use_partition_groups = N'false'; | |
| exec sp_addpublication_snapshot | |
| @publication = N'TestMergeRep', | |
| @frequency_type = 1, | |
| @frequency_interval = 1, | |
| @frequency_relative_interval = 1, | |
| @frequency_recurrence_factor = 1, | |
| @frequency_subday = 1, | |
| @frequency_subday_interval = 5, | |
| @active_start_date = 0, | |
| @active_end_date = 0, | |
| @active_start_time_of_day = 10000, | |
| @active_end_time_of_day = 235959; | |
| exec sp_addmergearticle | |
| @publication = N'TestMergeRep', | |
| @article = N'DataStream', | |
| @source_owner = N'dbo', | |
| @source_object = N'DataStream', | |
| @type = N'table', | |
| @description = null, | |
| @column_tracking = N'true', | |
| @pre_creation_cmd = N'drop', | |
| @creation_script = null, | |
| @schema_option = 0x000000010C034FD1, | |
| @article_resolver = null, | |
| @subset_filterclause = N'', | |
| @vertical_partition = N'false', | |
| @destination_owner = N'dbo', | |
| @verify_resolver_signature = 0, | |
| @allow_interactive_resolver = N'false', | |
| @fast_multicol_updateproc = N'true', | |
| @check_permissions = 0, | |
| @identityrangemanagementoption = 'manual', | |
| @delete_tracking = N'true', | |
| @stream_blob_columns = N'false', | |
| @force_invalidate_snapshot = 1; | |
| — Sets all merge jobs owned by sa | |
| DECLARE @job_id uniqueidentifier | |
| DECLARE c CURSOR STATIC LOCAL FORWARD_ONLY READ_ONLY | |
| FOR | |
| SELECT job_id | |
| FROM msdb.dbo.sysjobs AS sj | |
| INNER JOIN msdb.dbo.syscategories AS sc | |
| ON sj.category_id = sc.category_id | |
| WHERE sc.name = 'REPL-Merge'; | |
| OPEN c | |
| FETCH NEXT FROM c INTO @job_id | |
| WHILE @@FETCH_STATUS = 0 | |
| BEGIN | |
| EXEC msdb.dbo.sp_update_job @job_id=@job_id , @owner_login_name=N'sa' | |
| FETCH NEXT FROM c INTO @job_id | |
| END | |
| CLOSE c | |
| DEALLOCATE c |
After running the script, start the snapshot agent and you’ll see the error appearing:
Workaround
One way to get rid of the bug is to enforce the uniqueness of the data by using a UNIQUE index instead of a UNIQUE constraint:
CREATE UNIQUE NONCLUSTERED INDEX UQ_MESL_DataStreamPK ON [DataStream] ([DataStreamGUID]);
With this index, the snapshot agent completes correctly. Please note that the index would have been UNIQUE anyway, because its key is a superset of the primary key.
Hope this helps!
Please Vote!
This bug has been filed on UserVoice and can be found here: https://feedback.azure.com/forums/908035-sql-server/suggestions/34735489-bug-in-merge-replication-snapshot-agent-with-files
Please upvote it!
Recovering the PsGallery Repository behind a Corporate Proxy
While getting a new workstation is usually nice, reinstalling all your softwares and settings is definitely not the most pleasant thing that comes to my mind. One of the factors that can contribute the most to making the process even less pleasant is working around the corporate proxy.
Many applications live on the assumption that nobody uses proxy servers, thus making online repositories inaccessible for new installations and for automatic updates.
Unfortunately, PsGallery is no exception.
If you run Get-PSRepository on a vanilla installation of Windows 10 behind a corporate proxy, you will get a warning message:
WARNING: Unable to find module repositories.
After unleashing my Google-Fu, I learned that I had to run the following command to recover the missing PsRepository:
Register-PSRepository -Default -Verbose
The command works without complaining, with just a warning suggesting that something might have gone wrong:
VERBOSE: Performing the operation "Register Module Repository." on target "Module Repository 'PSGallery' () in provider 'PowerShellGet'.".
Again, running Get-PSRepository returns an empty result set and the usual warning:
WARNING: Unable to find module repositories.
The problem here is that the cmdlet Register-PsRepository assumes that you can connect directly to the internet, without using a proxy, so it tries to do so, fails to connect and does not throw a meaningful error messsage. Thank you, Register-PsRepository, much appreciated!
In order to fix it, you need to configure your default proxy settings in your powershell profile. Start powershell and run the following:
notepad $PROFILE
This will start notepad and open your powershell profile. If the file doesn’t exist, Notepad will prompt you to create it.
Add these lines to the profile script:
[system.net.webrequest]::defaultwebproxy = new-object system.net.webproxy('http://YourProxyHostNameGoesHere:ProxyPortGoesHere')
[system.net.webrequest]::defaultwebproxy.credentials = [System.Net.CredentialCache]::DefaultNetworkCredentials
[system.net.webrequest]::defaultwebproxy.BypassProxyOnLocal = $true
Save, close and restart powershell (or execute the profile script with iex $PROFILE).
Now, you can register the default PsRepository with this command:
Register-PSRepository -Default
If you query the registered repositories, you will now see the default PsRepository:
Get-PSRepository Name InstallationPolicy SourceLocation ---- ------------------ -------------- PSGallery Untrusted https://www.powershellgallery.com/api/v2/
Horray!
How To Enlarge Your Columns With No Downtime
Let’s face it: column enlargement is a very sensitive topic. I get thousands of emails every month on this particular topic, although most of them end up in my spam folder. Go figure…
The inconvenient truth is that enlarging a fixed size column is a long and painful operation, that will make you wish there was a magic lotion or pill to use on your column to enlarge it on the spot.

Unfortunately, there is no such magic pill, but turns out you can use some SQL Server features to make the column enlargement less painful for your users.
First, let’s create a table with one smallint column, that we will try to enlarge later.
-- Go to a safe place
USE tempdb;
GO
IF OBJECT_ID('EnlargeTest') IS NOT NULL
DROP TABLE EnlargeTest;
-- Create test table
CREATE TABLE EnlargeTest (
SomeColumn smallint
);
-- Insert 1 million rows
INSERT INTO EnlargeTest (SomeColumn)
SELECT TOP(1000000) 1
FROM master.dbo.spt_values AS A
CROSS JOIN master.dbo.spt_values AS B;
If you try to enlarge this column with a straight “ALTER TABLE” command, you will have to wait for SQLServer to go through all the rows and write the new data type. Smallint is a data type that is stored in 2 bytes, while int requires 4 bytes, so SQL Server will have to enlarge each and every row to accommodate 2 extra bytes.
This operation requires some time and also causes a lot of page splits, especially if the pages are completely full.
SET STATISTICS IO, TIME ON; -- Enlarge column ALTER TABLE EnlargeTest ALTER COLUMN SomeColumn int; SET STATISTICS IO, TIME OFF; /* (1000000 rows affected) SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. Table 'EnlargeTest'. Scan count 9, logical reads 3001171, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 8, logical reads 2064041, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 13094 ms, elapsed time = 11012 ms. */
The worst part of this approach is that, while the ALTER TABLE statement is running, nobody can access the table.
To overcome this inconvenience, there is a magic column enlargement pill that your table can take, and it’s called Row Compression.
Row compression pills. They used to be expensive, SQL Server 2016 SP1 made them cheap.
Let’s try and revert to the original column size and take the Row Compression pill:
-- Let's revert to smallint ALTER TABLE EnlargeTest ALTER COLUMN SomeColumn smallint; -- Add row compression ALTER TABLE EnlargeTest REBUILD WITH (DATA_COMPRESSION = ROW);
With Row Compression, your fixed size columns can use only the space needed by the smallest data type where the actual data fits. This means that for an int column that contains only smallint data, the actual space usage inside the row is 1 or 2 bytes, not 4.
This is exactly what you need here:
SET STATISTICS IO, TIME ON; -- Let's try to enlarge the column again ALTER TABLE EnlargeTest ALTER COLUMN SomeColumn int; SET STATISTICS IO, TIME OFF; /* SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. */
Excellent! This time the command completes instantly and the ALTER COLUMN statement is a metadata only change.
The good news is that Row Compression is available in all editions of SQL Server since version 2016 SP1 and compression can be applied by rebuilding indexes ONLINE, with no downtime (yes, you will need Enteprise Edition for this).
The (relatively) bad news is that I tested this method on several versions of SQL Server and it only works on 2016 and above. Previous versions are not smart enough to take the compression options into account when enlarging the columns and they first enlarge and then reduce the columns when executing the ALTER COLUMN command. Another downside to this method is that row compression will refuse to work if the total size of your columns exceeds 8060 bytes, as the documentation states.
Bottom line is: painless column enlargement is possible, if you take the Row Compression pills. Just don’t overdo it: you don’t want to enlarge your columns too much, do you?
Introducing XESmartTarget
Three years ago, I started to work on a project called ExtendedTsqlCollector. I blogged about it multiple times here on spaghettidba.com.
Even if I received positive feedback, I knew that one aspect was slowing down the adoption of the project: the Data Collector. That particular feature of SQL Server has a very bad reputation for being difficult to set up, customize and monitor. ExtendedTSQLCollector tried to address some of those issues, but the damage was already done and I knew that the Data Collector was already on the verge of extinction.
So, how could I preserve the work done for that project and, at the same time, offer DBAs the ability to set up complex actions in response to events? What I aimed to release was a tool capable of streaming events from a session and perform configurable actions in response to those events, mainly writing to a database table and sending alerts. The tool I had in mind should have to be configured in a simple and straightforward way, possibly with a single configuration file.
So, back to the drawing board. The tool I came up with had ditched the data collector, but it kept as much as possible from the previous project.
Introducing XESmartTarget
I am proud to introduce XESmartTarget: the easiest way to interact with extended events sessions without writing a single line of code.
XESmartTarget uses the Extended Events streaming API to connect to a session and execute some actions in response to each event. The actions you perform can be configured in a simple .json file, which controls the Response types and all their properties.
For instance, if you have a session to capture deadlocks, you may want to be notified whenever such an event is captured. All you need to do is configure XESmartTarget to send an email using the EmailResponse class. You can do that by creating a simple .json file with all the parameters needed:
| { | |
| "Target": { | |
| "ServerName": "(local)\\SQL2014", | |
| "SessionName": "deadlocks", | |
| "FailOnProcessingError": false, | |
| "Responses": [ | |
| { | |
| "__type": "EmailResponse", | |
| "SMTPServer": "localhost", | |
| "Sender": "from@test.com", | |
| "To": "dba@localhost.localdomain", | |
| "Subject": "Deadlock occurred", | |
| "Body": "Deadlock occurred at {collection_time}", | |
| "Attachment": "xml_report", | |
| "AttachmentFileName": "deadlock.xdl", | |
| "HTMLFormat": true, | |
| "Events": [ | |
| "xml_deadlock_report" | |
| ] | |
| } | |
| ] | |
| } | |
| } |
XESmartTarget will connect to your session and will execute an EmailResponse for every event you capture. What will you see? Not much, because XESmartTarget is a console application that you are supposed to run in the background:
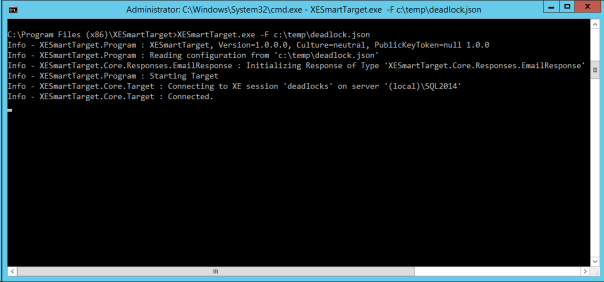
What you will actually see is email messages flowing to your inbox:
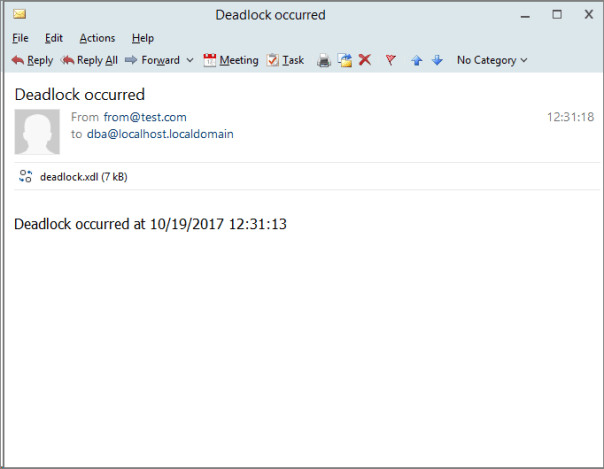
This is just an example of what XESmartTarget can do: you already have Response types to write events to a database table or replay execution-related events to a target instance. More Response types are in the works as well, but the good news is that XESmartTarget is open source, so you can code your own ad contribute it to the project on GitHub.
What are you waiting for? Download and try XESmartTarget now!
Expensive Enterprise Backup Tools – A survival guide
If you’re working for a big company, chances are that your IT already has a strategy and tools for dealing with backups. Many objects need to backed up (files, emails, virtual machines, databases…) and vendors are happy to provide software solutions for all those needs.
Usually, the first type of object that has to be protected is files: every company, even the smaller ones, have file servers with lots of data that has to be regularly backed up, so the data protection solution found in the majority of companies is typically built around the capabilities and features of backup tools designed and engineered for protecting the file system.
The same tools are probably capable of taking backups of different types of objects, by means of “plug-ins” or “agents” for databases, e-mail servers, virtual machines and so on. Unfortunately, those agents are often delusional and fail to deliver what they promise.
With regard to SQL Server database backups, these are the most common issues:
1. Naming things wrong
It’s not surprising that backup tools built for protecting the file system fail to name things properly when it comes down to database backups. What you often find is that transaction log backups are called “incremental backups” or full backups are instead called “snapshots”, according to whichever the naming convention is in the main file system backup process. It’s also not uncommon to find transaction log backups going under the name of “archive log backups”, because this is what they are called like in Oracle. This naming mismatch is potentially dangerous, because it can trick the DBA into choosing the wrong type of backup. The term “DBA” is not used here by accident, which takes us to the next point.
2. Potentially dangerous separation of duties
Backup tools are often run and controlled by windows admins, who may or may not be the same persons responsible for taking care of databases. Well, surprise: if you’re taking backups you’re responsible for them, and backups are the main task of the DBA, so… congrats: you’re the DBA now, like it or not.
If your windows admins are not ok with being the DBA, but at the same time are ok with taking backups, make sure that you discuss who gets accountable for data loss when thing go south. Don’t get fooled: you must not be responsible for restores (which, ultimately, is the reason why you take backups) if you don’t have control over the backup process. Period.
3. One size fits all

Some backup tools won’t allow you to back up individual databases with special schedules and policies, but will try to protect the whole instance as an atomic object, with a “one size fits all” approach. Be careful not to trade safety for simplicity.
4. Missing backup / restore options
Most (if not all) third-party backup tools do not offer the same flexibility that you have with native backups, so you will probably miss some of the backup/restore options. I’m not talking about overly exotic options such as KEEP_REPLICATION or NEW_BROKER: in some cases you may not be able to restore with NORECOVERY. Whether this is going to be a problem or not, only you can tell: go and check the possibilities of your data protection tool, because you might need a feature that is unavailable and you might need it when it’s too late.
5. Dangerous internal workings
Not all backup tools behind the covers are acting as you would expect. For instance, Microsoft Data Protection Manager (DPM) is unable to take transaction log backups streaming them directly to the backup server, but needs to write the backup set to a file first. I bet you can see what’s wrong with this idea: if your transaction log is growing due to an unexpected spike in activity, the only way to stop if from growing and eventually fill the disk is to take a t-log backup, but the backup itself will have to be written to disk. In the worst case, you won’t have enough disk space to perform the backup, so it will simply fail. In a similarly catastrophic scenario, the transaction log file may try to grow again while the log backup is being taken, resulting in failure to allocate disk space.It is incredibly ironic how you need disk space to perform a backup and you need a backup to release disk space, so I am just going to guess that the developers of DPM were simply trying to be funny when they designed this mechanism.
6. Incoherent schedules
Some backup tools are unable to provide a precise schedule and instead of running the backup operation when due, they add it to a queue that will eventually run everything. This may look like a trivial difference, but it is not: if your RPO is, let’s say, 15 minutes, transaction log backups have to occur every 15 minutes at most, so having transaction log backups executed from a queue would probably mean that some of them will exceed the RPO if at least one of the backups takes longer than usual. Detecting this condition is fairly simple: you just have to look at your backupset table in msdb.
7. Sysadmin privileges
All third-party backup applications rely on an API in SQL Server which is called “Virtual Device Interface” (or VDI in short). This API allows SQL Server to treat backup sessions from your data protection tool as devices, and perform backup/restore operations by using these devices as source/destination.
One of the downsides of VDI is that it requires sysadmin privileges on the SQL Server instance and Administrator privileges on the Windows box. In case you’re wondering, no: it’s not strictly necessary to have sysadmin privileges to back up a database.
8. VSS backups
A number of backup tools rely on taking VSS snapshots of the SQL Server databases. SQL Server supports VSS snapshots and has a provider for that. Unfortunately, it’s not impossible to see VSS backups interfering with other types of backups and/or failures initializing the VSS provider, which require a reboot to fix.
9. VM backups
Some backup vendors are more focused on backing up the whole virtual machine rather than the single database / instance that you want to protect. Taking a whole machine backup is different and you have to make sure that you understand what that means, especially compared to taking full, diff or log backups. For instance, did you know that taking VM backups is based on the snapshot feature of the hypervisor, which in turn runs VSS backups of snapshot-aware software, like SQL Server?
10. Interfere with other features
Oftentimes, these enterprise-grade super-expensive backup tools live on the assumption that they’re the only one tool you will ever use, and refuse to play nicely with other SQL Server features. For instance, they will happily try to back up transaction log for databases that are part of log shipping (see point #3), ending up with broken log chains.
11. Agents
All backup tools that take advantage of the VDI API require that you install an agent application locally on the SQL Server machine. While having an agent running on the windows machine is not overly concerning per se, on the other hand this means that the agent itself will have to be patched and upgraded from time to time, often requiring that you restart the machine to apply changes.
This also means that you might run into bugs in the agent that could prevent taking backups until you patch/upgrade the agent itself.
12. Illogical choices
Some data protection tools will force illogical policies and schedules on you for no reason whatsoever. For instance, EMC Networker cannot take transaction log backups of master and model (which must/should be in simple recovery anyway), so when you schedule transaction log backups for all databases on the instance, it won’t skip them, but take a full backup instead. Both databases are usually quite small, but still, taking a full backup every 15 or 5 minutes is less than ideal.
13. Not designed with availability in mind
Backing up the file system is very different from backing up SQL Server databases, as one might expect. One of the key differences is that with SQL Server databases you don’t have to deal with RPO and RTO only, but the way that you back up your databases can have a serious impact on the availability of the databases itself. To put that simply: if you don’t take transaction log backups, nothing truncates your logs, so it keeps growing and growing until space runs out either on the log file (and the database stops working) or on the disk (and the whole instance stops working). Backup operations are critical for RDBMSs: if something or somebody commits to performing backups every x minutes, that commitment MUST be fulfilled. For the record, many backup tools that offer the “one size fits all” approach will try to take full and transaction logs on the same schedule, so they will simply skip transaction log backups while taking full backups. This means that you might be exceeding your RPO, with no clear indication of that happening.
14. No support for SQL Server compression or encryption
A number of backup tools offer their own compression and encryption features (again, because the file system does not offer those), so they will try in each and every possible way to push their shiny-enterprise-expensive features instead of what you already have.
Compression helps keeping the backup and restore times under control, by keeping the size of the backup sets small: this means that the number of bytes that travels across the network will be smaller. Nowadays, the majority of backup solutions supports Data Domain or equivalent solutions: smart storage appliances that offer powerful compression and deduplication features to avoid storing the same information multiple times. These dedupe features can be incredibly effective and reduce immensely the amount of disk space needed for storing backups. Some data domains offer deduplication inside the appliance itself: data has to travel the network and reach the data domain, which takes care of breaking the file in blocks, calculate a hash on the blocks and store only the blocks whose hash was not found inside the data domain. This behavior is already clever enough, but some data domains improved it even further, with host deduplication (DDBoost, to name the most prominent product). Basically, what happens with host deduplication is that the hash of the blocks is calculated on the host and not on the data domain: in this way, all the duplicate blocks do not need to travel across the network, hence reducing the amount of time needed for backup operations.
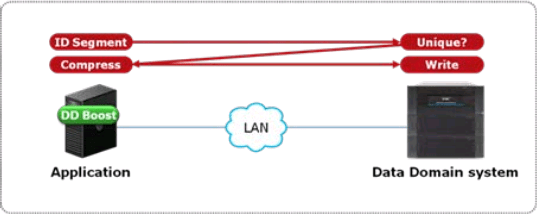
These dedupe technologies are incredibly useful and also allow backup admins to show to their boss all those shiny charts that depict how cleverly the data domain is reducing disk usage across the board. This is going to be so amazing that the backup admin will not allow you to deteriorate his exceptional dedupe stats by using any backup option that prevents deduplication from happening. The two main enemies of Data Domain efficiency are compression and encryption in the source data. Compression of similar uncompressed files does not produce similar compressed files, so chances of deduplication are much slimmer. Encryption of backups is non-deterministic, which means that two backup sets of the same exact database will be completely different, bringing down deduplication rates close to zero.
While the need for encryption is probably something that your backup admins could live with, they will try in every possible way to make you get rid of backup compression. Letting the data domain take care of compression and deduplication can be acceptable in many cases, but it must not be a hard rule, because of its possible impact on RTO.
The real issue with deduplication can be dramatically evident at restore time: the advantage of deduplication will be lost, because all the blocks that make up your backups will have to travel across the network.
Long story short: at backup time, deduplication can be extremely effective, but, at restore time, backup compression can be much more desirable and can make the difference between meeting and not meeting your RTO.
15. No separation of duties
What often happens with general-purpose backup tools is that management of a single object type is not possible. A number of tools will allow you to be a backup admin on the whole infrastructure or nothing, without the ability to manage database backups only. This may or may not be a problem, depending on how dangerous your windows admins consider your ability to manage the backup schedules of Exchange servers and file servers.
Some tools offer the possibility to create separate tenants and assign resources and schedules to particular tenants, each with its own set of administrators. This feature often comes with limitations, such as the inability to share resources throughout multiple tenants: if tape drives can be assigned to a single tenant and the company only owns a single tape drive, this option obviously goes out of the table.
16. No management tools
Often, the management tools offered by these backup vendors are simply ridiculous. Some use web applications with java applets or similar outdated/insecure technologies. Some offer command line tools but no GUI tools, some the other way around. The main takeaway is: make sure that your backup vendor gives you the tools that you need, which must include a command line or anything that can be automated.
17. Ridiculous RPO/RTO
The developers of some backup tools (DPM, I’m looking at you) decided that forcing a minimum schedule frequency of 15 minutes was a great idea. Well, in case you’re wondering, it’s not.
Other tools manage the internal metadata so dreadfully that loading the list of available backup sets can take forever, hence making restores excruciating exercises, that often fall outside of the requested RTO.
Make sure that tool you are using is able to deliver the RPO and RTO you agreed upon with the owners of the data.
Bottom line is: don’t let your backup vendor impose the policies for backups and restores. Your stakeholders are the owners of the data and everyone else is not entitled to dictate RPOs and RTOs. Make sure that your backup admins understand that your primary task is to perform restores (not backups!) and that the tool they are using with Exchange might not be the best choice for you. Talk to your backup admins, find the best solution together and test it across the board, with or without the use of third party tools, because, yes, native SQL Server backups can be the best choice for you.
Using Virtual Desktops for Presentations
Today I was reading William Durkin‘s fine post on Presentation Mode in SSMS vNext when inspiration struck.
One of the things that really annoys me when presenting is the transition between slides and demos. Usually, I try to improve the process as much as possible by having the least minimum amount of windows open while presenting, so that I don’t land on the wrong window. Unfortunately, that is not always easy.
Another thing that I would like to be smoother is the transition itself. The ideal process should be:
- Leave the powerpoint slides open at full screen
- Switch immediately to the virtual machine with the demos
- Go back to the slides, to the exact point where I left
What I usually do is show the desktop with the WIN+D hotkey, then activate the Virtualbox window with my demos, but this shows my desktop for a moment and I don’t really like this extra transition.
I could also use ALT+Tab to switch to the Virtualbox window, but this would briefly show the list of running applications, which is not exactly what I want.
Turns out that Windows 10 has the perfect solution built-in: Virtual Desktops.
Here is the setup described:
- If you press WIN+Tab, you will see a “New desktop” button on the bottom right corner. Use it to create three desktops:
- desktop 3 for the slides
- desktop 2 for the demos
- desktop 1 for the rest
- Press WIN+Tab, find your virtual machine and move it to desktop 2. It is really easy: you just have right click the window you want to send to a different desktop and select which desktop to use.

- Open your presentation and start it by pressing F5. Again, hit WIN+Tab, find the fullscreen window of your PowerPoint presentation and move it to desktop 3.
- In order to transition from one desktop to another, you can use the hotkey CTRL+WIN+Arrow, as shown in this GIF:

Here it is! Perfectly smooth, a nice transition animation and nothing but your slides and your demos shown to the attendees.
Installing SQL Server 2016 Language Reference Help from disk
A couple of years ago I blogged about Installing the SQL Server 2014 Language Reference Help from disk.
With SQL Server 2016 things changed significantly: we have the new Help Viewer 2.2, which is shipped with the Management Studio setup kit.
However, despite all the changes in the way help works and is shipped, I am still unable to download and install help content from the web, so I resorted to using the same trick that I used for SQL Server 2014.
This time the URLs and the files to download are different:
- Point your browser to http://services.mtps.microsoft.com/ServiceAPI/catalogs/sql2016/en-us
- Download the Language Reference Files:
If you’re a PowerShell person, these three lines will do:
Invoke-WebRequest -Uri "http://packages.mtps.microsoft.com/sql_2016_branding_en-us(1bd6e667-f159-ac3b-f0a5-964c04ca5a13).cab" ` -OutFile "sql_2016_branding_en-us(1bd6e667-f159-ac3b-f0a5-964c04ca5a13).cab" Invoke-WebRequest -Uri "http://packages.mtps.microsoft.com/v2sql_shared_language_reference_b4621_sql_130_en-us_1(83748a56-8810-751f-d453-00c5accc862d).cab" ` -OutFile "v2sql_shared_language_reference_b4621_sql_130_en-us_1(83748a56-8810-751f-d453-00c5accc862d).cab" Invoke-WebRequest -Uri "http://packages.mtps.microsoft.com/v2sql_shared_language_reference_b4621_sql_130_en-us_2(ccc38276-b744-93bd-9008-fe79b294ff41).cab" ` -OutFile "v2sql_shared_language_reference_b4621_sql_130_en-us_2(ccc38276-b744-93bd-9008-fe79b294ff41).cab"
- Create a text file name HelpContentSetup.msha in the same folder as the .cab files and paste the following html:
<html xmlns="http://www.w3.org/1999/xhtml">
<head />
<body class="vendor-book">
<div class="details">
<span class="vendor">Microsoft</span>
<span class="locale">en-us</span>
<span class="product">SQL Server 2016</span>
<span class="name">Microsoft SQL Server Language Reference</span>
</div>
<div class="package-list">
<div class="package">
<span class="name">SQL_2016_Branding_en-US</span>
<span class="deployed">False</span>
<a class="current-link" href="sql_2016_branding_en-us(1bd6e667-f159-ac3b-f0a5-964c04ca5a13).cab">sql_2016_branding_en-us(1bd6e667-f159-ac3b-f0a5-964c04ca5a13).cab</a>
</div>
<div class="package">
<span class="name">v2SQL_Shared_Language_Reference_B4621_SQL_130_en-us_1</span>
<span class="deployed">False</span>
<a class="current-link" href="v2sql_shared_language_reference_b4621_sql_130_en-us_1(83748a56-8810-751f-d453-00c5accc862d).cab">v2sql_shared_language_reference_b4621_sql_130_en-us_1(83748a56-8810-751f-d453-00c5accc862d).cab</a>
</div>
<div class="package">
<span class="name">v2SQL_Shared_Language_Reference_B4621_SQL_130_en-us_2</span>
<span class="deployed">False</span>
<a class="current-link" href="v2sql_shared_language_reference_b4621_sql_130_en-us_2(ccc38276-b744-93bd-9008-fe79b294ff41).cab">v2sql_shared_language_reference_b4621_sql_130_en-us_2(ccc38276-b744-93bd-9008-fe79b294ff41).cab</a>
</div>
</div>
</body>
</html>
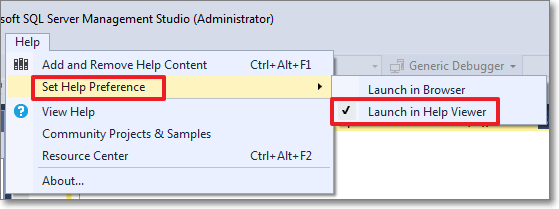
- First, set the Help Viewer to open help from the local sources:
- Then select the “Add and Remove Help Content” command:
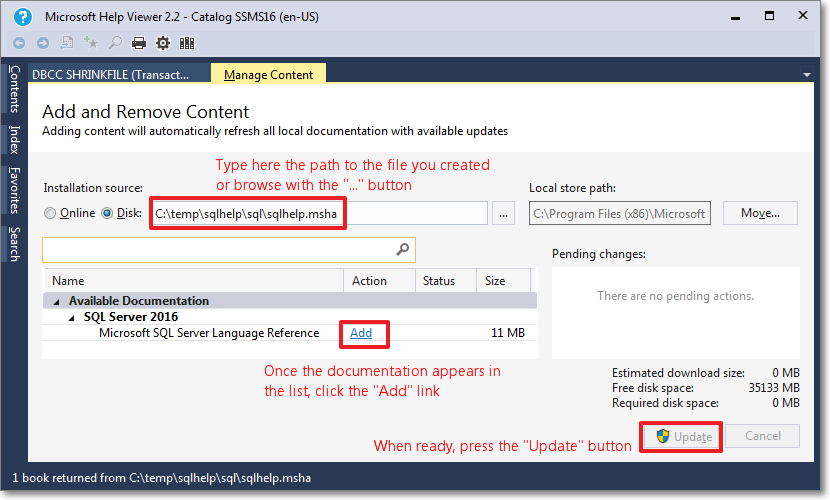
- This command opens the Help Viewer and asks for the content to add.
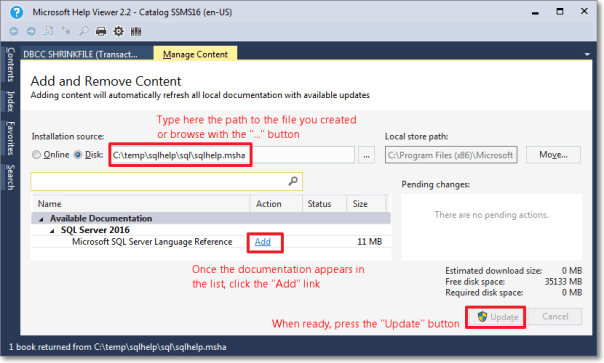
Browse to the file you created in step 3.
Click “Add” on all the items you wish to add to the library. In this case you will have only 1 item.
When done, click the “Update” button.
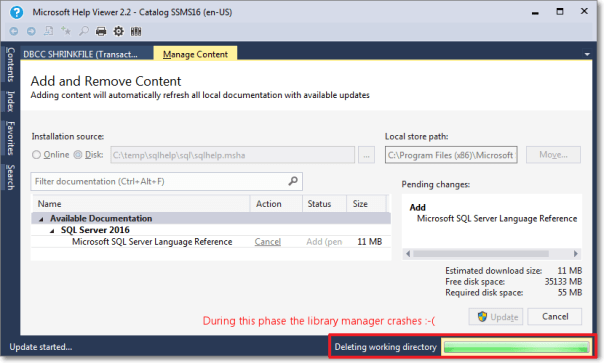
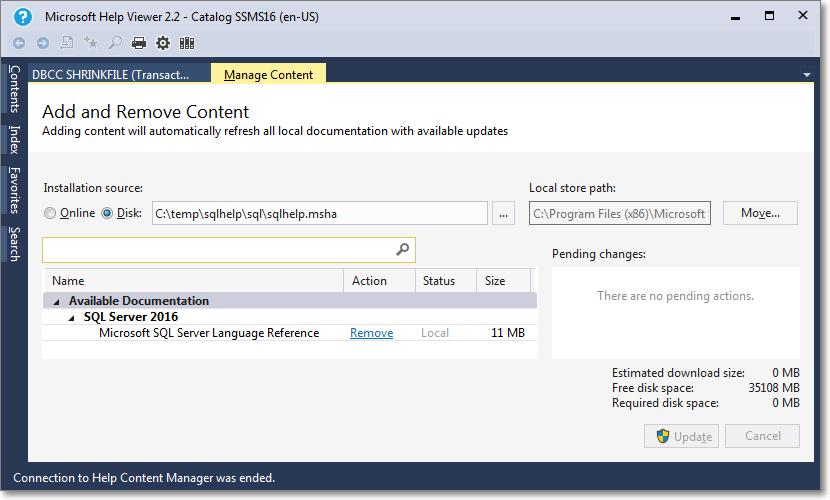
- Unfortunately, during the installation phase of the library item, something crashes and the installation won’t proceed until you tell it to ignore or report the error.
- Despite the crash, everything works as expected and you will find the topic installed in your help library:
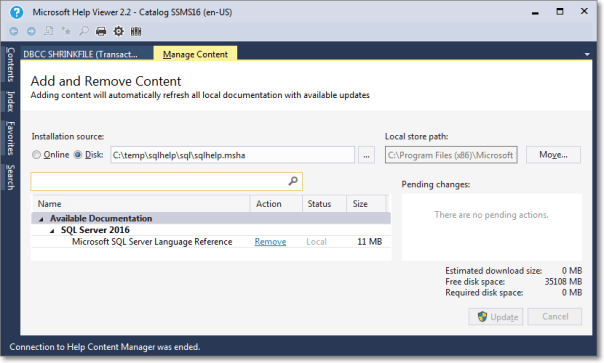

Here it is, nice and easy. Hope it works for you too.
ForumSurfer – a RSS reader for the SQL Server online community
Today I published the first release of ForumSurfer, a RSS reader designed explicitly to be a tool for the SQL Server online community.
Here is a screenshot:

ForumSurfer has some unique features that will help you help others online:
- it is designed to help you keep an eye on multiple communities through their RSS feeds
- it opens questions in the integrated web browser
- it can update from the feeds much more often than online RSS readers do
- it has built-in support for boilerplate answers
- it supports high-DPI displays, letting you choose the appropriate zoom level for individual sites
- it can import/export OPML files (you can start by importing the OPML file containing all the online SQL Server communities I’m keeping on the radar)
What are you waiting for? Download now the latest release of ForumSurfer and start being helpful!
Did you find any issues? Report them or ping me on Twitter!
SSMS is now High-DPI ready
One of the most popular posts on this bog describes how to enable bitmap scaling is SSMS on high DPI displays, which is a sign that more and more people are starting to use 4K displays and are unhappy with SSMS’s behaviour at high DPI. The solution described in that post is to enable bitmap scaling, which renders graphic objects correctly, at the price of some blurriness.
The good news is that starting with SSMS 16.3 high DPI displays are finally first class citizens and SSMS does its best to scale objects properly. By default, SSMS will keep using bitmap scaling: in order to enable DPI scaling you will have to use a manifest file.
- Merge this key to your registry:
Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\SideBySide] "PreferExternalManifest"=dword:00000001
- Save this manifest file to “C:\Program Files (x86)\Microsoft SQL Server\130\Tools\Binn\ManagementStudio\Ssms.exe.manifest” using UTF-8 format:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<assembly xmlns="urn:schemas-microsoft-com:asm.v1" manifestVersion="1.0" xmlns:asmv3="urn:schemas-microsoft-com:asm.v3">
<asmv3:application>
<asmv3:windowsSettings xmlns="http://schemas.microsoft.com/SMI/2005/WindowsSettings">
<dpiAware>True</dpiAware>
</asmv3:windowsSettings>
</asmv3:application>
<dependency>
<dependentAssembly>
<assemblyIdentity type="win32" name="Microsoft.Windows.Common-Controls" version="6.0.0.0" processorArchitecture="X86" publicKeyToken="6595b64144ccf1df" language="*" />
</dependentAssembly>
</dependency>
<dependency>
<dependentAssembly>
<assemblyIdentity type="win32" name="debuggerproxy.dll" processorArchitecture="X86" version="1.0.0.0"></assemblyIdentity>
</dependentAssembly>
</dependency>
</assembly>
This is a huge improvement over the bitmap scaling solution we had to use up to now: no more blurriness and proper fonts are used in SSMS.
For comparison, this is how bitmap scaling renders in SSMS 2014:

And this is how DPI scaling renders is SSMS 16.3, with scaling set to 200%:

As you can see, it’s not perfect yet (for instance, I had to change the grid font size to 9pt. in order to have readable fonts).
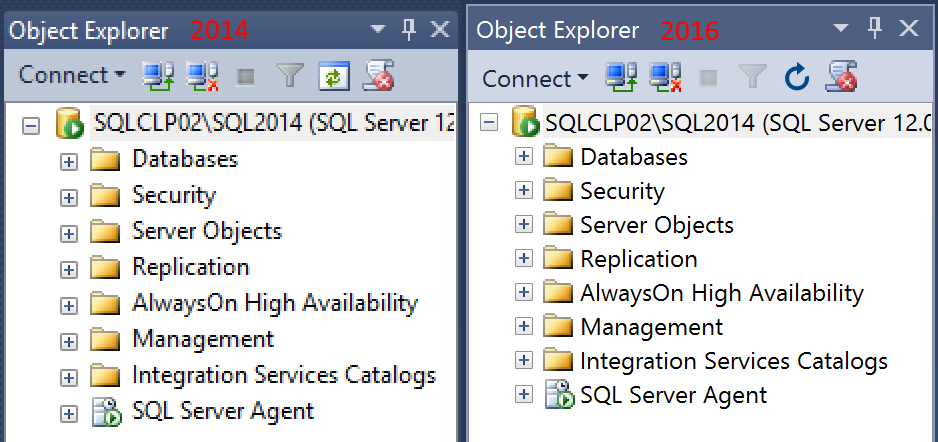
However, the GUI is much more readable now. For instance, look at the difference in object explorer: (click on the image to open fullsize and see the difference)
Now that your favourite tool is working in high DPI displays, nothing is holding you back from buying one of those fancy 4K laptops!
